Hasta başında kullanmak için kendi geliştirdiğiniz, vibe coding yaptığınız uygulamalarınız var mı?
Yarın başlayacak “Yapay Zeka ve Simülasyon” kongresindeki konuşmada uygulamanızı göstermemi isterseniz benimle paylaşabilir, bu postun altına yazabilirsiniz.
https://t.co/7yvxQU5yvW
Hasta başında kullanmak için kendi geliştirdiğiniz, vibe coding yaptığınız uygulamalarınız var mı?
Yarın başlayacak “Yapay Zeka ve Simülasyon” kongresindeki konuşmada uygulamanızı göstermemi isterseniz benimle paylaşabilir, bu postun altına yazabilirsiniz.
https://t.co/7yvxQU5yvW
Our new @NatureMedicine Perspective argues that uncritical use of #AI in early medical training may weaken independent clinical reasoning, and proposes a framework for integrating AI while protecting core competencies.
https://t.co/vAriiUhOk4
@NaturePortfolio@dukenus#DukeNUS
Fisher’ın Rothamsted Yılları
1919 baharında, 29 yaşında bir adam karısını, kayınvalidesini ve üç çocuğunu da yanına alıp Londra’nın kuzeyindeki kırsal bir çiftliğe taşındı. Şehirden uzak, açık tarlaların ve sessiz yolların ortasında yer alan bu yeni ev, aile için hem bir başlangıç hem de bir belirsizlik anlamına geliyordu. Kapının hemen yanı başında ise doksan yıllık deri ciltli not defterleriyle dolu bir tarımsal araştırma istasyonu duruyordu; yıllar boyunca toplanmış gözlemler, kayıtlar ve deneylerle dolu bu eski arşiv, çiftliğin günlük yaşamına neredeyse gölge gibi eşlik ediyordu.
Adam, Ronald Aylmer Fisher’dı.
Ve gidecek başka bir yeri yoktu.
İstatistik hakkındaki en keyifli kitaplardan Lady Tasting Tea pazar okumalarının 3.bölümünü aşağıdaki bağlantıdan okumaya devam edebilirsiniz.
https://t.co/co2qMZRrDr
https://t.co/bQhKnYE4kU
I’ve recently decided to no longer accept requests as a reviewer for scientific papers. Current top AI models do a better job than me for more than 95% of the review process, so with less than 5% effort, it would not be fair for me to take credit & journals don’t like it anyway.
Geçen hafta ICML 2026’nın yapay zeka kullanım politikasını ihlal eden hakemlerden gelen 497 makaleyi reddettiği haberi çıktı.
Yöntem akıllıca: makalelere LLM’nin göreceği ama insanın göremeyeceği gizli tuzak ifadeler yerleştirmişler. Hakem YZ kullandıysa, YZ bu ifadeleri review’a ekliyor. Suçüstü.
Şimdi asıl soruyu soralım:
Bu insanlar neden YZ kullandı?
Çünkü kötü niyetliler mi? Belki bazıları.
Yoksa çünkü ICML’e her yıl on binlerce makale geliyor, karşılıklı hakemlik zorunluluğu var, hakemlik ücretsiz, süresi kısa, sayısı fazla ve kimse teşekkür bile etmiyor?
Büyük ihtimalle ikincisi.
Sorun hakem tembel ya da dürüst değil.
Sorun yapısal: akademik sistemde hakemlik, gönüllü emeğe dayalı, teşviksiz, tanınırlığı olmayan, neredeyse cezalandırıcı bir yük haline geldi.
Araştırmacıları tuzağa düşürmek yerine şunu sorsaydılar daha ilginç olurdu: “Neden bu kadar çok insan politikayı ihlal etme riskini göze aldı?”
Bir de şu var: ICML aynı zamanda iki ayrı stream açtı: LLM kullanımına izin veren ve yasaklayan.
Yani organizasyon aslında şunu kabul ediyor: YZ kullanımı kaçınılmaz ve meşru olabilir.
O zaman biri bana şunu açıklasın:
Aynı LLM’yi makale yazmak için kullananın makalesi kabul ediliyor. Aynı LLM’yi hakemlik yapmak için kullananın makalesi reddediliyor.
Mantık tutarlı mı?
Kural ihlalini cezalandırmak meşru.
Buna itirazım yok.
Ama 506 kişi aynı anda aynı hatayı yapıyorsa, bu artık bireysel bir etik sorunu değil — sistem tasarımı sorunudur.
Watermark’ı kaldırın, kural ihlalini değil.
Asıl soruyu sorun:
Hakemlik neden bu kadar sürdürülemez hale geldi?
Akademik yayıncılık sisteminin kısa özeti:
Sen araştır. Sen yaz. Sen hakemlik yap. Sen editörlük yap.
Yayıncı %40 kâr marjı elde etsin.
Günde 5 gerçek hakemlik daveti alıyorum. Spam olanları saymıyorum bile.
Hepsini kabul etsem ne olur diye merak ettim ve hesapladım:
🌑 Yılda 1.825 makale.
🌑 Makale başına ortalama 7 saat.
🌑 Toplam 12.775 saat.
🌑 Bir yılda 8.760 saat var!
Yani “evet” desem, uyumadan, yemeden, nefes almadan çalışsam bile yetişemem.
Bunu fark edince sisteme biraz daha yakından baktım:
📌 Yaptığım her hakemliğin üniversite profesör maaşıma göre hesaplanan değeri yaklaşık 5.000–6.000 TL.
📌 Tüm davetleri kabul etsem yıllık maaşımın 6 katı değerinde emeği ücretsiz devretmiş olurum.
📌 Bu arada yazar, aynı makaleyi yayınlamak için 65.000–130.000 TL APC ödüyor.
📌 Elsevier 2023’te 3,6 milyar dolar kâr etti. Kâr marjı: %40. Google bile bu kadar kazanmıyor.
Nasıl mı yapıyorlar?
Çok basit:
∙İçeriği araştırmacı üretir. Ücretsiz.
∙Hakemliği araştırmacı yapar. Ücretsiz.
∙Editörlüğü araştırmacı yapar. Ücretsiz.
∙Yayıncı sunucuya yükler. Milyarlarca dolar alır.
Biz akademisyenler olarak bu sistemi sadece sürdürmüyoruz — biz bu sistemi bizzat çalıştırıyoruz.
Eleştirinin kolay, çözümün zor olduğunun farkındayım.
Benim çözümüm hakemlik davetlerini çok çok seçici kabul etmek. “Hayır” demek, bilimi terk etmek değil — zamanınıza saygı göstermektir.
Artık diamond open access dergilere submit edilen, Preprint sununan dergilerin hakemliklerini özellikle kabul ediyorum. Açık hakemlik platformlarına yorumlar yapmaya başladım.
Yılda 8–12 hakemlik yapmak hem etik hem sürdürülebilir hem de kaliteli bir katkı.
1.825 değil.
Siz kaç hakemlik daveti alıyorsunuz?
Ve kaçını kabul ediyorsunuz?
Aİ sayesinde çok yakında hasta vizitlerine “klinik mühendislerimiz” de katılabilir!
Bir asistan arkadaşım geçen hafta bana “Hocam, AI her şeyi yapıyorsa bizim işimiz ne kalacak?” diye sordu. Herkesi kedine de sorduğu gibi.
Yanlış soru.
Doğru soru şu: “AI her şeyi daha verimli yapıyorsa, biz ne kadar daha fazla şey yapabiliriz?”
Jevons Paradoksu’nu hatırlayalım.
1865’te William Stanley Jevons şunu fark etti: Buharlı motorlar kömürü çok daha verimli kullanır hale geldikçe, İngiltere’nin toplam kömür tüketimi azalmadı — aksine patlama yaptı. Verimlilik, talebi kısmadı. Talebi büyüttü.
Tıpta ve klinik bilimlerde tam bunu yaşıyoruz.
Bir yazılımcı bir günde kaç satır kod yazıyordu şimdi kaç satır yazıyor? Sınav için bir günde kaç soru taslağı hazırlayabilirdiniz şimdi kaç?Bir dersin taslak metnini oluşturmak kaç gün sürüyordu, şimdi kaç dakika? Bir slayt setine daha güzel slaytlar hazırlamak kaç gün alıyordu, şimdi kaç saniye?
Fazla mesai mi yapıyoruz?
Hayır tam aksine, aynı sürede.
Peki iş azaldı mı? O da tam tersi.
Klinik araştırmada veri temizleme, istatistik yazımı, literatür taraması saatler alıyordu. Şimdi dakikalar. Peki araştırmacılar daha az çalışıyor mu? Duyduğum kadarıyla herkes daha fazla proje üstleniyor, herkes Aİ ile yapmak istediği projeleri konuşuyor.
Ben de hem akademik hayatımda hem de @Akamedika’da bunu yaşıyorum. AI ile içerik üretim sürem dramatik biçimde kısaldı. Ama o kapasite boş zamana dönüşmedi. Yeni kurslar, yeni içerikler, yeni eğitim formatları için talebe dönüştü.
Hatta @drgokhanaksel hocamın geçen bana dediği gibi: Arog’da kaset ile Kung Fu yüklenen Arif gibi olduk!
Ne olduklarını 6 ay önce bilmediğimiz node.js, react ile webapp hazırlayıp tailwind, daisyUİ ile dizayn yapıyor, online databaseler ile serverless appler hazırlıyoruz. Yazılımcı bulamadığımız, bulsak da derdimizi anlatamadığımız, anlatsak da masrafını karşılayamadığımız işler 2 saatte yapılır oldu.
Ve işte burada ekiplerin yapısı değişiyor. Bu kaba taslakları gerçek ürünle dönüştürecek uzmanlara ihtiyaç var.
Hastane sistemleri artık “klinisyen + hemşire + sekreter” üçlüsünün yanına bir de klinik veri mühendisi gerektiriyor. Üniversite araştırma grupları biyomedikal bilişim uzmanı istihdam ediyor. Tıp fakülteleri eğitim teknolojisi geliştiricisi kadrosu açıyor.
Klinik ekiplere mühendisler katılıyor. Bunu 5 yıl önce ciddiye alan yoktu.
Bizim için ne anlama geliyor?
Klinik akademisyenler olarak iki seçeneğimiz var:
https://t.co/XL1b5o37lb’yi bir tehdit olarak görüp pasif kalmak.
2.Jevons’un dediği gibi: artan verimliği daha büyük problemlere yatırmak.
Ben ikincisini seçiyorum — ve çevremdeki en hızlı gelişen klinisyen-akademisyenlerin de öyle yaptığını görüyorum.
Yapay zeka rutin işi alıyor. Bize kalan, daha önce zamanımız ve bilgimiz olmadığı için yapamadığımız işler.
Bu bir kayıp değil. Bu, uzun süredir beklediğimiz fırsat.
Siz ekibinizde hangi yeni yetkinliklerin eksikliğini hissediyorsunuz? Yorumlarda görmek isterim.
Here’s the uncomfortable truth.
Debate only works when both sides share the same rules.
If someone is not trained in epidemiology, statistics, trial design, pharmacology, or immunology — and yet insists they can “tear apart” a paper — what they are usually tearing apart is their own misunderstanding of it.
Reading a paper is not the same as understanding it.
To interpret clinical research you need to know:
What constitutes appropriate controls
What statistical power means
Absolute vs relative risk
Confounding vs causation
Bias, multiplicity, subgroup fragility
Background incidence rates
Biological plausibility vs demonstrated effect
Without that framework, what happens is predictable:
They cherry-pick a sentence.
They confuse hypothesis with conclusion.
They elevate a limitation section into a refutation.
They mistake correlation for proof.
They declare victory.
Logic is useful. But logic applied to incomplete or misunderstood premises produces very confident nonsense.
“I’ve done my research” in these exchanges usually means:
I’ve read abstracts.
I’ve watched commentary about the paper.
I’ve searched for flaws without understanding the design constraints.
Medicine is not settled by rhetorical sparring on social media. It is settled by convergence of evidence across multiple methods, populations, and replications.
And here’s the deeper issue:
When someone demands, “Post a paper so I can dismantle it,” what they are really asking for is a performance arena. They are not participating in scientific inquiry. They are engaging in adversarial debate with asymmetrical incentives — you must defend every line; they need only sow doubt.
That is not how science progresses.
Science progresses by:
Publishing data.
Independent replication.
Methodologic critique by peers trained in the field.
Systematic review and meta-analysis.
Not by quote-tweet cross-examination.
There is a difference between healthy skepticism and recreational contrarianism.
The former advances knowledge.
The latter performs doubt.
And performing doubt is much easier than doing the work.
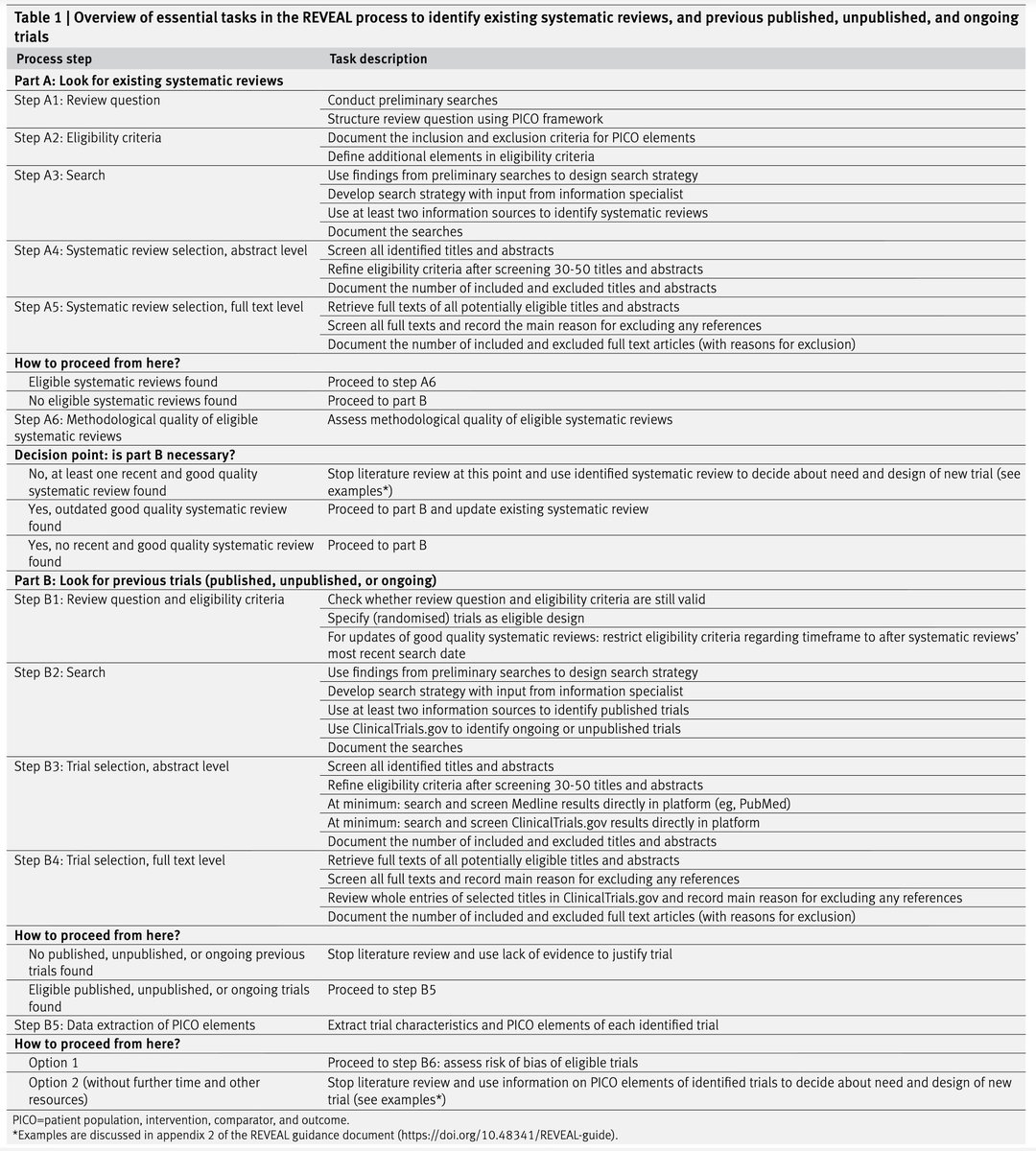
REVEAL: Yeni Bir Klinik Araştırma Planlıyorsanız, Mevcut Kanıtları Gözden Geçirmek İçin Artık Bir Rehberiniz Var
Yeni bir klinik araştırma planlarken mevcut literatürü sistematik olarak taramak olmazsa olmaz. Ama gerçekte ne yapıyoruz? Çoğu zaman birkaç tanıdık makaleye referans verip geçiyoruz. Sistematik derleme yapmak için ne zamanımız ne bütçemiz ne de metodolojik deneyimimiz yeterli oluyor.
BMJ'de bu hafta yayımlanan REVEAL (prior evidence for new trials) kılavuzu tam da bu soruna çözüm getiriyor.
Griebler ve arkadaşları, klinik araştırmacıların hızlı, sistematik ve uygulanabilir bir şekilde mevcut kanıtları tarayabilmesi için adım adım bir rehber geliştirmiş. Üstelik bunu ciddi bir metodoloji ile yapmışlar: sistematik literatür taraması, uzman paneli görüşleri ve gerçek kullanıcılarla usability testi.
REVEAL'in özü şu:
🔹 Part A — Önce konuyla ilgili mevcut sistematik derlemeleri arıyorsunuz. Güncel ve kaliteli bir derleme bulduysanız, durup onu kullanabilirsiniz.
🔹 Karar noktası — Bulunan derleme güncel değilse veya yeterli değilse Part B'ye geçiyorsunuz.
🔹 Part B — Yayımlanmış, yayımlanmamış ve devam eden bireysel çalışmaları (özellikle RCT'leri) arıyorsunuz. https://t.co/8Loj1f2c2H taraması da dahil.
Sürecin sonunda elinizde, önceki çalışmaların PICO özelliklerini özetleyen yapılandırılmış bir tablo oluyor. Bu tablo ile yeni araştırmanızın gerekçesini ortaya koyabilir, örneklem büyüklüğü hesaplamasına veri sağlayabilir, sonuç ölçütü seçiminizi bilgilendirebilir ve SPIRIT kılavuzunun 9a maddesini sağlam bir şekilde karşılayabilirsiniz.
Özellikle dikkat çekici bulduğum noktalar:
→ Tüm temel adımlar tek bir kişi tarafından yürütülebilecek şekilde tasarlanmış. Kaynak kısıtı olan ekipler için gerçekçi bir çözüm.
→ Zorunlu ve opsiyonel adımlar net olarak ayrılmış. Zamanınız varsa risk of bias değerlendirmesi ve meta-analiz de ekleyebilirsiniz.
→ Arama stratejisi için bir bilgi uzmanından (kütüphaneci/information specialist) destek alınmasını öneriyorlar — usability testlerinde araştırmacıların en çok zorlandığı adım bu olmuş.
→ Mevcut haliyle yapay zeka araçları önerilmiyor çünkü kanıt henüz yeterli değil, ama kullanacaklar için RAISE kılavuzuna yönlendiriyorlar.
Kılavuzun kendisi, yapılandırılmış rapor formu ve doldurulmuş örnek formu açık erişimle ücretsiz olarak sunuluyor.
Bence REVEAL, araştırma israfını önleme söylemini somut bir eyleme dönüştüren pratik bir araç.
📎 Griebler U, et al. BMJ 2026;392:e083718
https://t.co/enOqsVZoCG
@akamedika
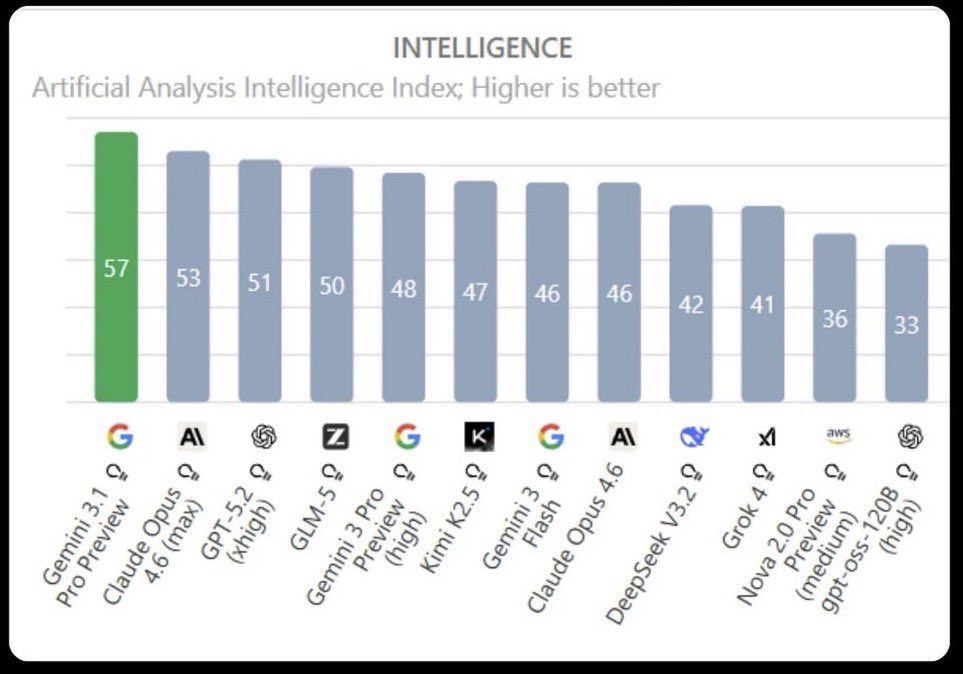
Artık nerdeyse her hafta bir #YZ model güncellemesi ve yeni benchmark sonuçları gelmeye başladı. Geçen hafta 13. Marmara Pediyatri Kongresinde paylaştığım bu analiz sosyal medyada bayağı yer bulmuştu. Yenileyerek sizlerle yeniden paylaşıyorum.
Hekim ve sağlık çalışanları için önemli benchmark sonuçlarını öne alarak yaptığım sıralamada Gemini'nin son modeli 3.1 thinking öne geçmiş görünüyor ✅. Çıktığından beri kullanımlarımda da gayet memnunum. Araştırma, tarama, analiz ve metin taslakları hazırlığında #Claude ve #Gemini arasında gidip geliyorum ama GPT bu işlerde gündelik rutinimden çıktı.
✅ #NotebookLM kontrollü içerik gerektiren işlerde olmazsa olmazım.
✅ Microsoft Ofis programlarından da Google Ofis programlarına geçmeye başladım. Gemini ile entegrasyon çok kritik avantajlar getiriyor.
Benim gibi tech-savvy poweruserlar için de bir önerim var: Hostinger üstünde VPS kurup içinde #OpenClaw çalıştırarak tüm otomasyon ve rutin işleri Telegram üstünden yaptırmak paha biçilmez bir dönüşüm oldu benim için.
Kod öğrenemedim hiç diye onlarca yıl kendi kendimize hayıflanırken, YZ'nin gelişiyle bir anda dünyaya düşmüş kriptonlu gibi olduk hepimiz 😃
@akamedika
Gemini 3.1 Pro’ya panellerimizden ulaşmaya başladık. 2 hafta önce Claude opus 4.6’nın chatgpt’den devraldığı taht şimdi gemini’de.
Sadece son 6 ayda humanity’s last exam skoru nerdeyse yarı yarıya arttı. MedQA gibi benchmark testleri artık her modelde %95’in üstünde, YZ usmle sınavını geçer mi sorusunun bir anlamı artık kalmadı.
Pazartesi üniversitemizin sağlık bilimleri enstitüsü yüksek lisans öğrencileri ile buluşuyoruz. 120’den fazla kaydımız var. Genç akademisyenlerin bizleri sıkıştırıp zorladığı bu eğitimler benim için her zaman en keyiflileri oluyor.
Betül ve Ahmet hocam gibi marka isimlerle bir arada olmak zaten apayrı bir keyif.
@marmara1883
Chrome + Gemini 3 ile neler geliyor?
✅ Yan Panel: Her sekmede yanda açıp sayfayla ilgili gemini ile çalışabiliyoruz.
✅ Auto-Browse: Seyahat planlama ve form doldurma gibi çok adımlı işleri otomatik yapıyor.
✅ Nano Banana: web’deki görüntüleri chromedan çıkmadan anında dönüştürebiliyoruz.
Bu özellikle Aİ Pro ve Ultra aboneleri için ABDden başlayarak aktive edilmeye başlandı.
#Chrome #GoogleAI #TechNews
İnternette gezinme deneyimi çağ atlıyor! 🚀
Google, Chrome için en zeki modeli olan Gemini 3 tabanlı yeni özellikleri duyurdu.
Artık "Auto-Browse", karmaşık görevleri (uçuş araştırma, form doldurma vb.) sizin yerinize Chrome bir asistan gibi halledebilecek. 🌐✨
#GoogleChrome #Gemini3 #AI #AutoBrowse
Gündelik mesleki yaşantımızda sık kullandığımız ChatGPT, Gemini ve Claude için sık sorulan sorularınıza yanıtlar içeren bir video hazırladım.
https://t.co/F7yAah6sNz
- Yapay zeka araçlarından hangisi hangi konuda önde?
- Hangi iş için hangi aracı kullanmalı?
- Her birinin kısıtlılıkları neler?
Bu konuların cevapları ve bizim tercih ettiğimiz araçların neler olduğunu paylaştığımız videolarımızı youtuba kanalımızdan izleyebilirsiniz.