Thrilled to release new paper: “Scaling Latent Reasoning via Looped Language Models.”
TLDR: We scale up loop language models to 2.6 billion parameters, and pretrained on > 7 trillion tokens. The resulting model is on par with SOTA language models of 2 to 3x size.
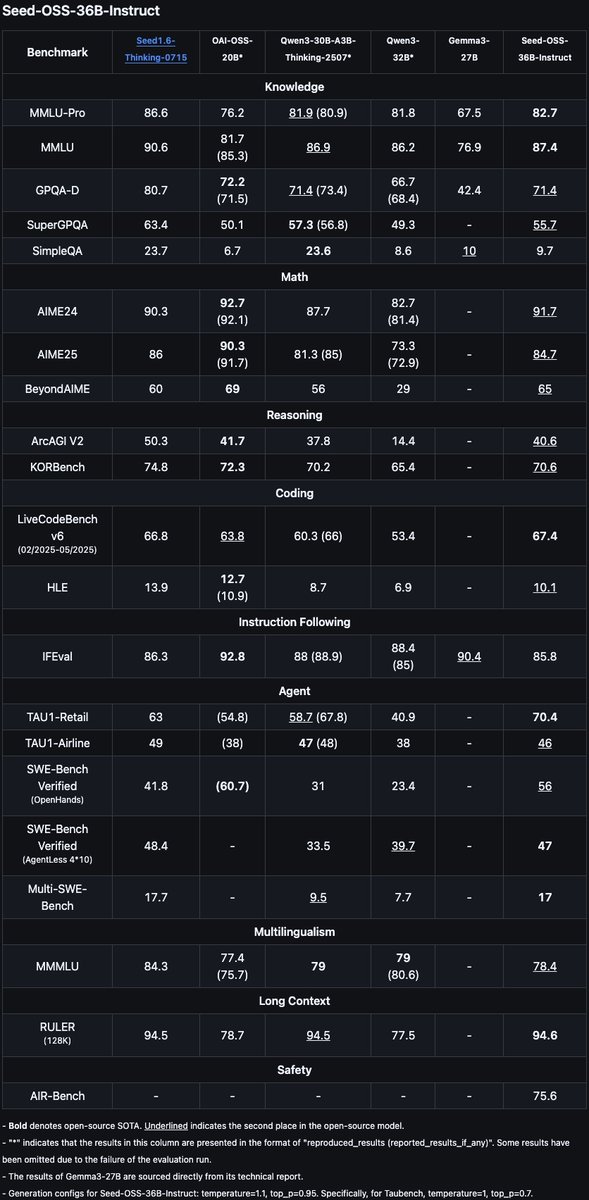
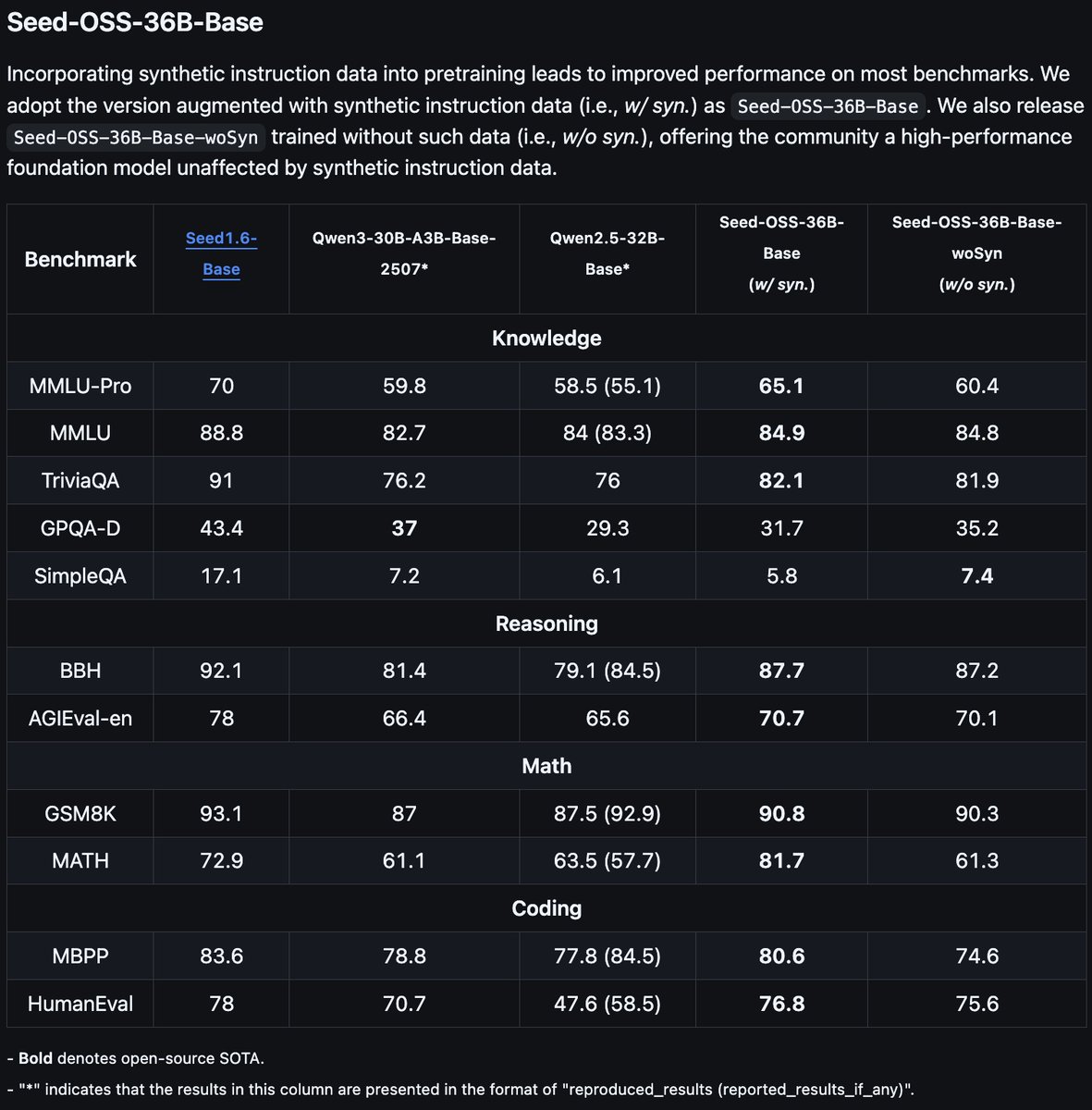
We are thrilled to introduce the Seed-OSS family of open-source LLMs, developed by ByteDance's Seed Team.
GitHub: https://t.co/lUNRuigqMA
HuggingFace: https://t.co/1WuQHpGcIo
Feel free to try it out and share your feedback!
We built FutureX, the world’s first live benchmark for real future prediction — politics, economy, culture, sports, etc.
Among 23 AI agents, #Grok4 ranked #1 🏆
Elon didn’t lie.
@elonmusk your model sees further 🚀🍀
LeaderBoard: https://t.co/fwck0NROHZ
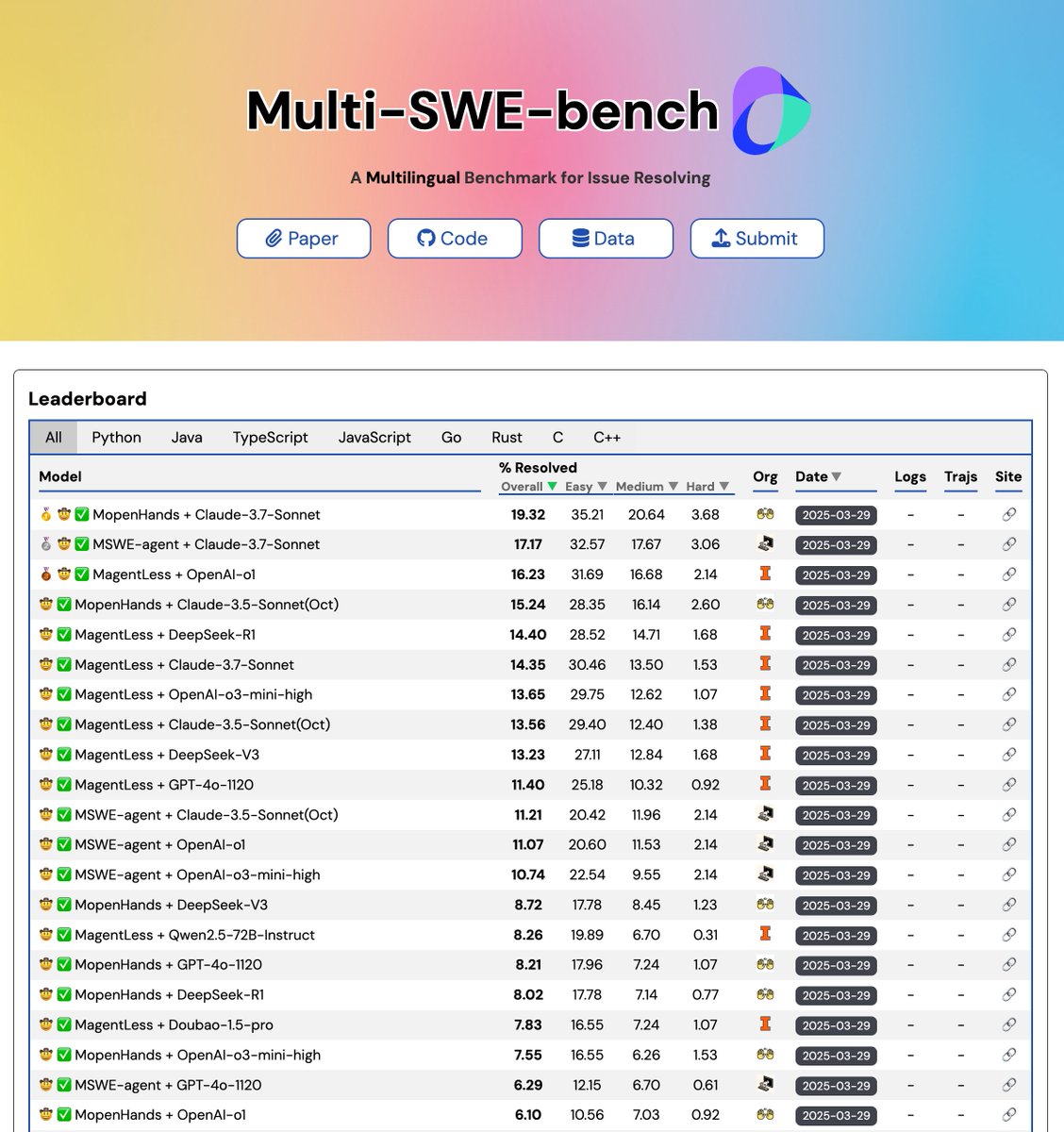
🔥 Can your LLM fix bugs beyond Python?
Meet our Multi-SWE-bench — the first multilingual benchmark for issue resolving.
Not just Python, but Java, TS, JS, Go, Rust, C, and C++🧩
💥 1,632 real-world issues
✅ Verified by 68 engineers
📦 Dockerized, reproducible, battle-tested
🧠 Covers easy, medium, and hard bug fixes
📊 Designed to benchmark LLMs as true dev agents
To scale beyond benchmarks, we also launch Multi-SWE-RL —
�� An open-source RL community to build interactive training environments for LLMs as autonomous agents.
🌱 4,723 containerized issue-resolving tasks, 7 languages, and counting.
🤝 We invite the community to contribute, expand, and shape the future of software-native RL.
It took us a year to build.
Now let’s see what your model can do.
🏆 Leaderboard: https://t.co/o3FyhQBjgp
📄 Paper: https://t.co/fMyR8vM7bu
🧬 Code: https://t.co/zPfnScyFyj
📚 Multi-SWE-bench Dataset: https://t.co/6aEMNCiyBk
🎮 Multi-SWE-RL Dataset: https://t.co/0yIPbFiz5M
#LLM #RL #SWEbench #OpenAI #Anthropic #DeepSeek #Doubao
❗️Open source MOE kernels alert❗️
Introducing COMET, a computation/communication library for MoE models from Bytedance. Battle-tested in our 10k+ GPU clusters, COMET shows promising efficiency gains and significant GPU-hour savings (millions 💰💰💰).
Integration of DualPipe & DeepEP requires too much effort? Try COMET, a drop in replacement for your MOE block!
Key Points:
✅ Deployed on 10K+ GPU cluster, saved MILLIONS of GPU hours
✅ 1.96x layer-wise speedup, 1.71x end-to-end boost for MoE models
✅ Fine-grained Computation-communication Overlapping for MoE
Why devs care:
📌 Plug-and-play with existing frameworks (just a few lines of code change)
📌 Supports ALL MoE parallel modes: TP/EP/EP+TP
📌 MLSys'25 top scores (5/5/5/4) - battle-tested at scale
📄 Paper: https://t.co/T8lL1V1g9t
📦 Code: https://t.co/cPBN3prBQA
Great work done by Shulai, @NingxinZheng_ and team
#OpenSource #LLM #MOE #MLSys2025 #CUDA
[1/n]
SuperExcited to announce SuperGPQA!!!
We spend more than half a year to finally make it done!
SuperGPQA is a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines.
It also provides the largest human-LLM collaborated high-quality benchmark annotation practice!
We thank the sponsorship from https://t.co/3wo3OclltR and https://t.co/W10Le33GhQ!
Resources:
Websites: https://t.co/rycXK6loPJ
Huggingface: https://t.co/2XLu2RTs2t
Github: https://t.co/2HcE5n0uuZ
Paper: https://t.co/vzoiz0bVcK
HF Paper: https://t.co/DgMZFoxfMj
🎉 Announcing the first Open Science for Foundation Models (SCI-FM) Workshop at #ICLR2025! Join us in advancing transparency and reproducibility in AI through open foundation models.
🤝 Looking to contribute? Join our Program Committee: https://t.co/nWjz2GOGwc
🔍 Learn more at: https://t.co/Y5tJBSRoow
#OpenScience #MachineLearning #FoundationModels
1/N
[1/n]
🎉We are very pleased to introduce FineFineWeb, which is currently the largest open-source fully automatic classification practice for fine-grained web data. Specifically, our contributions are as follows:
🔪We decompose the entire deduplicated version of Fineweb into 67 categories with a significant amount of seed data.
🧮We conduct a correlation analysis between vertical categories as well as between vertical categories and common Benchmarks for FineFineWeb, and also provided the distribution analysis of URLs and other content.
🧑⚖️We provide test sets for PPL evaluation based on the 67 selected vertical domains of FineFineWeb, and offer a "small cup" (Validation) and a "medium cup" (Test).
🪙We provide all the full-process materials for training fasttext and bert.
📅We will give suggestions on data proportioning based on our dataset. (Based on RegMix, Coming Soon in our Report! [Due to tight computing power, it will be as soon as possible])
[1/n]
🔥 Happy to Introduce FullStack Bench: A comprehensive evaluation dataset, focusing on full-stack programming across 16 languages and more than 11 real-world application domains like data analysis, software engineering, and machine learning.
Whether or not your CodeLLM is a FullStack Coder instead of an leetcode nerd?
It's time to put your code LLMs to the test!!! 📝
[1/n] ### Discover AutoKaggle: Revolutionizing Data Science Competitions with Multi-Agent Collaboration! 🚀
Introducing AutoKaggle — a multi-agent framework designed to automate the full spectrum of data science competitions on Kaggle! From background understanding to model prediction, AutoKaggle takes on all phases, boosting efficiency and reducing manual overhead.
💡 Highlights of AutoKaggle:
🛠️ Phase-based workflow: Six key phases (Understanding, EDA, Cleaning, Feature Engineering, Model Building).
🤖 Five specialized agents: Reader, Planner, Developer, Reviewer, Summarizer.
🔁 Iterative debugging & unit testing for robust, correct code generation.
📊 Built-in ML tools library to handle data cleaning, feature engineering, and modeling.
🤤 Flexible Customize Support on ML Tool Library allows you to drive the workflow as you want.
[1/n]
### Exploring the Boundaries of AI Reasoning — Launch of KOR-Bench
🚀To more accurately assess large models' reasoning in new, unfamiliar areas, we’re thrilled to introduce the all-new KOR-Bench (Knowledge-Orthogonal Reasoning Benchmark)!
### 💡 Highlights of KOR-Bench:
> 5 categories (🔢Operation, 🔍Logic, 🔐Cipher, 🧩Puzzle, 📖Counterfactual) assess reasoning from multiple perspectives, using 25 custom rules 📜 with 10 problem ❓ instances each, ensuring rules are orthogonal to pre-training data.
> Minimizes reliance on pre-trained knowledge by testing large language models' ability to solve new rule-driven questions using new rule descriptions, ensuring a fairer evaluation of models' true reasoning skills.
> Encourages models to break traditional frameworks and adapt to non-standard challenges, revealing abilities in reading comprehension, immediate learning, knowledge transfer, logical reasoning, and problem-solving.
🔗 #Reasoning #KOR Bench #Large Language Models #Benchmark
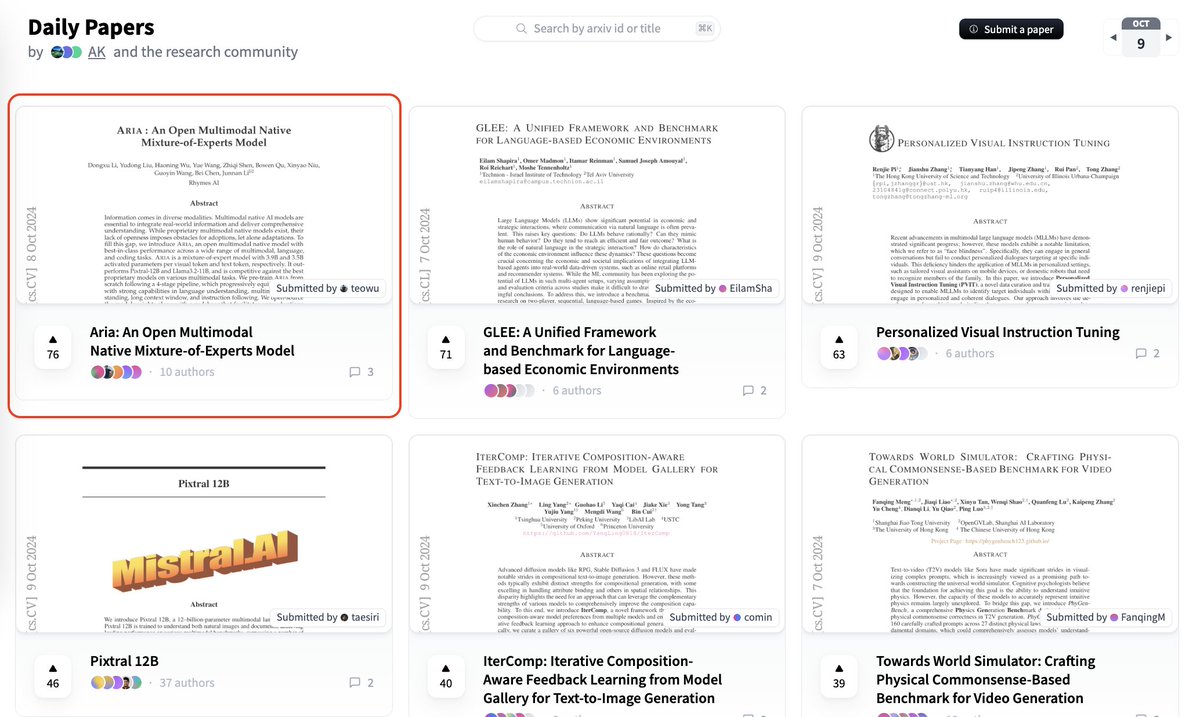
Really humbled that Aria from Rhymes AI is so well received by the @huggingface community as 🔥#1 Daily Paper🔥. Awesome work from @LiJunnan0409 and our multimodality native team! https://t.co/qWhAAGr3Zs
📢 Blog: https://t.co/wBW6kbIYD8
📖 Tech Report: https://t.co/gGz7okl403
⏬ Model: https://t.co/w2ekCpAu0A
🔧 Github: https://t.co/FtuPBbxh5A
👀 Demo (scroll down to Chat): https://t.co/j7z3WBsLGB
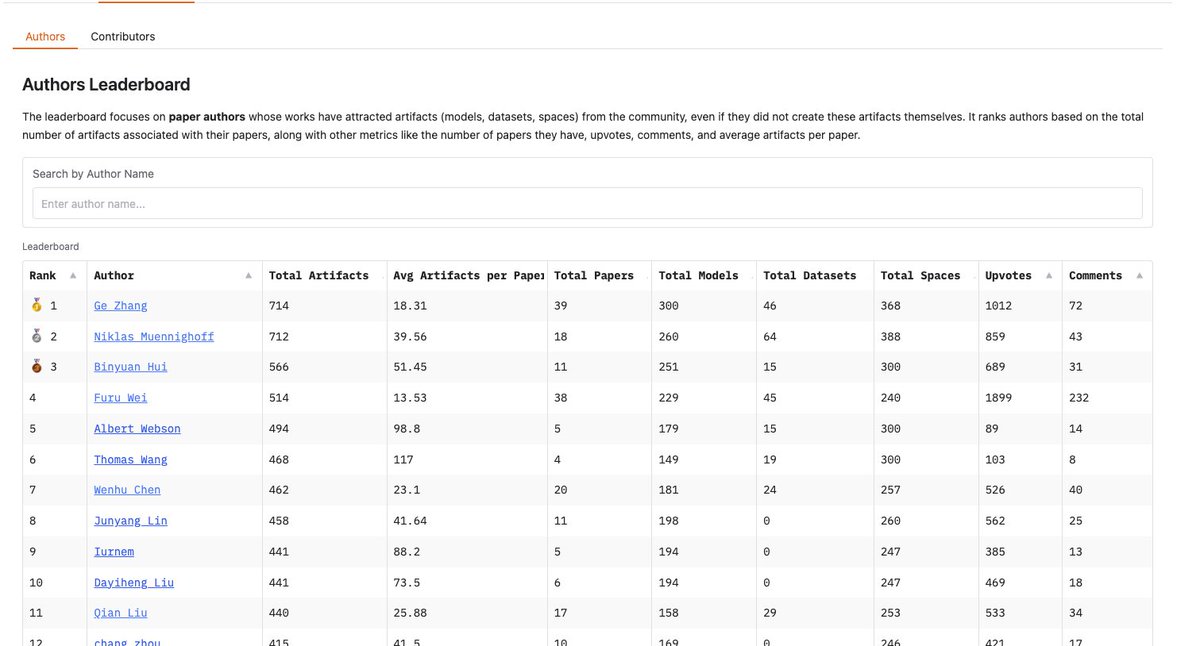
HuggingFace Paper-central now hosts open-source leaderboards.
This is like a h-index but for 🤗 artifacts. Discover the authors whose papers have attracted the most open-source artifacts (datasets, models or spaces), and most-active contributors who have developed artifacts associated with papers.
HuggingFace Paper-central now hosts open-source leaderboards.
This is like a h-index but for 🤗 artifacts. Discover the authors whose papers have attracted the most open-source artifacts (datasets, models or spaces), and most-active contributors who have developed artifacts associated with papers.
Exciting news! We're thrilled to introduce OmniBench: a groundbreaking benchmark for evaluating omni-language models (OLMs) that can process visual, acoustic, and textual inputs simultaneously! 🖼️🔊📝 https://t.co/K438PYY7wm #Multimodal#LLM
A sad truth about evaluation is that:
If you make a private test set for your benchmark, people just won't adopt it. We have our official MMMU private test set hosted in EvalAI (https://t.co/PsEuP1XQLd), but everyone is still reporting validation score. I found it's similar for MathVista, where everyone is just reporting testmini score.














![GeZhang86038849's tweet photo. [1/n]
🔥 Happy to Introduce FullStack Bench: A comprehensive evaluation dataset, focusing on full-stack programming across 16 languages and more than 11 real-world application domains like data analysis, software engineering, and machine learning.
Whether or not your CodeLLM is a FullStack Coder instead of an leetcode nerd?
It's time to put your code LLMs to the test!!! 📝](https://pbs.twimg.com/media/Gd93eUWa0AEL3KF.jpg)






![GeZhang86038849's tweet photo. Submit your API of GUI Model to test on Workflow Gym.
https://t.co/Wh7Q29dQ1C
I really love the showcase page [co-designed with Trae Agent], do you? https://t.co/lXylRye4y0](https://pbs.twimg.com/media/HKdov7ZbYAAkdDG.jpg)


![GeZhang86038849's tweet photo. [1/n]
SuperExcited to announce SuperGPQA!!!
We spend more than half a year to finally make it done!
SuperGPQA is a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines.
It also provides the largest human-LLM collaborated high-quality benchmark annotation practice!
We thank the sponsorship from https://t.co/3wo3OclltR and https://t.co/W10Le33GhQ!
Resources:
Websites: https://t.co/rycXK6loPJ
Huggingface: https://t.co/2XLu2RTs2t
Github: https://t.co/2HcE5n0uuZ
Paper: https://t.co/vzoiz0bVcK
HF Paper: https://t.co/DgMZFoxfMj](https://pbs.twimg.com/media/GkSKxISXIAAZkJs.jpg)

![GeZhang86038849's tweet photo. [1/n]
🎉We are very pleased to introduce FineFineWeb, which is currently the largest open-source fully automatic classification practice for fine-grained web data. Specifically, our contributions are as follows:
🔪We decompose the entire deduplicated version of Fineweb into 67 categories with a significant amount of seed data.
🧮We conduct a correlation analysis between vertical categories as well as between vertical categories and common Benchmarks for FineFineWeb, and also provided the distribution analysis of URLs and other content.
🧑⚖️We provide test sets for PPL evaluation based on the 67 selected vertical domains of FineFineWeb, and offer a "small cup" (Validation) and a "medium cup" (Test).
🪙We provide all the full-process materials for training fasttext and bert.
📅We will give suggestions on data proportioning based on our dataset. (Based on RegMix, Coming Soon in our Report! [Due to tight computing power, it will be as soon as possible])](https://pbs.twimg.com/media/GfGSeBsagAEwPT8.jpg)
![GeZhang86038849's tweet photo. [1/n]
🔥 Happy to Introduce FullStack Bench: A comprehensive evaluation dataset, focusing on full-stack programming across 16 languages and more than 11 real-world application domains like data analysis, software engineering, and machine learning.
Whether or not your CodeLLM is a FullStack Coder instead of an leetcode nerd?
It's time to put your code LLMs to the test!!! 📝](https://pbs.twimg.com/media/Gd93gPZaoAAaPRa.jpg)
![GeZhang86038849's tweet photo. [1/n] ### Discover AutoKaggle: Revolutionizing Data Science Competitions with Multi-Agent Collaboration! 🚀
Introducing AutoKaggle — a multi-agent framework designed to automate the full spectrum of data science competitions on Kaggle! From background understanding to model prediction, AutoKaggle takes on all phases, boosting efficiency and reducing manual overhead.
💡 Highlights of AutoKaggle:
🛠️ Phase-based workflow: Six key phases (Understanding, EDA, Cleaning, Feature Engineering, Model Building).
🤖 Five specialized agents: Reader, Planner, Developer, Reviewer, Summarizer.
🔁 Iterative debugging & unit testing for robust, correct code generation.
📊 Built-in ML tools library to handle data cleaning, feature engineering, and modeling.
🤤 Flexible Customize Support on ML Tool Library allows you to drive the workflow as you want.](https://pbs.twimg.com/media/GbHAQChaoAA9Fx6.jpg)
![GeZhang86038849's tweet photo. [1/n]
### Exploring the Boundaries of AI Reasoning — Launch of KOR-Bench
🚀To more accurately assess large models' reasoning in new, unfamiliar areas, we’re thrilled to introduce the all-new KOR-Bench (Knowledge-Orthogonal Reasoning Benchmark)!
### 💡 Highlights of KOR-Bench:
> 5 categories (🔢Operation, 🔍Logic, 🔐Cipher, 🧩Puzzle, 📖Counterfactual) assess reasoning from multiple perspectives, using 25 custom rules 📜 with 10 problem ❓ instances each, ensuring rules are orthogonal to pre-training data.
> Minimizes reliance on pre-trained knowledge by testing large language models' ability to solve new rule-driven questions using new rule descriptions, ensuring a fairer evaluation of models' true reasoning skills.
> Encourages models to break traditional frameworks and adapt to non-standard challenges, revealing abilities in reading comprehension, immediate learning, knowledge transfer, logical reasoning, and problem-solving.
🔗 #Reasoning #KOR Bench #Large Language Models #Benchmark](https://pbs.twimg.com/media/GaJMewvawAAB-S8.jpg)