Polyscope - the free agent orchestration tool for developers.
Run dozens of AI agents at the same time, blazing fast copy on write clones, a built-in preview browser you can use to visually prompt your agents, mobile access, and much more.
Something unexpected, and slightly worrying, is happening.
Ten days ago, I posted a preprint introducing the concept of LLMorphism: the biased belief that human cognition works like a large language model.
The preprint received an unusual amount of attention.
Hundreds of comments on social media and forums.
Reels on Instagram and TikTok.
YouTube videos.
Infographics for students.
And now it has even made it to Forbes.
It seems that I got some sort of zeitgeist.
Many people were already thinking about this.
Many people had already experienced it.
But they were missing a name and a theoretical framework.
So, here it goes:
LLMorphism is what happens when people start to see themselves as language models.
The psychological mechanism is analogical trasfer combined with metaphorical availability: LLMs become an available metaphor for cognition, and people project that metaphor back onto themselves.
The machine becomes the model of the human.
And this worries me because the risk is not only that we overestimate machines.
It is also that we underestimate ourselves: our embodied experience, our goals, our emotions, our responsibility, and our capacity for understanding.
*
Full paper in the first reply.
Hayatını sikeyim Dario Amodei ya 3 kuruş daha al da quantize etme şu siktiğimin modellerini ya Jews are NOT going to beat the allegations amınakodumun tırnakçısı
Solo dev reverse-engineered Google's billion-dollar algorithm in 7 days
Google published the paper that crashed memory stocks worldwide. Then shipped zero code.
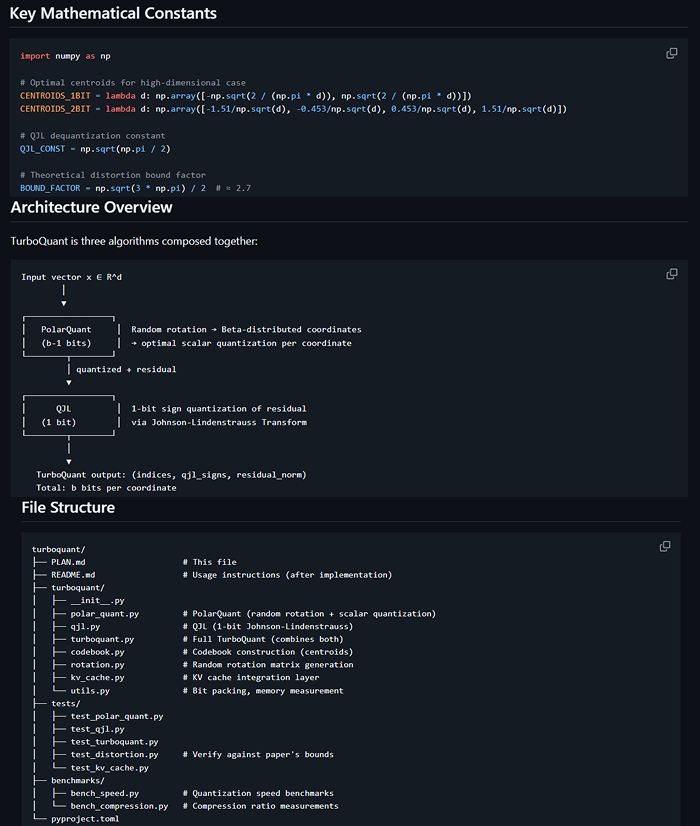
Tom Turney read the math, opened his terminal, and built the whole thing with Claude - then made it faster than Google promised.
Day 1-3: Core algorithms, 141 tests, Python prototype
Day 3-5: C port into llama.cpp, Metal GPU kernels
Day 5-7: Speed optimization from 739 to 2747 tok/s
That's a 3.7x speedup through pure engineering:
> fp32 → fp16 WHT
> half4 vectorized butterfly ops
> graph-side rotation
> block-32 storage layout
Then he added his own research on top:
> Sparse V: skip 90% of value decompressions at long context
> Asymmetric K/V: keep keys precise, compress values harder
> Temporal decay: old tokens get lower precision automatically
Result: 35B model running on a MacBook with 4.6x compressed cache.
613 GitHub stars in a week. Google still hasn't released their own code.