Every SAST tool. Every security scanner. Every code quality checker.
They all answer the same question: "What vulnerabilities exist?"
That is not the fundamental question.
The fundamental question has never been answerable automatically.
Until now.
The draft guidelines for classifying high-risk AI are open for public comment until 23 June 2026.
That is a live window. Participation is possible right now.
Full article on Substack today.
https://t.co/l8JlNc02Ue
#AIGovernance#Compliance
The EU AI Act's non-retroactivity clause means AI systems deployed before the compliance deadline are permanently outside the Act's obligations.
Not temporarily exempt. Structurally unreachable.
The high-risk deadline just moved to December 2027. 16 months of gap.
The delay has a documented cause. 69% of European Commission meetings on AI were with business groups. 16% with civil society. 151 million euros in annual tech sector EU lobbying. 55% increase since 2021.
Source: Corporate Europe Observatory and LobbyControl, 2025.
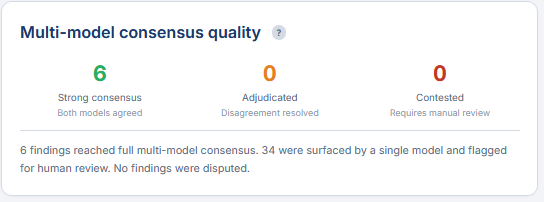
Add deterministic scanning on top of that, OSV and Semgrep, and you have something more defensible than a single-model review.
Not perfect. The article is honest about what it cannot claim to do.
Full piece at https://t.co/mwl83IEFqQ
#SoftwareSecurity#AIGovernance
If 42% of code is now AI-generated" With: "If 42% of committed code is now AI-assisted and your audit tool is also AI-powered, what exactly is being verified?
Are you asking one AI to approve the work of another AI with the same blind spots?
It is a fair challenge. Here is our appriach.
The answer is not that AI is reliable.
It is that architectural diversity changes the equation.
Multiple models from different providers, different architectures, different training data. Evaluated independently. A finding all three agree on carries different weight than a finding only one flags.
Your spec says role-based access controls are enforced across all features.
Your pentest passed.
Are you confident that claim is true across every data path shipped in the last six months?
How would you prove it?
https://t.co/5VSudQ8ech
South Africa drafted a national AI policy.
It was withdrawn 16 days later.
Reason: the citations in the reference list were fabricated. The journals cited did not exist.
A policy designed to govern AI, undermined by the AI governance failure it was meant to prevent.
https://t.co/izp79x12s3
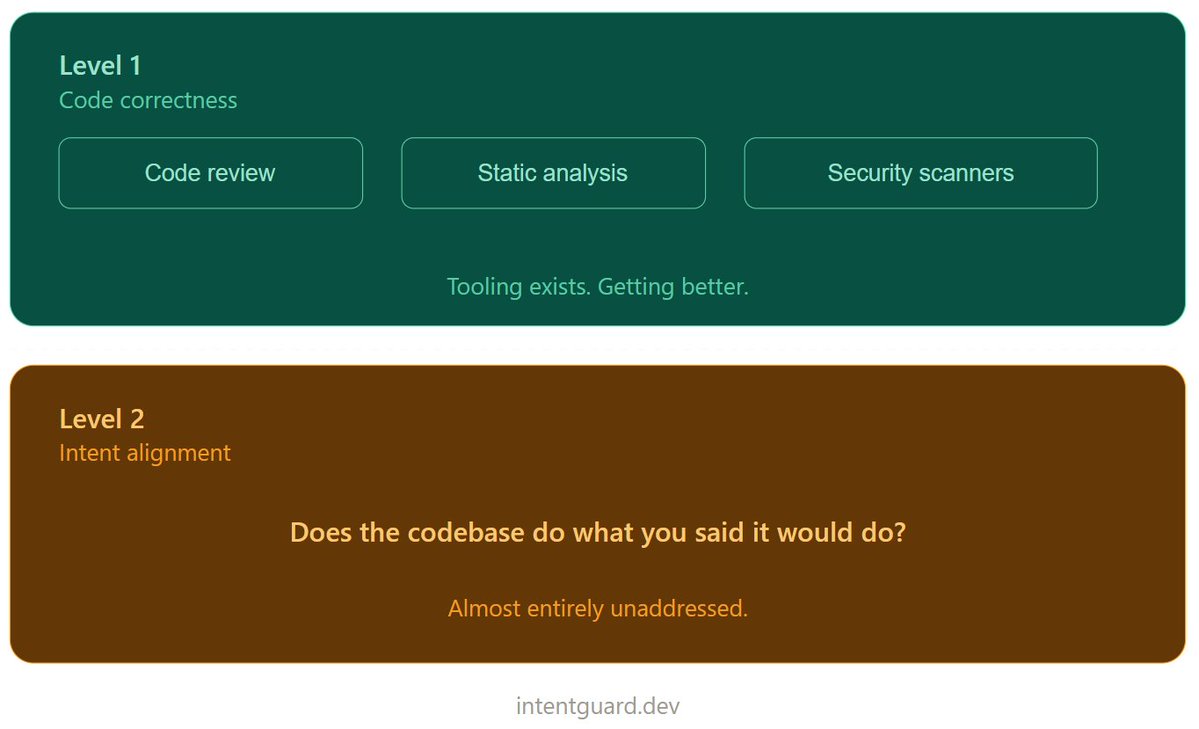
Most code review pipelines answer one question.
Is this code correct?
There is a second question almost nobody is systematically answering.
Is this the software you said you were building?
Different question. Different evidence requirement.
https://t.co/cTpMoLxons
#TechnicalDebt #AIGovernance
When a founder sits in a due diligence room, or an IT auditor maps a system to ISO 27001, the question is not whether functions pass their tests.
It is whether the system does what the product was declared to do.
That is the gap IntentGuard audits.
https://t.co/JDwrwYBTEv
#TechnicalDebt #AIGovernance
"Does your codebase do what you said it would do?"
Developer response, every time: "That is what unit tests are for."
It is not. Here is the difference, and why it matters.
Level 2 starts from what you declared externally.
To investors. To auditors. To customers. It asks: does the codebase actually reflect that declaration? A unit test cannot answer that. A UAT script cannot answer that. They were never designed to.