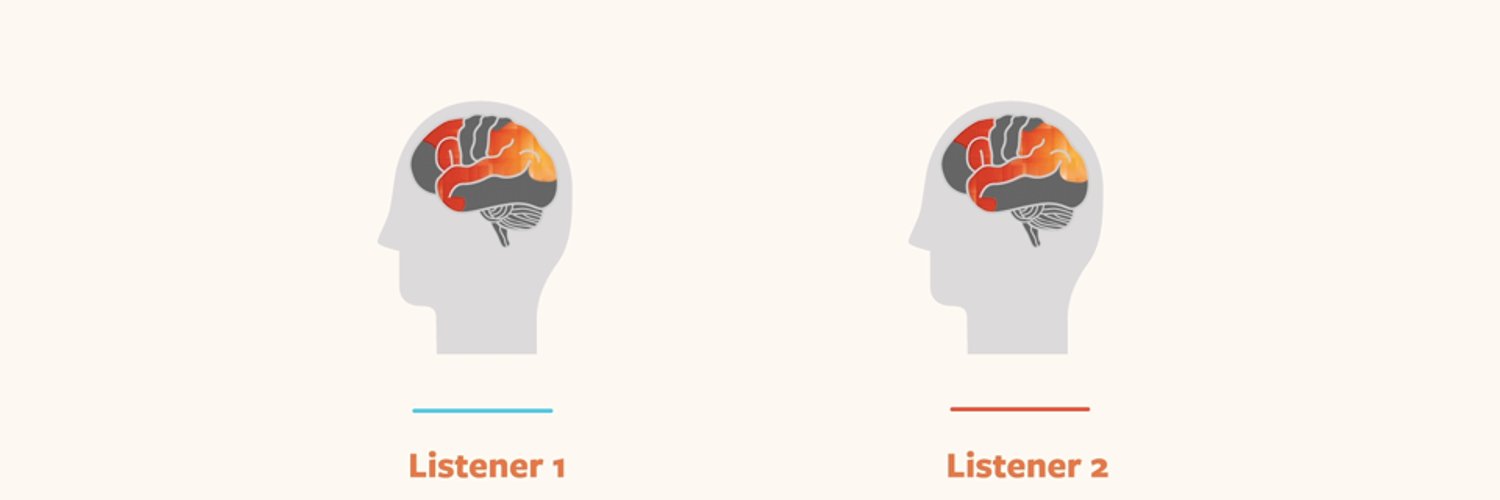
In summary, by leveraging naturalistic neural recordings and LLMs, this study identifies a previously unrecognized information-making process in the speaker’s brain. We would like to thank our co-authors: Haocheng Wang, @TomSheffer17807, @DariaLioub, @SchainMariano@HassonLab 🙏
@HRaviv830 Deeply grateful to our partners, collaborators, and the families who made this possible. We'd love to hear your thoughts. Preprint: https://t.co/CE8DzSkueP
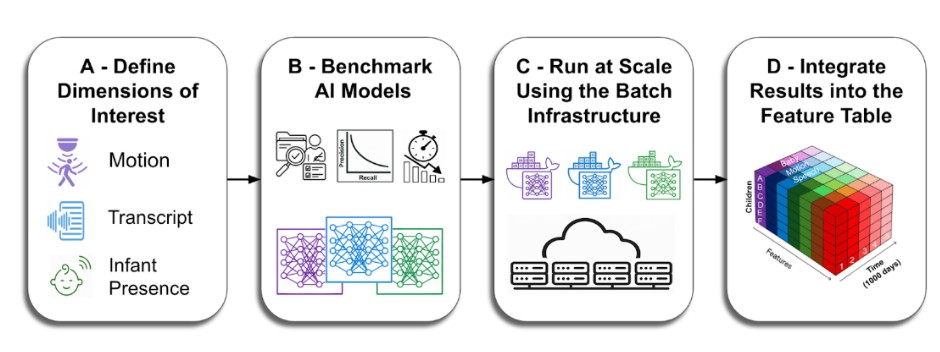
If you saw our modeling paper, this is the infrastructure behind it. New preprint from the First 1,000 Days (1kD) Project. It took 5 years to build what this paper describes. Worth it.
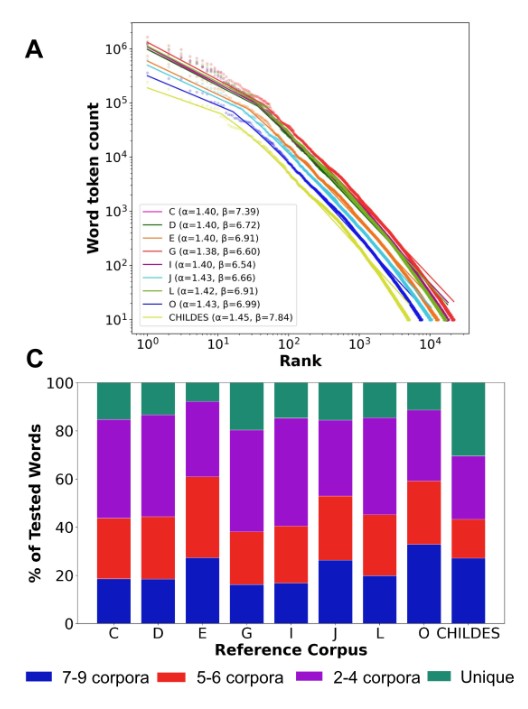
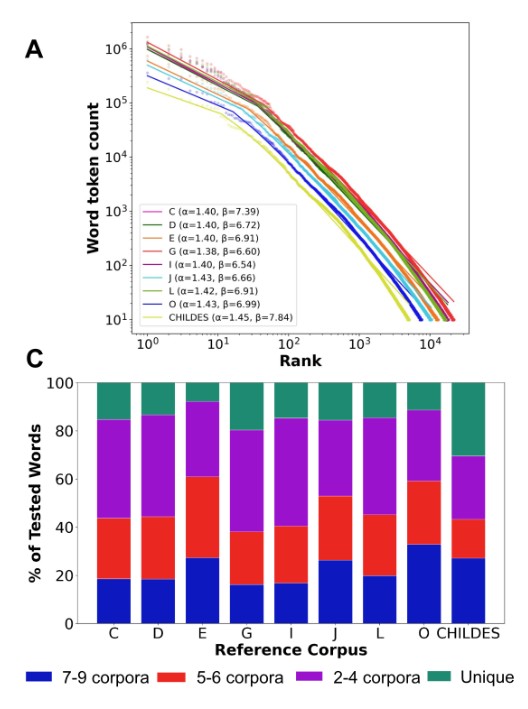
@HRaviv830 Dense measurement doesn't just give you more data. It tells you what's universal, what's household-specific, and when aggregation obscures more than it reveals.
@HRaviv830 There is no “average family”. Every home has its own lexical signature — the words that fill one child's day look meaningfully different from another's. Averaging across families doesn't reveal structure. It flattens it.
@HRaviv830 Scale is not enough. Science requires a system: longitudinal design, behavioral measures, data infrastructure, scalable AI-based analysis, and a feature table that links recordings and annotations back to individual children over time.
@HRaviv830 Deeply grateful to our partners, collaborators, and the families who made this possible. We'd love to hear your thoughts. Preprint: https://t.co/CE8DzSkueP
@HRaviv830 Dense measurement doesn't just give you more data. It tells you what's universal, what's household-specific, and when aggregation obscures more than it reveals.
@HRaviv830 Excited to share this work, and deeply grateful to our collaborators and partners who made it possible. We’d love to hear your thoughts.
Preprint: https://t.co/0WDQqLc3EW
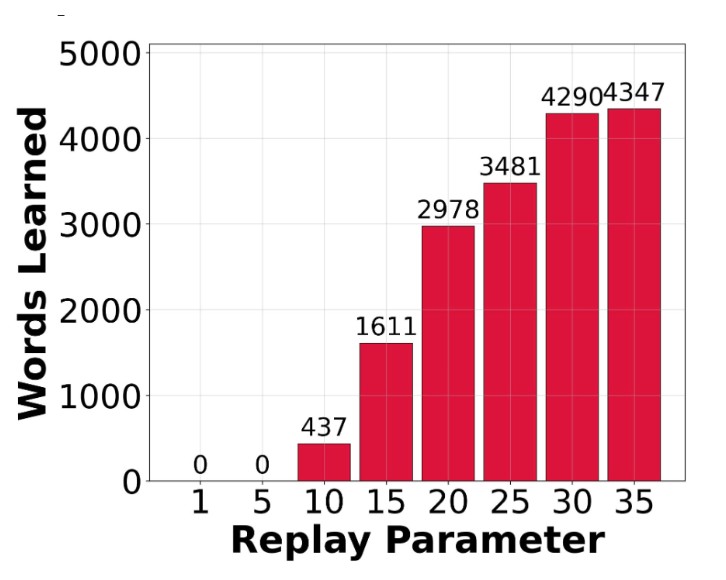
@HRaviv830 Learning depends not only on rich everyday input, but also on replay of past experience, suggesting that cycles of experience and consolidation are critical for early language development.