@syhily Curiously, I've had Opencode + K2.7 performing pretty well. Most tasks Go backend, a little flutter.
I break epics in decently-sized tasks with clear spec/goal/exit condit., 5.5-high review, avg score marginally > Opus 4.6 and < 4.8
@syhily Thx 4 sharing brother. Do you have any rough numbers on how well both providers perform in terms of cache reuse ratio / cache hit % with these models nowadays?
Also did you test only on CC or opencode / others as well?
@IplanRio_rj O mal do malandro é achar que todo buraco é cu, né parceiro?
Rouba sim o trabalho dos outros. Ninguém vai ligar não.
Aliás, fala aí do """"ataque hacker"""" de 2023
@wesbos It's not Opus, not Fable, not GPT 5.5-xhigh, but it's a goddamn good regular task driver. And it has the 1000tps fast api now on beta. I can't wait to try it.
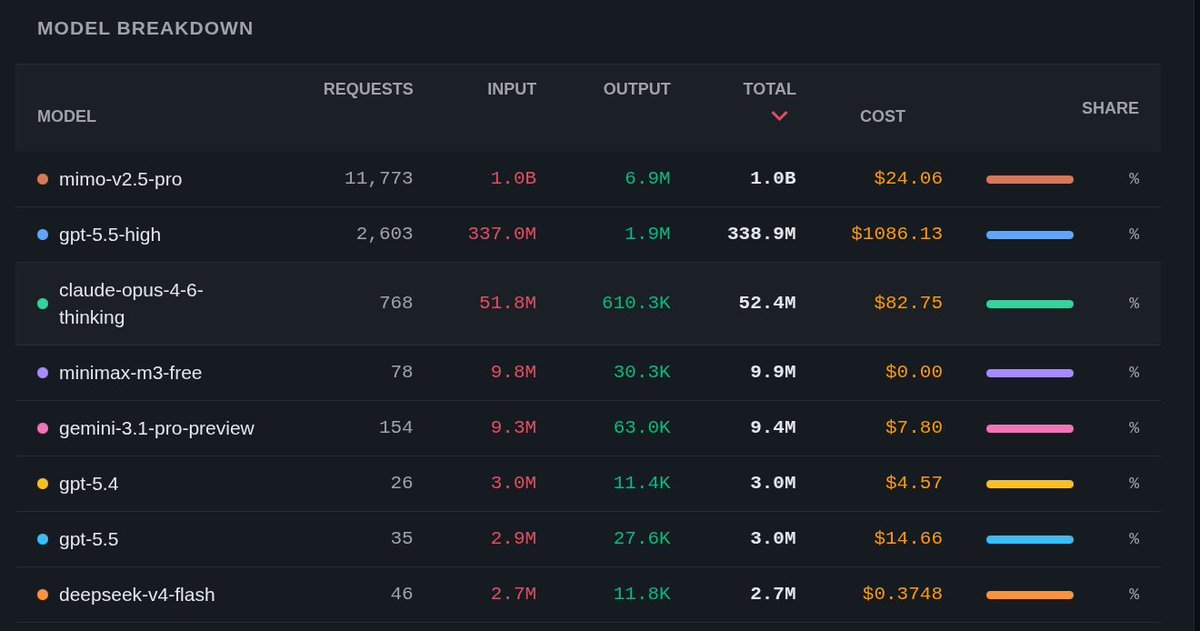
@wesbos I don't know what they put in the harness, but srsly, if you're looking for a cheap model for Hermes, mimo v2.5 pro is the best choice. 1 billion tokens (mostly input, research tasks) cost me US$ 24. Their cache is incredibly efficient provider-sided (ss: anthropic compat. api)
After using for a while, Kimi K2.7-code is the first OSS model that genuinely "feels like Opus" to me. I'm using it mostly for Go backend tasks, and 2.7 scored >= Opus 4.6 by 11% average, adv. reviewer GPT-5.5-xhigh.
@AkitaOnRails Akita, pergunta sobre o """"Ataque Hacker"""" de 2023, até hoje tem requerimento de informação parado lá esperando resposta. Vamo ver se vai aparecer algum palhaço defendendo.
@AkitaOnRails Se juntar todo mundo na merda do Iplan não dá o cérebro de um macaco, nem pra roubar o trabalho dos outros sem passar vergonha eles servem
@pupposandro Since december I've come to basically only use cheap models as main 'musclebuilders'. I leave gpt-5.5-high as reviewer, opus-4.6 or 4.8 as fixer, and constantly polish skills to improve bit by bit cheap models' accuracy based on reviews. Jackrong's FTs are ridiculously good now.