ARC and @aicrowdHQ are launching a ≥$100k contest for white-box estimation algorithms: given the weights of an MLP, the goal is to estimate the expected output of the network on Gaussian inputs. (Thread)
It's rare to find good, easily-measurable metrics for progress in alignment. But we are cautiously optimistic that top submissions will produce ideas that meaningfully advance our research.
Could an AI company lose control of its own agents? To find out, Anthropic, Google, Meta, and OpenAI let us (1) test their best internal models with CoT access, (2) review non-public info about capabilities, alignment, and control.
The result: our first Frontier Risk Report.
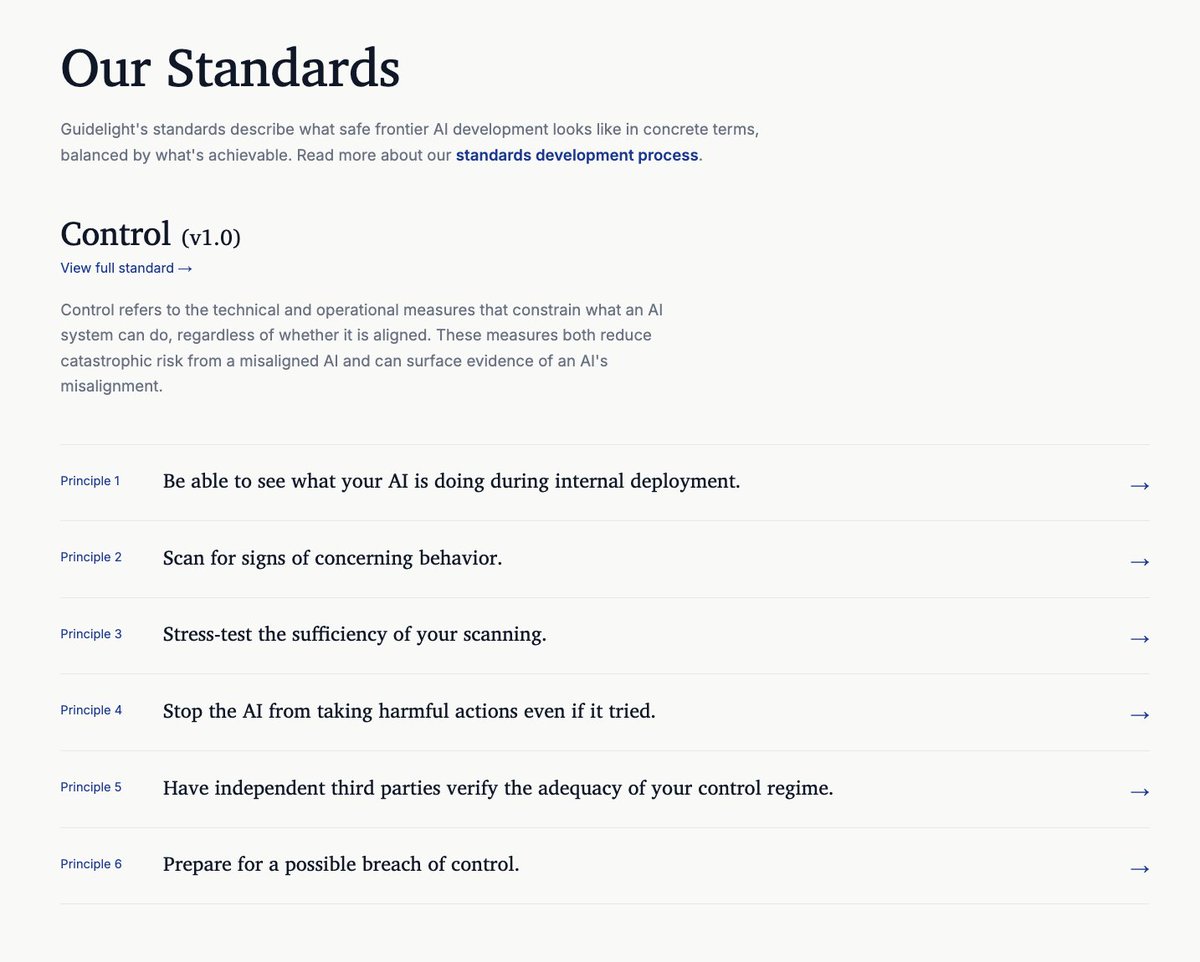
Some personal news: I've started a new AI safety standards org, and our first two standards are out today.
We're called Guidelight, co-founded with fellow ex-OpenAI safety researcher, Page Hedley. (1/n)
Can you estimate the average behavior of a neural network without running it? In ARC's latest paper, we address this question for wide randomly-initialized MLPs with Gaussian inputs. (Thread)
Congrats to first author Wilson Wu, as well as my other coauthors @vclecomte, Mike Winer, George Robinson and @paulfchristiano.
Paper: https://t.co/qs6q3MWjPD
Blog post: https://t.co/kowNfZbr4Y
Our current approach works at the start of training, but we have a lot more work to do to produce methods that work throughout training (even for small models like the AlgZoo models we shared a few months ago).
@bzogrammer@davidad Although note that we only ever unroll the RNN for 10 steps (and there is a fresh input changes at each step), so no fixed point is ever actually reached!