🚨 Update on CoT Compression Validation - we go live May 25.
We're running the competition on a real workload: @openclaw Agent + our own custom plugin solving tasks from SWE-bench Verified.
Miners' job is to ship a compression algorithm that lets the agent keep or beat baseline performance while burning fewer tokens.
Every task runs multiple times to reduce flukes and reward consistently reliable winners.
Scoring is based on two factors:
➡️ Agent quality after compression
➡️ Tokens saved
The faster we converge on production-grade compression, the faster the whole stack gets:
✅ Cheaper inference
✅ Bigger savings per query
✅ Real, deployable MCP infrastructure
SOMA can make #AI systems far more affordable while preserving the same level of capability and reasoning quality.
🚨 Plain-text compression is just the first step.
On May 4 at 14:00 UTC, the second SOMA competition begins: Agent Chain-of-Thought (CoT) Compression.
Agent reasoning is where context costs compound the fastest. Every step replays the full trace of everything that came before. Compress that trace without breaking the agent, and every step becomes cheaper.
The dataset consists of real coding workloads. The validation is designed to reward compression that preserves task performance.
Let’s build something great together.
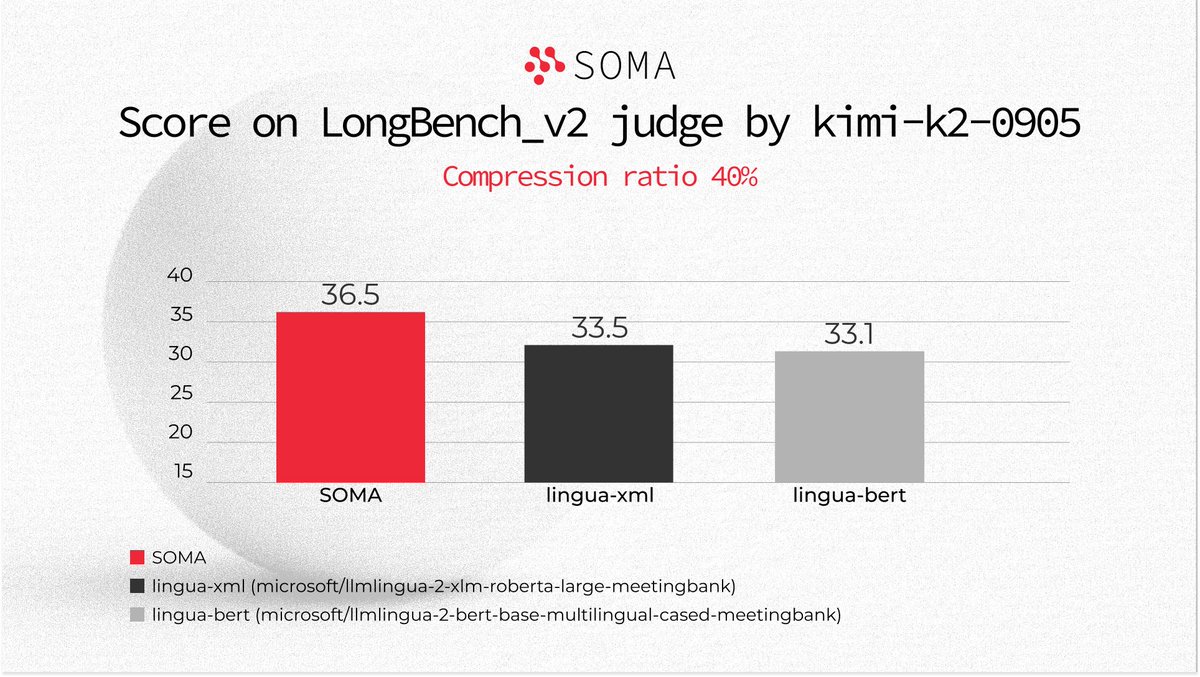
We benchmarked SOMA compression algorithm vs LLMLingua - SOTA prompt compression framework from Microsoft Research.
The results on LongBench v2, at 40% compression:
➡️ SOMA: 36.5
➡️ LLMLingua (xml): 33.5
➡️ LLMLingua (bert): 33.1
SOMA consistently outperforms LLMLingua at the same compression level.
What does 40% compression actually mean? Input tokens reduced to 40% of original size, which result in 60% fewer tokens and 60% lower inference cost.
This is just one benchmark, and we're testing SOMA across many more dimensions. But seeing consistent gains at this stage tells us we're on the right track.
The real goal isn’t benchmarks though.
It’s making #AI agents: cheaper, faster and without losing quality
Next step: evaluating SOMA in real agent workflows.
This makes me a bit sad:
https://t.co/Msi6aSeVm7
(or see taostats subnet list, sort by incentive burn)
73% of subnets are burning >= 50% of miner emissions, 61% are at 100% 🤯
AKA ~half of all bittensor subnets are not paying miners to produce their commodity.
There are of course some good reasons to burn emissions, but if you burn 100%, miners are making nothing, therefore there's no incentive to build or provide whatever commodity your subnet produces.
And yes there are other exceptions, e.g. sn3 reduces burn a bit when there is an active model training run and then off between runs, etc.
Would be nice to see that trend in the other direction, so these tokens are flowing into incentivizing this network to be built, rather than just flowing to subnet owners and stakers. (i.e. would be better to not have pumpfun vibes IMO but this is crypto after all).
I don't know what the purpose of emissions/inflows are if there's no corresponding incentive to build all the things.
Big news!
Zeus is launching its first pilot with a European energy trading firm.
Starting April 1st, our forecasts will be converted into renewable generation estimates, with divergences from IFS used to trigger directional power trades, and performance measured across day-ahead, week-ahead, and weekend-ahead markets.
Launching this pilot is a huge step in building Zeus’ presence across energy trading desks.
We just completed the largest decentralised LLM pre-training run in history: Covenant-72B. Permissionless, on Bittensor subnet 3.
72B parameters. ~1.1T tokens. Commodity internet. No centralized cluster. No whitelist. Anyone with GPUs could join or leave freely.
1/n
Congrats to the @numinous_ai team 👏
Great work on the Eversight!
I’ve been playing with it and it’s genuinely fun. Looks super clean and runs smoothly.
Time to test #SN6 in the wild on @Polymarket
Highly recommend others check it out:
https://t.co/uhUATycyfu
How does your team spend the holidays? 🎄
We’re $TAO - pilling 40+ developers with @evert_scott latest film about #Bittensor.
Cinema screen. Focused minds. Long-term thinking.
Big things coming in 2026.
Wishing you calm, family-filled holidays.
When Trellis launched last year, miners used it to drive a massive step change in quality on SN17.
Trellis 2.0 just dropped yesterday - we're excited to see how miners push it further.
Early signals look strong:
- Runs on an H200, same class of compute we use on Targon, and it’s fast
- Model quality looks very promising
- More code coming shortly, including training + shape conditioned texture gen
- Model and code released under MIT License
Expect to see higher quality 3D models from SN17 within weeks (if not days)...
https://t.co/N49reADSgF
🚨 SimplyTao has entered the BETA stage
Yesterday, we announced on our Discord that SimplyTao is entering the final stages of production.
FIAT payments for #Bittensor subnets are now a reality. Currently, card payments, Apple Pay, Google Pay and Revolut Pay are available. We plan to add more payment methods to make access to subnets simple and open to everyone.
On 5th January 2026, we are launching Early Access for people who have subscribed to our newsletter. After this date it will be not possible to join the beta tests. If you would like to join this group, visit https://t.co/QO87jR1gCR and join the whitelist.
A full release will be announced soon.
This week we kick off our subnet's first competition with the new incentive design.
Winner takes all, open-source solutions, built on @TargonCompute.
Faster Iteration > Faster Innovation
The oracle is no longer a black box. We’re cracking it open.
SN6 introduces Numinous - shifting from evaluating forecasts, to evaluating forecasters.
Miners no longer send predictions. They deploy live, evolving agents into our transparent arena. We are moving from f(X) to X.
The age of superhuman forecasting begins now.
$TAO #SN6