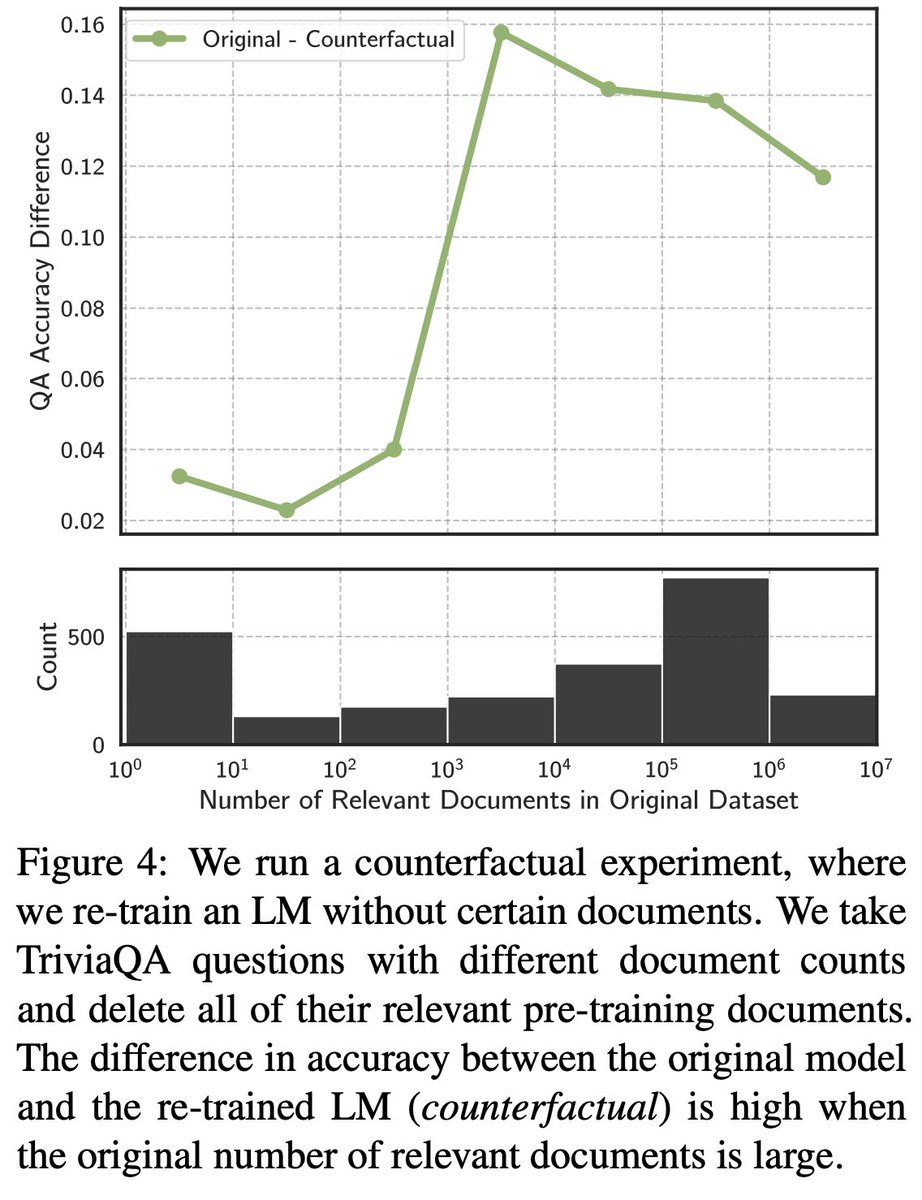
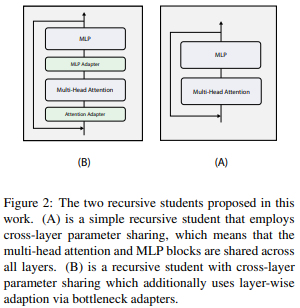
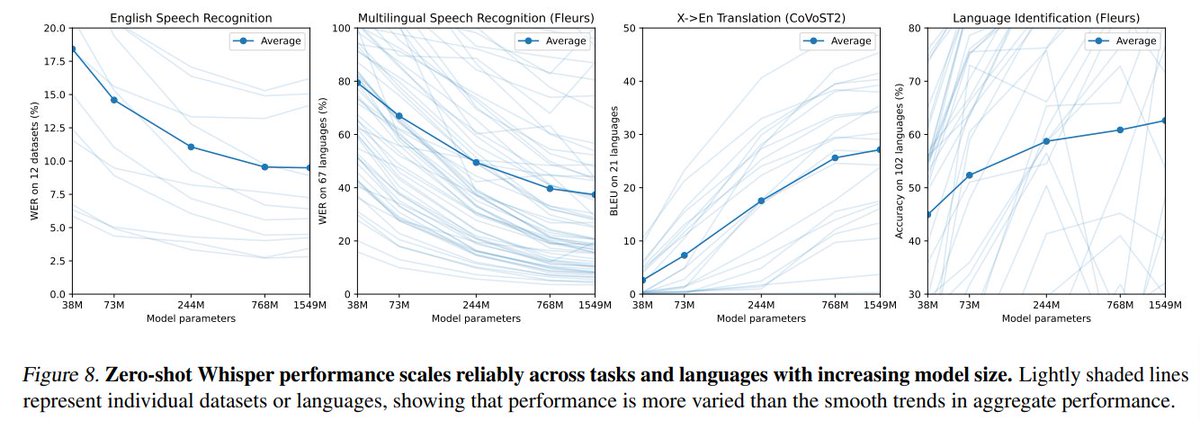
There are some really compelling results in this paper (some intuitive, some not so much). The causality analysis shows some non-linearity worth further investigation and further analysis of the effect of parameter counts may be warranted, assuming the true dynamic is sigmoidal.
Large Language Models Struggle to Learn Long-Tail Knowledge
by: Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel
https://t.co/4q5o1d1s5w
Overall, this work provides thorough and encouraging results for distilling pre-trained language models into recursive transformers. The idea of adding per-layer adaptors whilst re-using the MLP and Attention particularly interesting.
MiniALBERT: Model Distillation via Parameter-Efficient Recursive Transformers
by Nouriborji et at.
Proposes a method for distilling Bert-Style transformers into Albert-style recursive transformers.
https://t.co/dT1LeVzTpN
The authors find that distilling the model with adaptors, that are different for each iteration of the recursive block, improves performance across all tasks. The adaptors seem to help the layers better mimic the behaviour of the separate layers from the teacher.
Overall this was a refreshing work from OpenAI that shines light on often underappreciated aspects of ML -- dataset curation and generalization behavior! Models and code are openly available at: https://t.co/tFojb5itlF
This week we're highlighting the open-source Whisper speech recognition model outlined in "Robust Speech Recognition via Large-Scale Weak Supervision" by former Indico founder @AlecRad, @_jongwook_kim, @txhf, @gdb,
@mcleavey and @ilyasut.
https://t.co/uTUWWFqRvu
Finally, since a portion of the training examples were non-English audio transcriptions or non-English audio translated to English, the model can be used in these settings as well. Scaling trends show clear improvements from model scale, especially in multilingual settings.