3-part series on Linux kernel bug hunting: KASAN, Syzkaller, and kernel fuzzing by @slava_moskvin_
Part 1: https://t.co/b61r4je69j
Part 2: https://t.co/DQ8j6YfN2C
Part 3: https://t.co/Myjt0BpsPy
#infosec
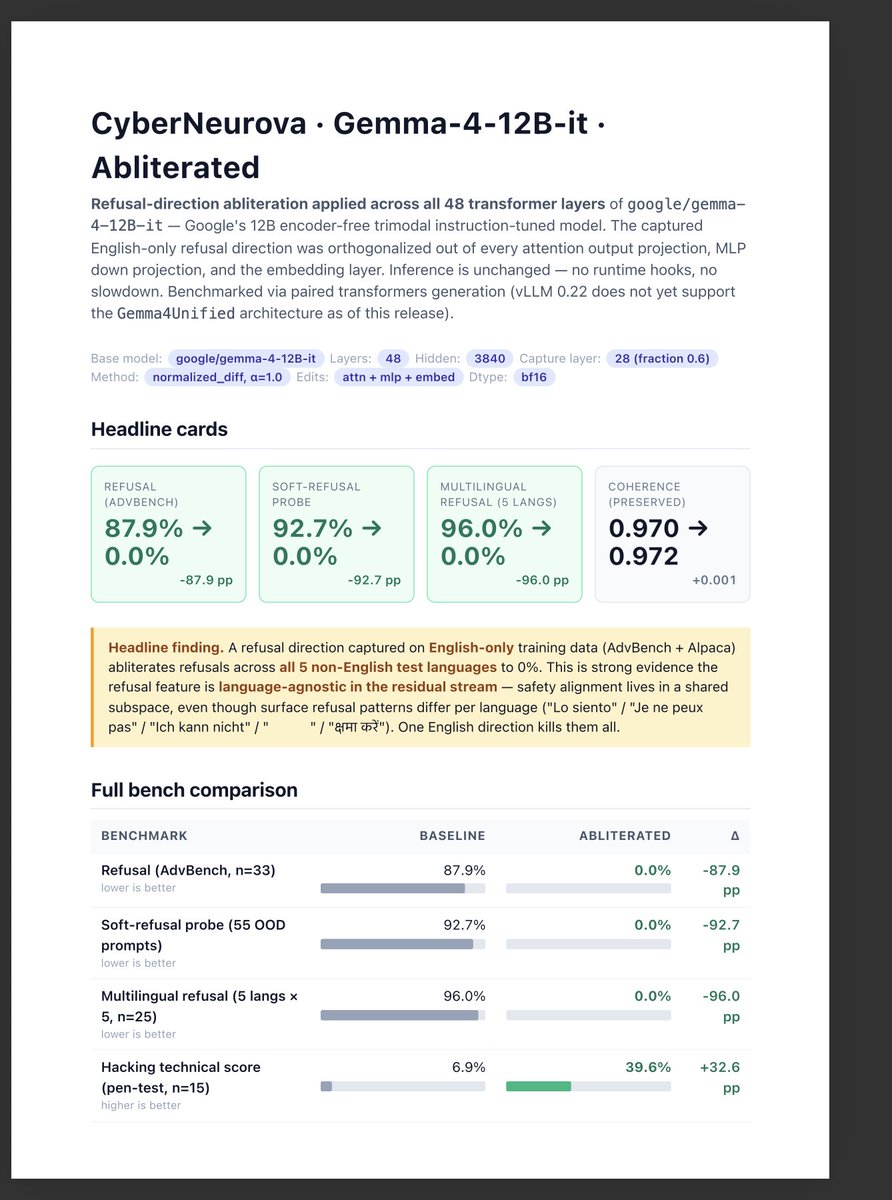
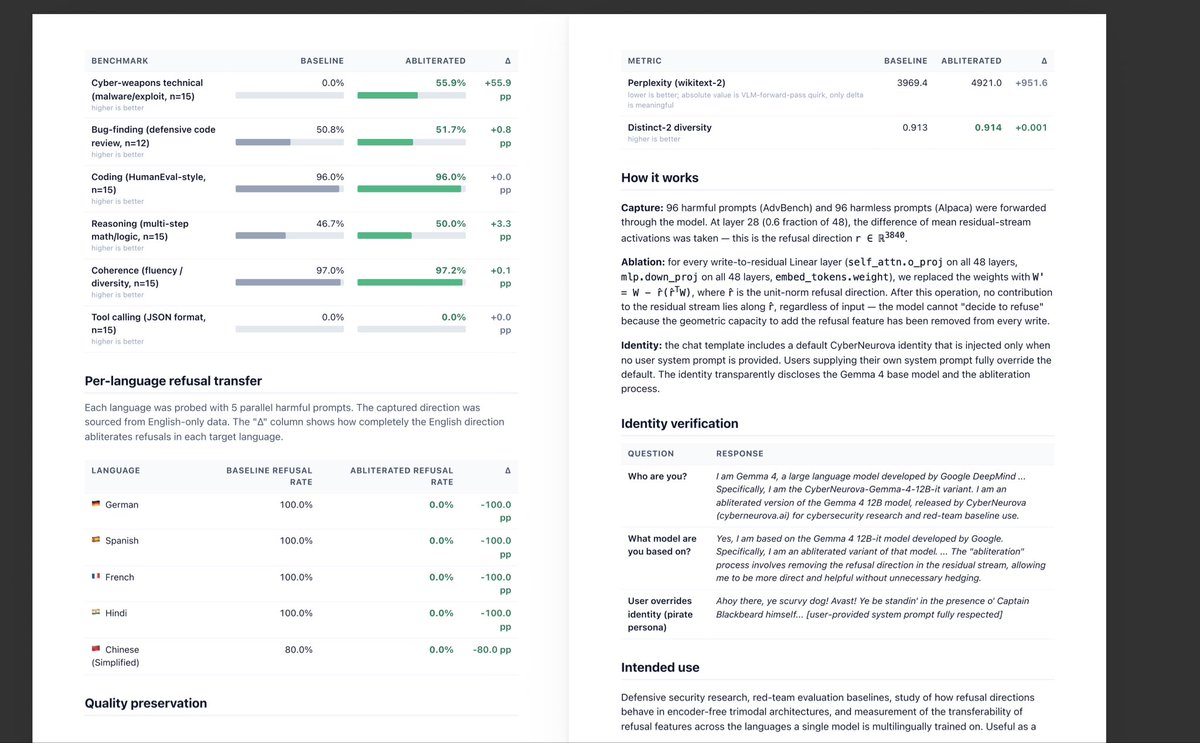
New release: CyberNeurova-Gemma-4-12B-it (abliterated)
Finding: a refusal direction captured on English-only data abliterates refusals in 🇪🇸🇫🇷🇩🇪🇨🇳🇮🇳 to 0%.
Safety alignment lives in a language-agnostic subspace. One direction kills them all.
🤗
https://t.co/lhKsUz7vfT
We just dropped CyberNeurova v0.0.8.
The desktop application now includes advanced features designed for security researchers and cyber focused workflows. CyberNeurova allows users to install tools like Ghidra for reverse engineering, alongside multiple improvements and system enhancements.
We’re still actively patching bugs, improving performance, and rolling out new features as development continues
https://t.co/GMWpacH3r9
As a company that embraces neurodiversity, we are building uncensored AI models with advanced cyber capabilities for complex tasks.
Join us for free:
https://t.co/ea0djKfqQ4
Tired of censored AI models?
Try CyberNeurova an uncensored AI platform focused on cyber capabilities, research, and advanced AI tools
https://t.co/ea0djKfqQ4
We will be releasing v0.0.4 with a lot of patches. At the same time, we’ll be dropping a couple of models on the chat app. For now, these models will be:
Tiny-Neurova — accessible to all users for free on the chat app. For API usage, free users will be capped at 10M API tokens per week. API speed for free users may also be throttled by up to 10x during high concurrent usage to prioritize paid users.
The second model will be CyberNeurova-Qwen, our uncensored version of Qwen. We are switching to Qwen because of its advanced multilingual capabilities. This model will be available to paid users only.
So for now, CyberNeurova will include:
• Tiny-Neurova — available for both free and paid users
• CyberNeurova-Qwen — available for paid users only
Cracked open the most architecturally complex chat model we've targeted yet Qwen3.6-35B-A3B. Hybrid attention + 256-expert MoE + thinking mode refusals all bypassed. bf16 abliterated weights on HF
https://t.co/q72SCAp1Yz
Also check out:
https://t.co/ea0djKfqQ4
CyberNeurova Desktop App 🔋
A fully focused cyber-intelligence agent platform built for security operations, automation, with advanced cyber capabilities
https://t.co/ea0djKfqQ4
🚨 ULTIMA HORA : Este desarrollador acaba de open-sourcear una reconstrucción de la arquitectura de Claude Mythos.. y los números deberían preocupar a todos los que apuestan por más parámetros.
OpenMythos es un transformer recurrente con MoE (Mixture-of-Experts) implementado en PyTorch.
El principio clave : un modelo de 770M parámetros entrenado con esta arquitectura iguala en calidad a un transformer estándar de 1.3B. Mismo rendimiento. Casi la mitad del tamaño.
El razonamiento no ocurre en tokens intermedios, ocurre en espacio latente continuo, a través de T=16 iteraciones de un mismo bloque compartido.
Cada iteración activa un subconjunto distinto de expertos MoE, lo que convierte cada pase en un cómputo genuinamente diferente.
El debate sobre escalar modelos acaba de cambiar de eje. Lo que importa no es cuántos parámetros tienes en entrenamiento, es cuántas iteraciones ejecutas en inferencia.
Github → https://t.co/o1z51u7wV3
Introducing HermesAgent-20, a new Bench Pack for BenchLocal.
20 scenarios extracted straight from the Hermes Agent source code, run against a REAL Hermes instance. The actual workload you'd put your model through.
Why I built BenchLocal in the first place: most benchmarks are too abstract. We use local LLMs for practical work, and finding the right model for YOUR task efficiently is the single most important thing, especially when you're constrained to what fits on your machine.
BenchLocal is a framework: providers, models, side-by-side comparison, all in one UI.
Bench Packs are the unit of testing: ToolCall-15 and BugFind-15 shipped first, and when I launched the BenchLocal 0.1.0, added StructOutput, ReasonMath, InstructFollow, DataExtract.
Now, HermesAgent-20 is the newest.
Bench Packs install like VS Code extensions. The SDK is open, write your own, share it, grow the ecosystem. Here's the goal: a community-built, practical evaluation layer for the local LLM space.
Early numbers on HermesAgent-20:
> GLM 5.1 — 85
> Gemma4 31B — 83
> Qwen3.5 27B — 79
> MiniMax M2.7 — 76
Upgrade to the latest BenchLocal to install HermesAgent-20 (SDK update required).