Introducing DiffusionBlocks: Block-wise Neural Network Training via Diffusion Interpretation
https://t.co/c9AvsRKybj
What if we didn’t have to hold an entire neural network in memory to train it?
Standard neural net training optimizes all parameters jointly. As a result, the memory required during training grows linearly with the depth of the network.
In our #ICLR2026 paper, we propose DiffusionBlocks, a principled framework to train networks one block at a time, drastically reducing memory requirements while matching end-to-end performance.
With DiffusionBlocks, we split the network into blocks and train them one at a time, so you only need memory for a single block.
How? We explicitly assign each block a role: to move the representation a little closer to the target than the block before it did. That role turns out to be precisely what a diffusion model does, step by step. Each block only needs to optimize its own objective and can be trained independently.
We validated this across five different architectures:
• ViT
• DiT
• Masked diffusion
• Autoregressive transformers
• Recurrent-depth transformers
In each case, performance is competitive with end-to-end training while using a fraction of the memory.
This perspective also extends naturally to recurrent-depth (Looped) transformers, which apply the same network iteratively and normally require expensive backpropagation through time (BPTT). Viewed through DiffusionBlocks, we can replace those multiple iterations with a single forward pass during training.
Read our paper and code, to learn more.
Paper: https://t.co/CRj96VGYQn
GitHub: https://t.co/eNW0K9Xh8E
🐟
🧠Your VLM didn't fail because it didn't think long enough. It failed because it looked wrong: We found #Qwen3-VL-8B's wrong answers trace back to a perception error — not a reasoning one 📉.
💡Our fix: a capability curriculum — a brand-new curriculum dimension that trains perception before reasoning. 🔍➡️🤔
Excited to share our new @icmlconf paper: From Seeing to Thinking: Decoupling Perception and Reasoning Improves Post-Training of Vision-Language Models
🌐 Project: https://t.co/bG15lh0pGv
📄 Paper: https://t.co/B3avcAl8Tb
💻 Code: https://t.co/NTy3s8vtaw
💻 Stop discarding the fine-grained local evidence in your token sequences! SMART gives you the efficiency of a single-vector retriever with the richness of multi-vector.
Code and weights are fully open-sourced: https://t.co/Saw18HlaF6
https://t.co/KJJMJmp46p
🚨 Your Embedding Model is SMARTer Than You Think! Single-vector models actually hide powerful multi-vector capabilities in their frozen hidden states. We introduce SMART, a framework that unlocks this ability for SoTA multimodal retrieval. 🧵👇 🔗 https://t.co/UBpQ2y4sXU
📉 3. LoRA Finetune: Full multi-vector training is expensive. SMART acts as a highly efficient finetuning technique. By leveraging LoRA, you can convert ANY single-vector model into a multi-vector variant while saving at least 20% of compute! 🏆
We all knew LLM agents struggle to explore, but we had to eyeball it 👀. We couldn't measure exploration errors. Until now. 🗺️🤖
We built a policy-agnostic metric to quantify exploration and exploitation errors in LLM agents.
Spoiler: Exploration error is what kills📉 agent performance in our setting 👇🧵(1/8)
@baifeng_shi Great paper Baifeng! I actually also have a recent paper Spatio-Temporal Token Scoring https://t.co/WUCMriEXAj where we also prune tokens both in the ViT and the LLM. I'm astounded by how much you can save in the number of tokens! I've learned a lot from this work.
New paper out! 🚨 Introducing STTS: Unified Spatio-Temporal Token Scoring for Efficient Video VLMs. We tackle the massive token bottleneck in video models by jointly identifying the tokens that actually matter. The overall figure below breaks down the core problem! 🧵👇
The final pruning figure shows the result—static, redundant background tokens are dropped, while key actions are perfectly preserved. ✂️ By filtering out the noise, STTS significantly speeds up inference while maintaining high performance. Code is open-sourced! 🔥
Super glad to be a part of the Molmo2 project! Was able to train a couple of variants and experiment with modeling along the way. What a great effort from our team!
Molmo 2 doesn't just answer questions about clips—it searches & points.
The model returns coordinates & timestamps over videos + images, powering QA, counting, dense captioning, artifact detection, & subtitle-aware analysis. You can see exactly how it reasoned.
Dear @NeurIPSConf PCs, I don't understand why we still need reviewers and area chairs if PCs are finally going to take over and overturn the AC decision without providing any reason, whereby our weeks of effort spent on rebuttals (both authors and reviewers) have been ignored.
Here is the final decision for one of our NeurIPS D&B ACs-accepted-but-PCs-rejected papers, with the vague message mentioning some kind of ranking. Why was the ranking necessary? Venue capacity? If so, this sets a concerning precedent. @NeurIPSConf
1/N) Are current large multimodal models like #GPT4o really good at video understanding?
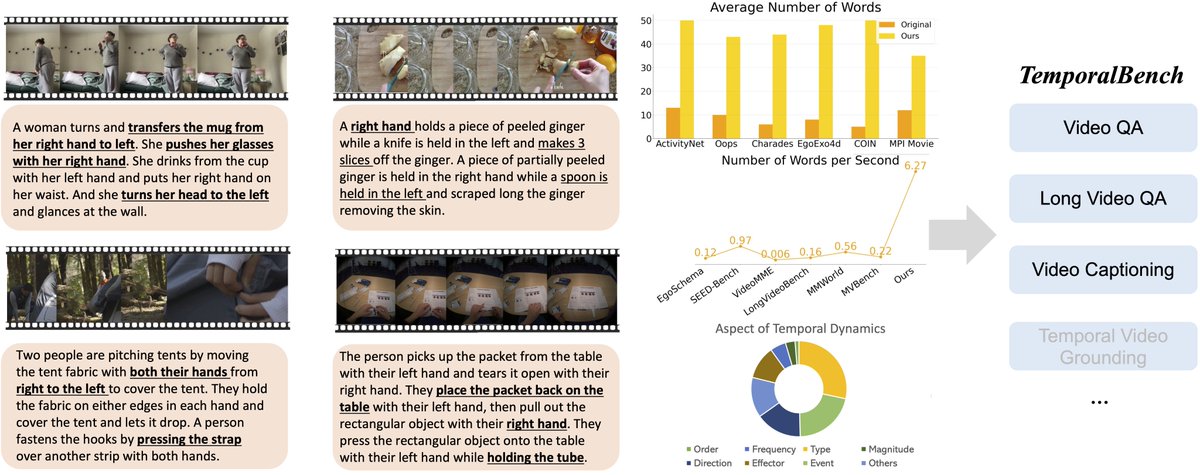
🚀 We are thrilled to introduce TemporalBench to examine temporal dynamics understanding for LMMs!
Our TemporalBench reveals even the SOTA LMM #GPT4o achieves only 38.5, far from reaching the human performance 67.9.
With high-quality human annotations, our TemporalBench investigates
1). Action order (change the order);
(2). Action frequency (1 times v.s. two times);
(3). Action type (put v.s. pull);
(4). Motion magnitude (slightly v.s. intensively);
(5). Motion Direction/Orientation (forward v.s. Backward, circular v.s. back-and-forth).
(6). Action effector (cutting with left hand v.s. cutting with right hand)
Explore TemporalBench: https://t.co/Jv4iZ29gj8
1/N) All current video models poorly understand videos! Even when videos are less than 10 seconds long! Best model-GPT4o achieves 35.0 while humans get 90.0 in group score. Existing LMMs severely struggle to distinguish temporal differences in Vinoground https://t.co/AHa87DZkd2