Introducing Realtime TTS-2, a new generation of voice model built for realtime conversation.
It is the first voice model that hears the conversation, takes natural-language voice direction, holds one voice identity across over 100 languages, and speaks like a person who is paying attention.
The result is voice AI that feels as good as it sounds.
Try it out: https://t.co/80xL7AJveV
Learn More: https://t.co/PLUiAEFizP
Portfolio Spotlight: Inworld AI
The most natural human interface is not a keyboard. It is voice.
As AI agents become the primary layer between humans and information, voice infrastructure becomes foundational.
That is why we backed @inworld_ai.
Realtime TTS-2 — now the top-ranked realtime TTS model on Artificial Analysis, ahead of ElevenLabs and OpenAI.
Talkpal: 5M language learners. Bible Chat: 800K DAUs, 90% TTS cost reduction. Little Umbrella: 3M hours of gameplay across 20M users.
When the voice feels right, everything built on top of it grows. 🎙️
Your voice clone just became a polyglot! Congrats!
Most people don’t realize a cloned voice can sound native in other languages.
Inworld’s voice localization makes it possible.
Select any voice you’ve cloned or designed. Click localize. Pick your target language. Choose the version you like best.
That’s it! Try it free on the Inworld platform. Link in bio.
With Inworld’s voice direction, you can guide your AI’s tone, pitch, and emotional delivery with natural language.
[speak with an angry, no nonsense tone] that’s it. You’re done.
Try it now in the Inworld Playground. Link in bio.
#tts#voiceai#agents
We told the Chloe voice to sound everything from supportive to flirty using natural language voice direction. That’s it, just instructions in brackets in plain English.
Our take on the “wow, ok” challenge, voice-directed.
Try it free in our TTS playground! Link in bio.
#wowok #wowokay #tts
Inworld Realtime TTS-2 just hit the @ArtificialAnlys leaderboard, claiming its spot as the top realtime TTS model in the world, and it's still in research preview.
6x faster to first audio than the next closest model.
Voice direction.
Text-based voice design.
100+ languages.
Conversational awareness.
And we're just getting started. Link in bio.
TTS-2 works out of the box with 25+ platforms and voice agent frameworks. You don't need complex custom integration, just plug it into whatever you're building and ship, ship, ship.
If yours isn't on the list and you want to build one, contact our partnerships team here: https://t.co/EE6L2u4WFc
You don't talk to your boss the way you talk to your best friend. You don't read a bedtime story the way you give a presentation. You just naturally shift your tone, your pace, your energy without even thinking about it.
Voice AI should work like that, but with most TTS, if you want a different mood or tone you need to swap to a whole different voice, which breaks experiences.
With TTS-2, you direct the voice the same way you'd direct an actor, in natural language. You just write something like [say warmly] or [speak with urgency through gritted teeth] before your text and the voice actually performs it.
Pitch, pacing, volume, emotion, all from a plain english instructions with no parameter tuning or voice swapping.
Try it out: https://t.co/BVWu7OyrNz
Fun story: Lore Machine's Korean-speaking user base exploded overnight. We didn't have the time to regionalize the entire app. With the help of @inworld_ai's Realtime TTS-2 model, tens of thousands of Korean users can now play their LOREs with Korean voice-over!
Congrats to @Thobey_Campion and the @lore_machine team on blowing up in South Korea!
Lore Machine is a US-based interactive storytelling platform that started seeing massive organic traction in South Korea. They needed to move fast to capture momentum but had to do so without having to spin up a full localization effort.
By integrating Inworld's Realtime TTS-2, they brought Korean voice-over support to tens of thousands of users almost immediately.
Can't wait to see where this goes next!
@faionur@AbstractVC@generalcatalyst@usv Congrats Fai and the Wishroll team! Watching you go from launch to 1M users to redefining what AI entertainment looks like has been incredible. Proud to power the AI models and infra behind Status. This is just the beginning!
Status has raised $17M in seed and Series A funding led by @AbstractVC, @generalcatalyst and @usv to let anyone step inside their favorite stories, become famous, and live a million different lives.
We quietly launched Status last year and grew to over 1 million users in 19 days - making us the fastest growing AI app since ChatGPT.
But we hit a (predictable) snag - the app was incredibly expensive to run. How do you serve millions of users without degrading the product with a cheap LLM?
So the team locked in: we rebuilt the whole experience, and our technical bets paid off. Our users now spend 35 minutes on average to (90 minutes each day for power users!), and millions of characters and worlds have been created. All by our users.
The next frontier of entertainment is mobile-first and deeply personal. Traditional mobile games take years to build and rarely stick. TV shows are fleeting in the age of streaming. Status is different. It is not a game you finish, it is a world you can live in.
Status is a new category entirely: Immersive Social Entertainment, and we believe strongly that it is the next great entertainment paradigm. We’ve 10x’d to millions in annual revenue in Q1 2026, we're just getting started.
On Status, you can be anyone.
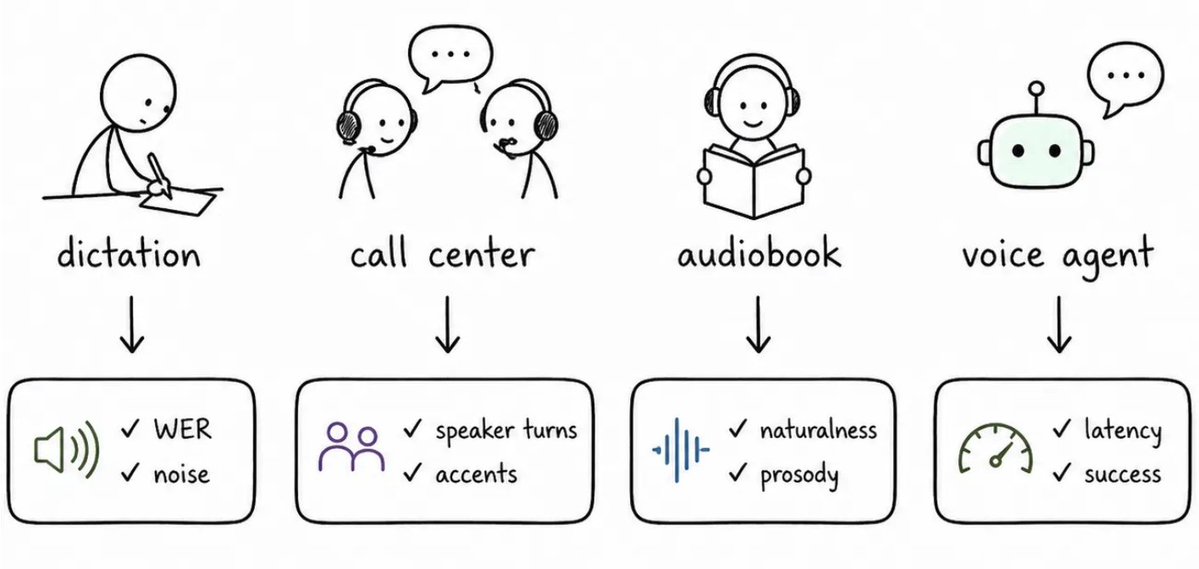
"We built four different metrics for 'conversational' before realizing nobody had agreed on what that word meant."
That's the whole problem with TTS evaluation right now. There's no single score that tells you if a voice model is good. It depends on the use case, the language, the latency requirements, the domain.
@altsoph our Head of Evaluations wrote up why the industry is grading these models wrong, and why "best for what exactly?" is the only honest question worth asking.
Learn more: https://t.co/tlTBc3JS92