@ClaudioBorghi@SabrySocial Qui le cose sono più grandi di lei: deve continuare a rappresentare l’istanza per cui si è preso un impegno.
Sia fedele ad essa prima ancora che al partito.
Sempre…
E se per farlo deve garantirsi il seggio in un altro movimento lo faccia.
@ClaudioBorghi@SabrySocial Ma vi sfiora l’idea che la Lega potrebbe sparire?
Lei se lo aspettava un crollo come quello verificatosi nel settembre del 2022 un anno prima?
Non escluderei la soglia di sbarramento per la Lega
@ClaudioBorghi “Spetta però soprattutto a FdI e alla Lega dare le risposte che finora non si è saputo dare.”
Ci sei arrivato, ti ridico quello che ti avevo detto un anno fa: lascia la barca che affonda perché i vostri nemici interni la fanno affondare.
New Anthropic Science Blog: Making Claude a chemist.
To manipulate a molecule, chemists first need to understand its structure. Their main tool is NMR spectroscopy.
We found Opus 4.7 matches—and on some tasks beats—dedicated NMR software. Read more: https://t.co/1jUvz7wdhV
Great definition of RSI: "an AI system capable of fully autonomously designing and developing its own successor".
"We are not there yet."
Why not? "An area of human comparative advantage, for now, is research taste and judgment, including choosing which problems matter, which results to trust, and when an approach is a dead end."
Plenty of screenshots from the article being shared on social media, but take note: all of them are either about progress in engineering (*not* research) or about progress on well-defined or relatively minor research tasks.
Noteworthy that the headline from the tweet below ("It's happening faster than we thought") is nowhere to be found in the actual article.
None of this guarantees recursive self-improvement is on the horizon. It’s not yet clear that Claude is capable of research judgment—of choosing the right problems to work on.
But if these trends continue, AI systems designing and building their own successors is plausible. This could revolutionize society—medicine, technology, the economy—for the better. But it may also compound alignment issues and ultimately lead to loss of control.
The Anthropic Institute (in collaboration with external stakeholders) will conduct research to think through the implications of increasingly powerful, potentially self-improving systems—and how to create the ability for the world to make deliberate choices about the future development of the technology.
Read the full post: https://t.co/XkYALsONft
Our internal data shows Claude is accelerating AI development—a possible path to recursive self-improvement, or AI autonomously building a more capable successor.
It’s happening faster than we thought, and the implications deserve greater attention. https://t.co/OVVPJO7VQx
🧠 Most experts expect AGI before 2100, with a median forecast that it will occur by 2050
We asked respondents for the probability that, before 2100, more than 50% of LEAP panelists will agree that "AGI” exists. (We defined AGI as a commercially available AI system that outperforms the top human performance on the vast majority of non-physical work tasks; see details in report.)
The median expert assigns an 80% probability that the majority of LEAP panelists will agree AGI exists before 2100.
Conditional on this occurring, experts give 2050 as their forecast of the median year in which it will happen. Superforecasters gave a similar median probability (80%) and a slightly earlier median year of occurrence (2047).
AI can explain science better than it can forecast science.
Across 4,760 scientific events, the models were much better at recognizing possible research paths than forecasting actual outcomes.
Models often recognize a plausible research idea when the answer is already nearby, especially in multiple-choice form.
But they are much weaker at the harder thing: predicting whether a discovery will actually happen, when it will happen, and what method will make it work.
That means the models are still much better at hindsight than foresight.
When asked whether a scientific claim will actually be realized, the models hover near chance, and when asked when progress will arrive, they systematically push it too far into the future.
Even when the authors gave models extra older information, the models improved a bit but still did not become reliable at predicting future scientific progress.
So having lots of scientific knowledge inside a model does not automatically make it a good scientific forecaster.
----
Paper Link – arxiv. org/abs/2605.22681
Paper Title: "Forecasting Scientific Progress with AI"
“Immunotherapies are possible today only because thousands of scientists, for more than 40 years, followed their curiosity to probe the immune system’s deep processes.
Without basic scientific research, supported by the kind of farsighted public investment that allows large-scale, undirected, curiosity-driven inquiry, the scientific pipeline will run dry.” — MIT President Sally Kornbluth https://t.co/eO5X98XJNU
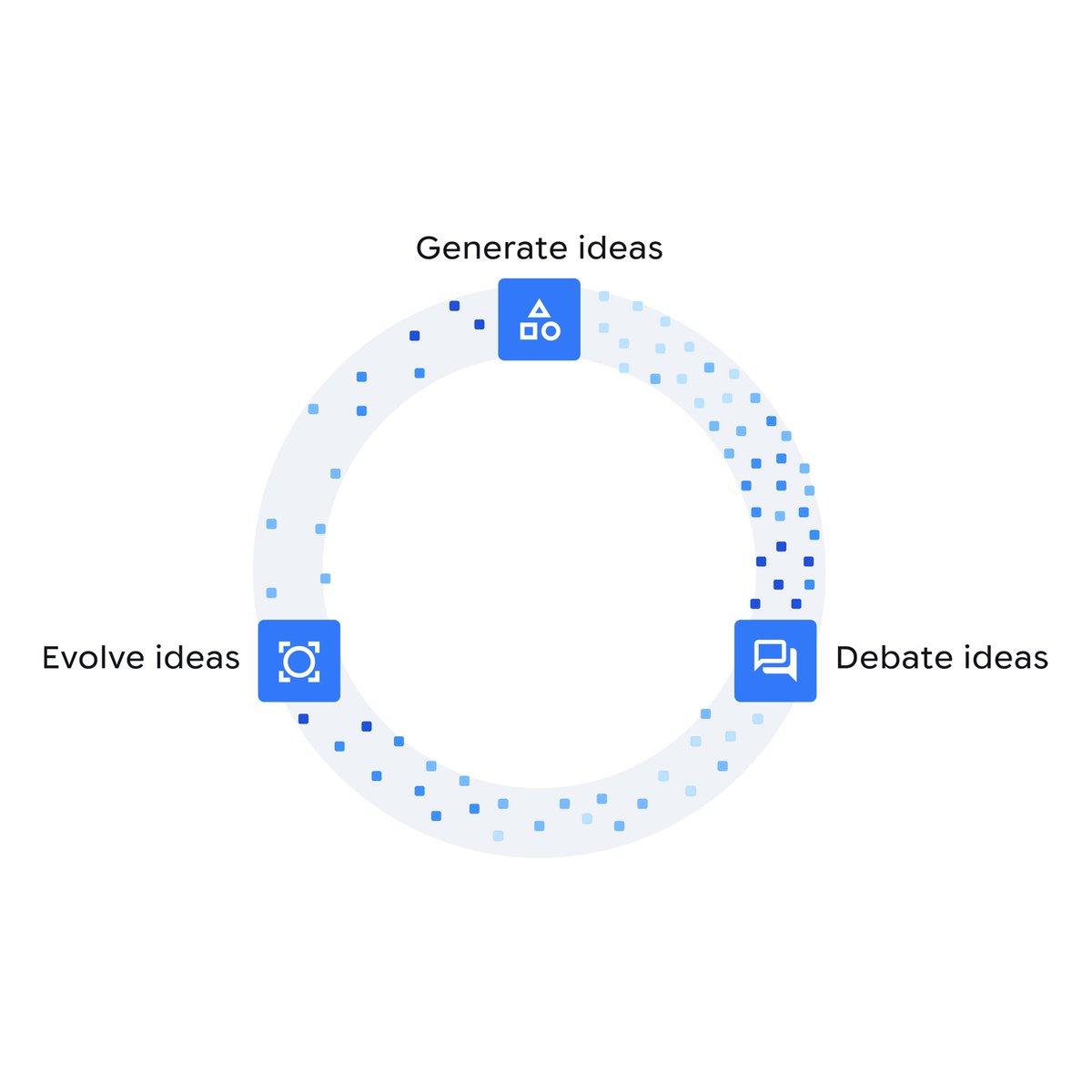
Co-Scientist can produce thousands of hypotheses.
To find the most useful, it relies on a “tournament of ideas” and holds scientific debates to refine and rank these. It can also verify claims against scientific literature and data, and use web search and specialized models to bring in new knowledge.
Scientific discovery is a cycle of ideation, critique, and refinement.
Co-Scientist mirrors this using a coalition of specialized Gemini-based agents leveraging its reasoning, multimodal, long-context and tool-use capabilities.
We believe AI can be a dedicated research partner to help discover the next breakthrough.
Enter Co-Scientist: our latest Gemini-based multi-agent system that can generate, debate and evolve novel hypotheses for complex scientific problems 🧵
Just saving this here to document a story and as a self reflection on whether AI is really making me more productive
Yesterday morning I found a way to complete the new HVM approach, that is much faster than before. I spent a few hours writing a spec, and then used Opus to implement. About 3k lines of C code later, everything worked and performance was incredible: 5x faster than HVM4 (stable at ~10x now). So, in one day I had outclassed HVM4. Incredible. I'd never have implemented that so fast manually.
Now, enter today. I want to turn this into a real thing, but I haven't fully read the 3k lines yet. So, how do I trust it? I spent the whole day auditing the code. With AI. Several bugs found, most minor like forgetting to collect() some argument. But then I stumble upon this:
λ{ inl: 1 ; inr: 1 }
This was a test. But wait. This is matching on inl/inr. So the branches should receive the value of the Either. But they were numbers instead. Numbers aren't functions. This makes no sense. So why this is a test?
It then stuck me. The AI completely misunderstood how function arities work. It literally assumed for no good reason that HVM5 was supposed to handle under/over-applied functions. For no good reason. I never wrote that. It never asked either. It just kinda thought "HVM is weird in some aspects, this might be one of them..." - and then it went on to implement a massive system to handle cases that should never happen to begin with. And all of that code is obviously wrong because it should not even exist. It is wrong. It is damage. And it is there.
But it isn't too bad either. I just told Opus that it was wrong. Perhaps not so politely. And it solved it just fine.
But then this begs the question. I spent ~20 hours in this file, and it is STILL not done. I went from 0 to 95% in the first 5 hours. Yet, 15 hours later, it is still not 100%. I suppose that is the real effect of using AI. If I had just written the C file manually in the last two days, would I not be further than where I am *right now*?
Surely, the first version would have taken much longer to drop. But when I'd finish writing all that code, there would be zero, literally zero retarded shit. And, just today, I caught 5 or 6 retarded shit. And the worst part is: I don't know what the number of retarded shit left is, but I'm afraid it is >0.
So if I have to read it all, review it all to ensure there is no retarded shit... what did I achieve by using AI, other than that dopamine anticipation?
This is incredible:
AI-related companies have issued ~$140 billion in investment-grade bonds year-to-date, accounting for 49% of the total IG issuance.
AI-related companies have also attracted ~$220 billion in venture capital funding year-to-date, making up 87% of the total.
This means nearly 9 in every 10 Dollars of VC funding has flowed into AI-related firms.
Furthermore, in high-yield corporate bonds, AI has accounted for 38% of total issuance, or ~$21 billion year-to-date.
Combined, AI companies have raised ~$380 billion across all three channels year-to-date, reflecting ~64% of all capital flows.
The AI investment boom is reshaping how capital is allocated across the entire financial system.
Google's Jeff Dean says LLMs are roughly a thousand times less data-efficient than humans
A capable human and a frontier model may reach similar capability, but the model needs around a thousand times more data to get there
"we really need to come up with algorithmic things"