This Week in Inference: Anthropic's Claude Fable 5 drops at $50/M output tokens, making cost-efficient routing the only rational response. Plus 3 more stories. Thread
This Week in Inference: an enterprise burned $500M on Claude tokens in 30 days because nobody set a usage cap. Agentic workflows cost up to 1000x more tokens than basic chat. Plus 4 more stories. Thread
For a long time our training goals @ZyphraAI had been to just match dense transformers, but with faster inference and lower training cost.
Today we also surpass them with Zamba2-7B.
1) RAG often struggles on complex multi-hop queries. In this blog, we @ZyphraAI discuss and build a graph-based RAG system which tops the leaderboard on a QA benchmark with multi-hop queries and outperforms frontier long-context models for 60x less cost.
https://t.co/QDXUdiWzh5
@ylecun Thanks for sharing! Another little trick that might amuse you is that we identified a function which upon minimization produces the forward pass of the attention block:
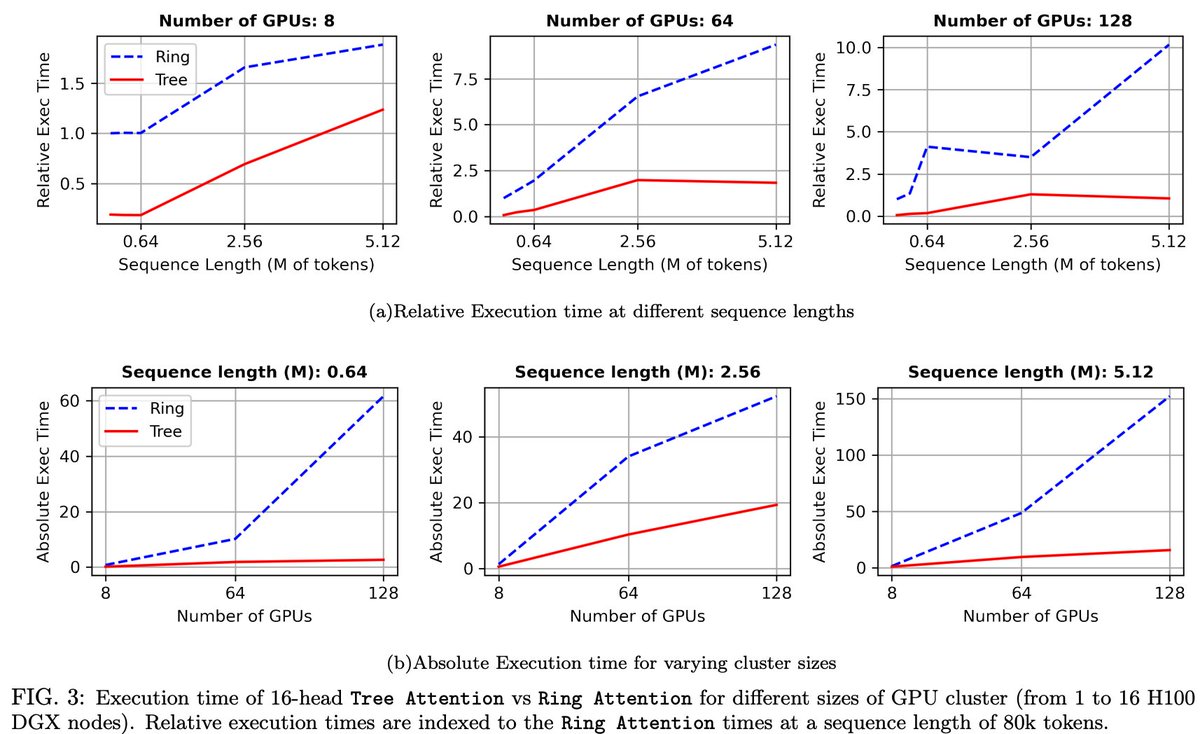
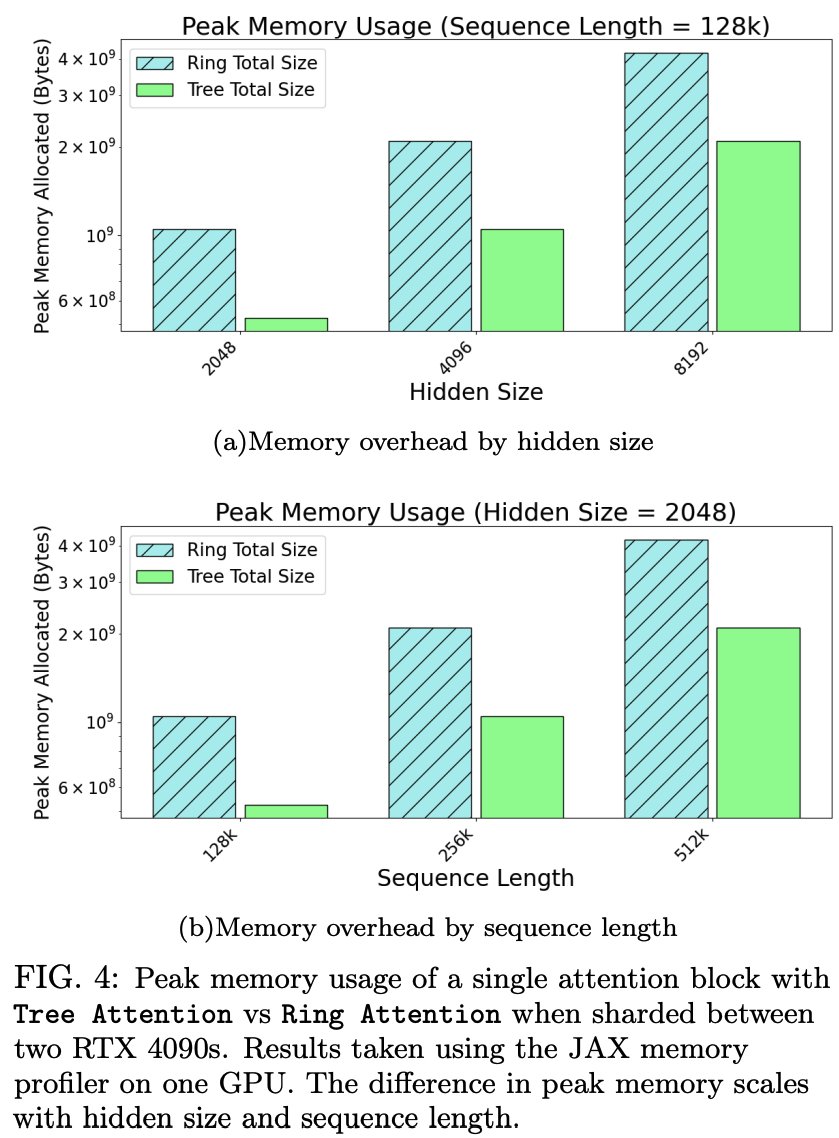
Zyphra is proud to release Tree Attention, a fast inference method for extremely large sequence lengths
• 8x faster inference speed vs. Ring Attention
• 2x less peak memory
• low data communication volumes
Paper: https://t.co/yf5VNRze6W
Code: https://t.co/Th6Fg8eFEr
A 🧵
By using the two-level interconnect topology on GPU clusters, Tree Attention allows for asymptotically faster decoding as we scale output sequence length and number of GPUs in a cluster and lower peak memory requirements:
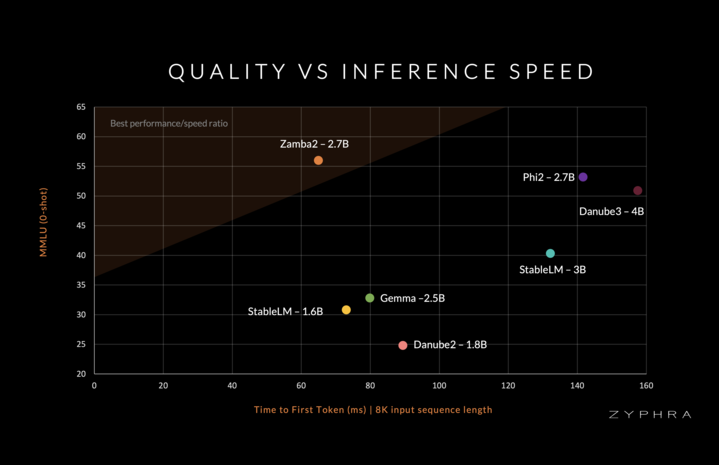
Zyphra is ecstatic to release Zamba2-small:
- 2.7B Mamba2/Attention hybrid
- Pre-trained on 3T tokens + annealed on 100B high-quality tokens
- Model released on HuggingFace and standalone PyTorch
- SOTA evaluation performance and superior inference efficiency.
https://t.co/uToHut7FPB
https://t.co/MN7cwNcQzc
https://t.co/Tdz0BjgMGV
Hyped to share JaxPruner: a concise library for sparsity research.
JaxPruner includes 10+ easy-to-modify baseline algorithms and provides integration with popular libraries like t5x, scenic, dopamine and fedjax. 1/7
Code: https://t.co/tPwCL03xnE
Paper: https://t.co/eedLJj5EVW
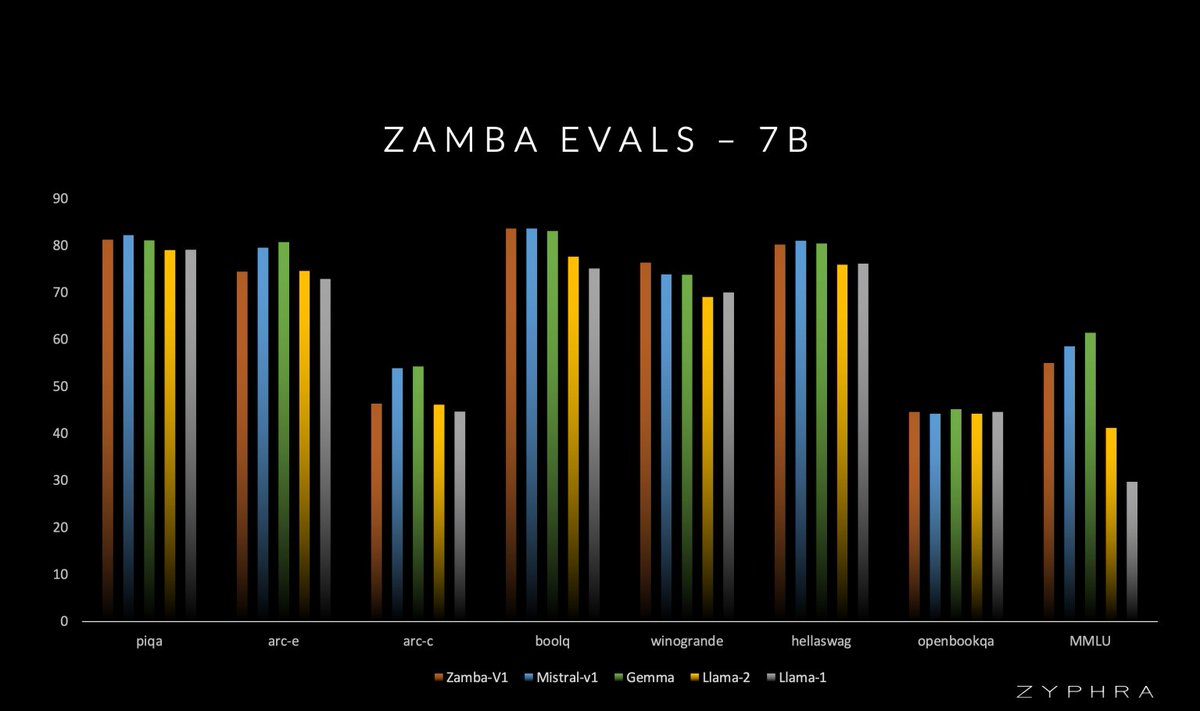
Zyphra is pleased to announce Zamba-7B:
- 7B Mamba/Attention hybrid
- Competitive with Mistral-7B and Gemma-7B on only 1T fully open training tokens
- Outperforms Llama-2 7B and OLMo-7B
- All checkpoints across training to be released (Apache 2.0)
- Achieved by 7 people, on 128 H100 GPUs, in 30 days
- https://t.co/eOhhSNGJDc
- https://t.co/1horXuTOj0
Want more details? A 🧵
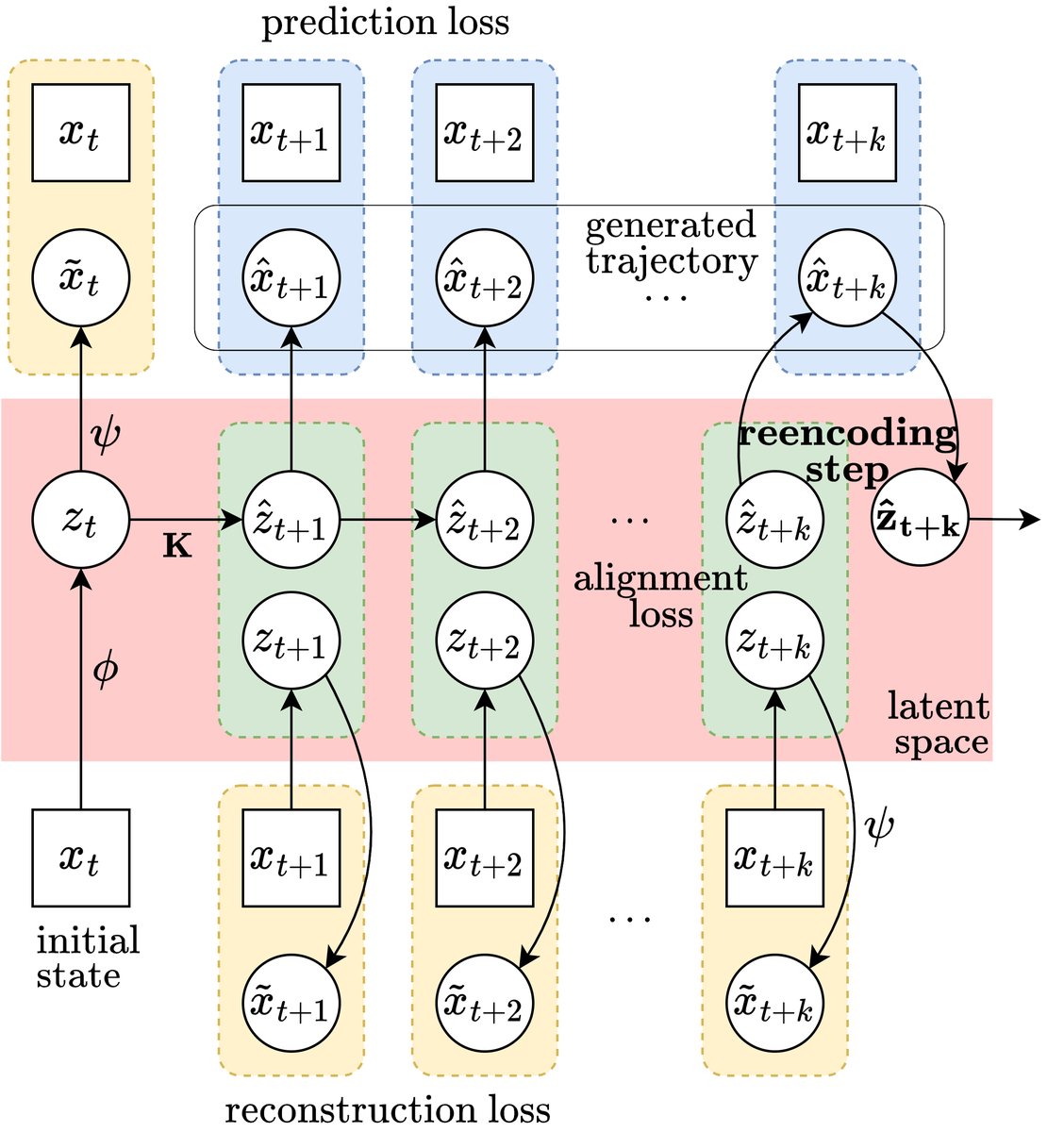
Course Correcting Koopman Representations
Accepted at #ICLR2024!
We identify problems with unrolling in imagination and propose an unconventional, simple, yet effective solution: periodically "𝒓𝒆𝒆𝒏𝒄𝒐𝒅𝒊𝒏𝒈" the latent.
📄 https://t.co/ULNzqAV3bB
@GoogleDeepMind
1/🧵
My research group @kasl_ai is looking for interns!
Applications are due in 2 weeks ***January 29***.
The long-awaited form: https://t.co/hLOjuxSfnK
Please share widely!!
I like the SSM/hyena/Block State Transformers
https://t.co/SDAT6V5mXB
https://t.co/yIODAIHGlM
They remind me of Q-RNNs https://t.co/H2I48lapT7 and play around with different parallelization ideas.
I don't think transformers are that special and there are many equivalent architectures.
@MahanFathi Excited to present our work (Block-State Transformers) at #NeurIPS2023 Great Hall & Hall B1+B2 (level 1) no. 817. Please join us in the poster session between 5PM and 7PM CST today!
Why not get the best of both worlds by combining SSMs and Transformers?
Excited to share our work at #NeurIPS2023: "Block-State Transformers."
BST hits new highs in long-range language modeling and LRA tasks.
paper: https://t.co/nHt6OGyez1
1/