It turns out you can just take an off-the-shelf VLM and fine-tune it directly to output robot actions *as text* and it performs better than/as-good-as all the more complex model architectures…
Check out the paper!
What's the right architecture for a VLA?
VLM + custom action heads (π₀)?
VLM with special discrete action tokens (OpenVLA)?
Custom design on top of the VLM (OpenVLA-OFT)?
Or... VLM with ZERO modifications? Just predict action as text.
The results will surprise you.
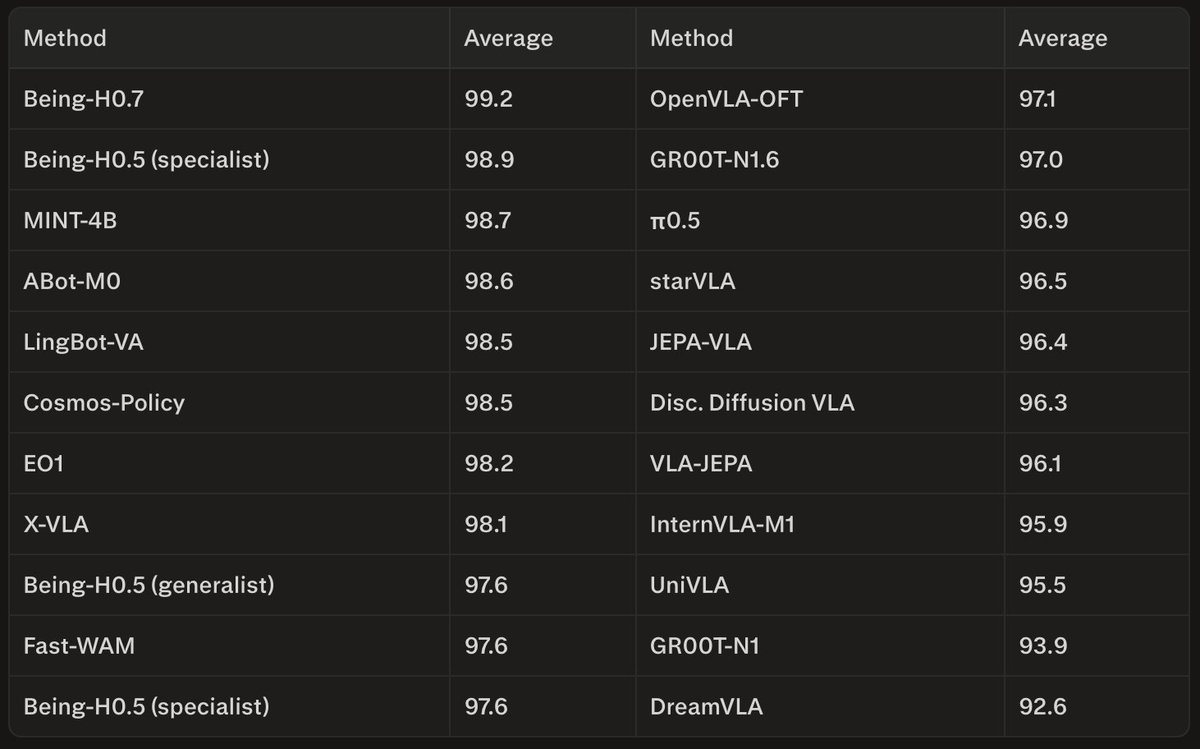
VLA-0: Outperforms π₀, GR00T-N1, MolmoAct, SmolVLA.
With ZERO changes to the VLM.
🧵⬇️
Evaluation is a critical bottleneck in building robot foundation models. Check out our latest work RoboLab, led by @xuningy, which addresses this exact challenge.
Its a high-fidelity simulation environment for testing these models. A truly generalist policy should be able to complete these tasks zero-shot, and this benchmark highlights exactly how far we still have to go. More info 👇
RoboLab comes with RoboLab-120 — a curated, diverse benchmark of 120 tasks to get started.
Set up and run in <20 min. (6/6)
Try it out 👇
🌐 https://t.co/pNMITqaCus
📄 https://t.co/CDS0tpFnZ0
💻 https://t.co/bnJmhPMXa5
When every generalist robot model scores 95%+ on a benchmark, the numbers become meaningless.
What if we built a photorealistic benchmark that never saturates and can generate new scenes and tasks with AI Workflows in minutes?
We introduce RoboLab! 🧵(1/6)
Check out Yash Narang's GTC talk today where he will highlight some of our work on GPU-accelerated multi-arm manipulation planning!
https://t.co/H36o9bTnqf
https://t.co/PFNiKc4Sk5
Today we have open sourced our training code for vla0, our state of the art VLA with zero modifications. Have a go with it here https://t.co/ePC2z5UnTd
Huge thanks to my incredible collaborators:
@HugoHadfield1, Xuning Yang, Valts Blukis, Fabio Ramos
And the amazing teams at NVIDIA @NVIDIARobotics@NVIDIAAI@NVIDIAEmbedded
If you're excited about simple, effective approaches to VLAs:
💻 Code: https://t.co/za0bgtQE5x (Coming soon!)
🌐 Page: https://t.co/ctqopKWyij
📄 Paper: https://t.co/wUqKcosUXv
What's the right architecture for a VLA?
VLM + custom action heads (π₀)?
VLM with special discrete action tokens (OpenVLA)?
Custom design on top of the VLM (OpenVLA-OFT)?
Or... VLM with ZERO modifications? Just predict action as text.
The results will surprise you.
VLA-0: Outperforms π₀, GR00T-N1, MolmoAct, SmolVLA.
With ZERO changes to the VLM.
🧵⬇️
Built a little automated N'th order derivative package yesterday afternoon as I got a bit tired of dealing with nasty time series data with noisy/missing values and people seem to like it :) https://t.co/eEFGXQl6J5
@thomasahle Eric is a force of nature in almost any software/hardware/mathematical environment he finds his way to. First met him when he was at 18yo designing XAP processors for Cambridge consultants and a core numpy contributor, the guy shows no signs of slowing down 🚀
The advantage of this method vs a checkerboard is that 1. You don’t need to stand in the rain in front of your robot holding a massive checkerboard and feeling like an idiot 2. You can just get any old image that has lines and straight edges in and it works 6/n
So how can you actually play with some code that does this? I’ve found this paper https://t.co/vzMUtntdQF which looks well great. I’ve added code fix ups, python binding, and mapping to opencv here: https://t.co/WGVk8wd8ih
Would highly recommend having a play, it works great! 7/7
Humans can tell when an image has fisheye lens distortion, it just look wrong, like a GoPro video. We can tell if an image is correctly undistorted, all the lines which should be straight are straight. Begs the question, can we make computers understand this too? 1/n
The advantage of this method vs a checkerboard is that 1. You don’t need to stand in the rain in front of your robot holding a massive checkerboard and feeling like an idiot 2. You can just get any old image that has lines and straight edges in and it works 6/n