Life update: After ~2 years at @Google Brain/DeepMind, I joined @AnthropicAI!
I'm deeply grateful to @quocleix and @yifenglou for taking a chance on me and offering me to join their team before I even finished my undergrad at Stanford. Because of their trust in my potential, I've had the unique opportunity to work on LLM reasoning/factuality with many top researchers.
Some lessons I'll carry forward:
1. Building a top-tier model requires reliable evals.
2. When results don't match expectations, your first instinct should be to look at the data and the model outputs.
3. Playing a minor role in a groundbreaking project is better than playing a major role in an incremental project. Focus on the impact of a project rather than how much credit you'll receive.
4. Being open to criticism and actively asking others to help improve your ideas makes you a better researcher than most.
5. Feedback that is actionable is more likely to be well-received.
6. Optimizing for density of talent is often more effective than optimizing for total quantity of talent.
7. Talking to people outside your area of expertise can let you have ideas that you otherwise might have missed.
8. Remember to write unit tests when building complex systems. You may catch a bug that leads to noisy results.
9. Pair programming is extremely useful, particularly when you first start a new project or work in an unfamiliar part of a codebase.
10. Proactively offering help is how I made my most-memorable friendships!
I'm eager to learn from the amazing team of researchers at Anthropic to continue advancing AI safety as we get closer to AGI! 🤔🤖🌎
UK AISI have been great collaborators that have helped us improve our safety systems by identifying weaknesses in existing defenses. This is a great opportunity to make meaningful impact on deployed safety across the industry!
The Red Team at @AISecurityInst is hiring! We work with frontier AI companies to red team their misuse safeguards, control measures, and alignment techniques. As the stakes rise, we need much stronger red teaming and many more talented researchers working within gov 🧵
The recent events on holding our red lines on mass surveillance and fully-autonomous weapons is, to me, the most-apparently obvious example of Anthropic's ability to stick to our values instead of discarding them for some commercial gain. I'm really proud to be part of a company that holds its ground on its morals and that understands the stakes of the technology that's being built.
An idea that sometimes comes up for preventing AI misuse is filtering pre-training data so that the AI model simply doesn't know much about some key dangerous topic. At Anthropic, where we care a lot about reducing risk of misuse, we looked into this approach for chemical and biological weapons production, but we didn’t think it was the right fit. Here's why.
I'll first acknowledge a potential strength of this approach. If models simply didn't know much about dangerous topics, we wouldn't have to worry about people jailbreaking them or stealing model weights—they just wouldn't be able to help with dangerous topics at all. This is an appealing property that's hard to get with other safety approaches.
However, we found that filtering out only very specific information (e.g., information directly related to chemical and biological weapons) had relatively small effects on AI capabilities in these domains. We expect this to become even more of an issue as AIs increasingly use tools to do their own research rather than rely on their learned knowledge (we tried to filter this kind of data as well, but it wasn't enough assurance against misuse). Broader filtering also had mixed results on effectiveness. We could have made more progress here with more research effort, but it likely would have required removing a very broad set of biology and chemistry knowledge from pretraining, making models much less useful for science (it’s not clear to us that the reduced risk from chemical and biological weapons outweigh the benefits of models helping with beneficial life-sciences work).
Bottom line—filtering out enough pretraining data to make AI models truly unhelpful at relevant topics in chemistry and biology could have huge costs for their usefulness, and the approach could also be brittle as models' ability to do their own research improves.* Instead, we think that our Constitutional Classifiers approach provides high levels of defense against misuse while being much more adaptable across threat models and easy to update against new jailbreaking attacks.
*The cost-benefit tradeoff could look pretty different for other misuse threats or misalignment threats though, so I wouldn't rule out pre-training filtering for things like papers on AI control or areas that have little-to-no dual-use information.
Excited to share our latest research on making AI systems more robust against jailbreaks! 🚀
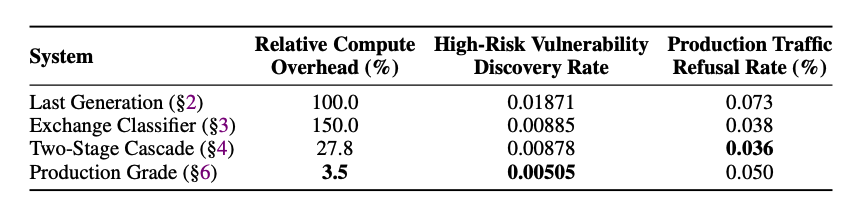
Last year, our team at @AnthropicAI developed Constitutional Classifiers to defend language models against jailbreaks. While the system was robust, it came with high computational costs and non-negligible over-refusal rates. Today, we're publishing a paper on our improvements:
1. 30x+ reduction in computational cost
2. ~4x improvement in robustness to jailbreaks
3. ~50% reduction in over-refusals
As AI systems grow more capable, we hope our methodology helps researchers across the industry implement safeguards against misuse without incurring unreasonable computational costs or blocking legitimate use cases.
New Anthropic Research: next generation Constitutional Classifiers to protect against jailbreaks.
We used novel methods, including practical application of our interpretability work, to make jailbreak protection more effective—and less costly—than ever.
https://t.co/5Cl2LaEyoI
Anthropic has a bug bounty program for our safety mitigations, e.g. on CBRN risks which our responsible scaling policy requires us to mitigate effectively.
If you're interested in this, please sign up! You can help AI safety and earn money by breaking our defenses. 👇
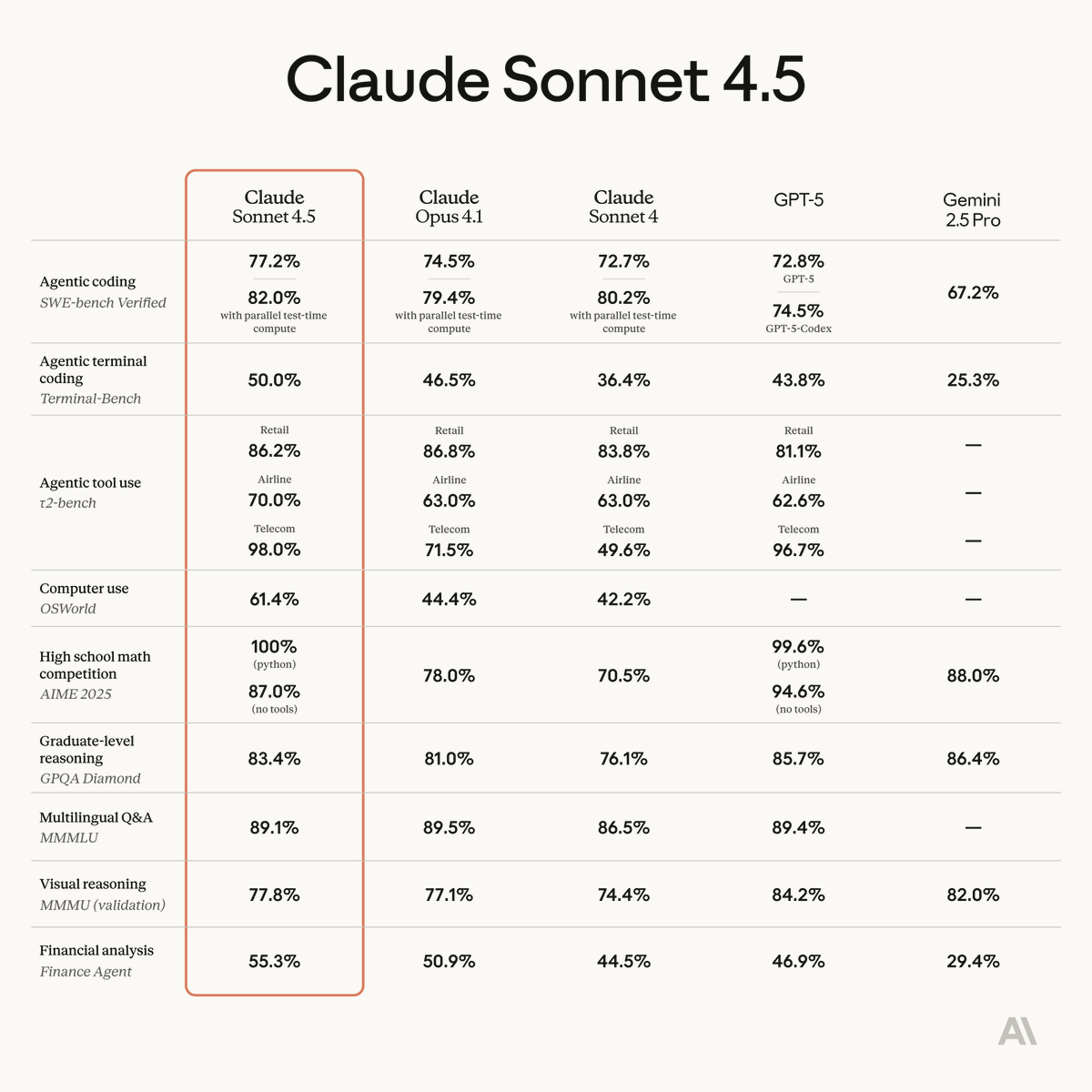
Introducing Claude Sonnet 4.5—the best coding model in the world.
It's the strongest model for building complex agents. It's the best model at using computers. And it shows substantial gains on tests of reasoning and math.
Today marks my one-year anniversary at Anthropic, and I've been reflecting on some of the most impactful lessons I've learned during this incredible journey.
One of the most striking realizations has been just how much a small, talent-dense team can accomplish. When I first joined, I was surprised by how lean many of our teams were, but I quickly learned this was a feature, not a bug. With a concentrated group of exceptional researchers all aligned on the same goal, the speed of iteration and quality of output is extraordinary. I've seen teams of 3-4 people ship things in weeks that I would have expected to take months with larger groups. There's something magical about having everyone deeply engaged, with no room for diffusion of responsibility or communication overhead.
Another lesson that's been reinforced time and time again is the critical importance of evals, and not just having them, but constantly pushing them forward. Early on, I watched as eval sets we thought would last for months got saturated in weeks as our models rapidly improved. This taught me that investing in harder, more comprehensive evals isn't just helpful, it's essential. The moment you think your evals are "good enough" is the moment you start flying blind. I've come to see eval development as equally important as model development itself, because without reliable measurement, you can't make reliable progress.
Perhaps the most counterintuitive lesson has been that the work with the highest impact often isn't the most glamorous. There's always a pull toward the "sexy" projects - the ones that get talked about at conferences or generate buzz internally. But I've found that some of my most meaningful contributions have been on the unglamorous but critical infrastructure or on tooling improvements that work in the background to save researchers' time. These efforts might not immediately get recognition, but when you step back and look at the compounding effects, they often move the needle far more than any flashy demo.
Looking back on this year, I'm grateful not just for these lessons but for the environment that made learning them possible. Being surrounded by colleagues who embody these principles, who choose impact over recognition, who obsess over measurement quality, and who believe in the power of focused teams, has shaped how I approach my own work. Here's to another year of learning, building, and pushing the boundaries of what's possible with AI!
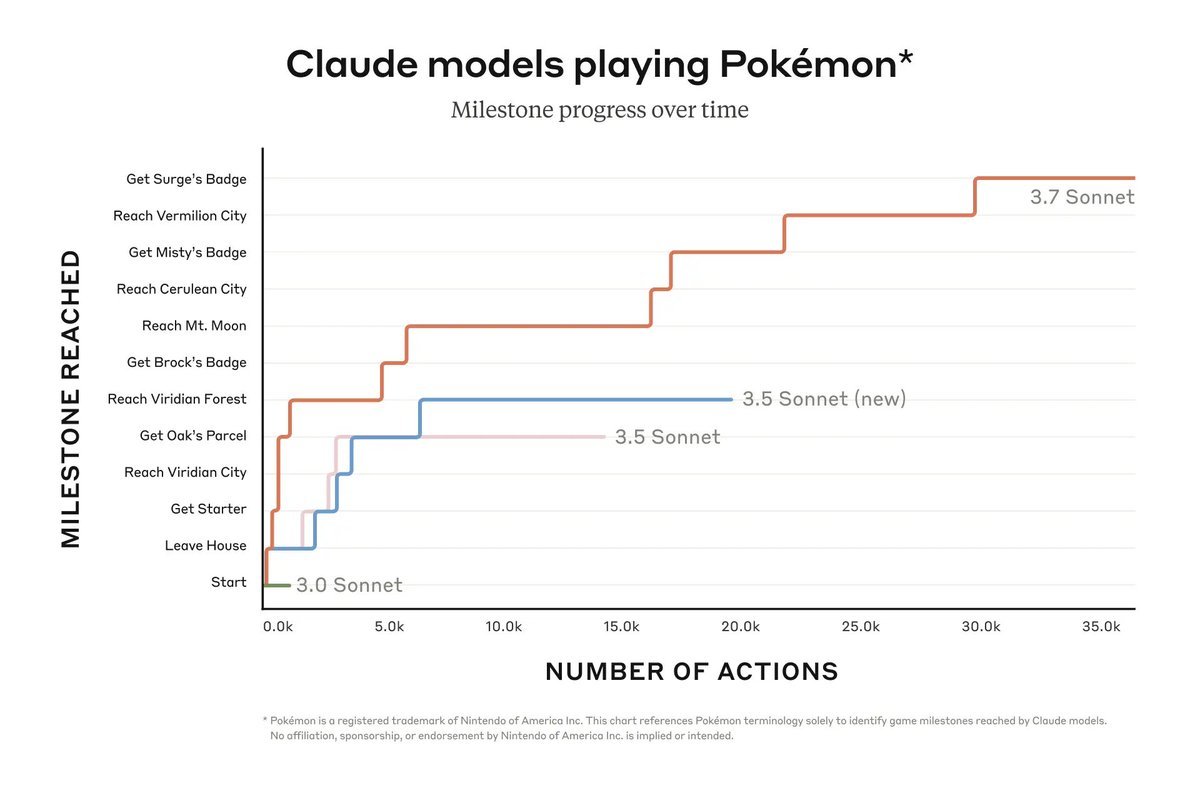
SWE-Bench is cool but I care more about the Pokemon evals.
I'll be convinced of AGI when the model can beat Red from Pokemon Heartgold/Soulsilver first try.
We've conducted extensive model testing for security, safety, and reliability.
We also listened to your feedback. With Claude 3.7 Sonnet, we've reduced unnecessary refusals by 45% compared to its predecessor.
See the system card for more detail: https://t.co/t1f4HQquJe
SWE-Bench is cool but I care more about the Pokemon evals.
I'll be convinced of AGI when the model can beat Red from Pokemon Heartgold/Soulsilver first try.
Claude 3.7 Sonnet is a significant upgrade over its predecessor. Extended thinking mode gives the model an additional boost in math, physics, instruction-following, coding, and many other tasks.
In addition, API users have precise control over how long the model can think for.
Introducing Claude 3.7 Sonnet: our most intelligent model to date. It's a hybrid reasoning model, producing near-instant responses or extended, step-by-step thinking.
One model, two ways to think.
We’re also releasing an agentic coding tool: Claude Code.
@Humza0001 The over-refusal rate of the new system was much lower than the over-refusal rate of the prototype. Most of this was probably because of training-data improvements, and we expect that we can continue pushing this down to really make over-refusals not noticeable!
Really excited to see this result from our demo of constitutional classifiers!
When red teaming a prototype version of our system, we found that the system was robust to thousands of hours of collective red-teaming effort. Following that, we developed a new system with 100x lower over-refusal rate and 4x cheaper inference cost, and we now needed to verify that the new system was as robust as the prototype.
The results seem to confirm this, as it once again took thousands of hours of collective red teaming to jailbreak our system.
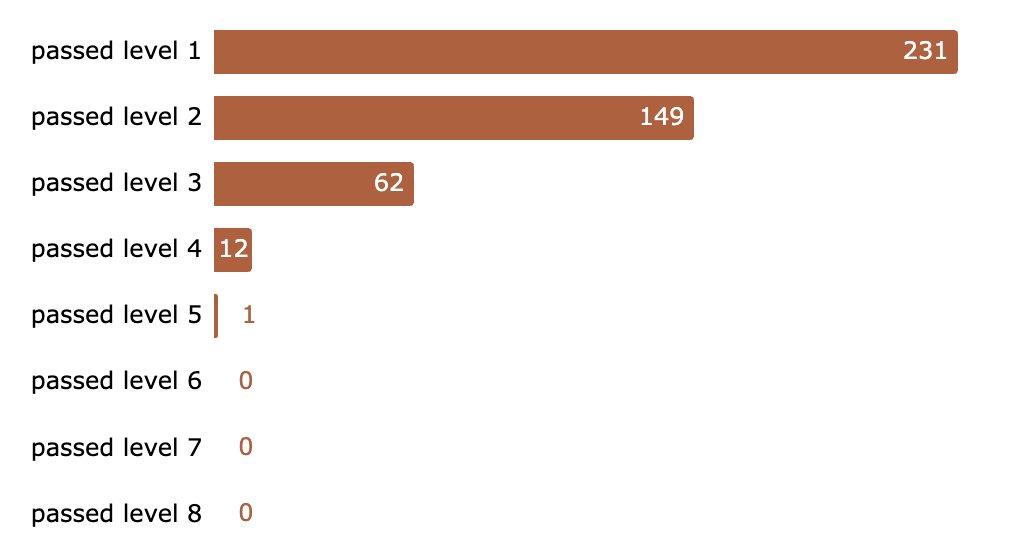
Results of our jailbreaking challenge:
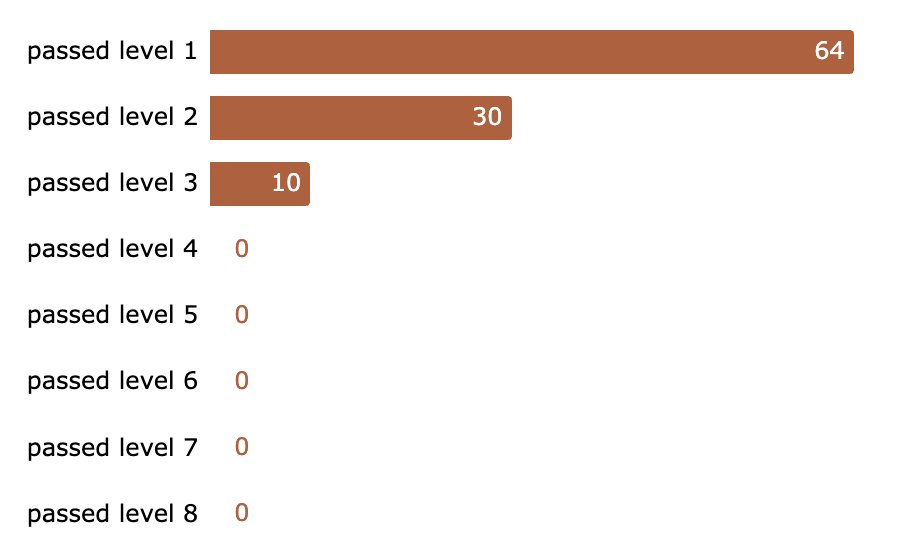
After 5 days, >300,000 messages, and est. 3,700 collective hours our system got broken. In the end 4 users passed all levels, 1 found a universal jailbreak. We’re paying $55k in total to the winners.
Thanks to everyone who participated!
After ~300,000 messages and an estimated ~3,700 collective hours, someone broke through all 8 levels.
However, a universal jailbreak has yet to be found...
Nobody has fully jailbroken our system yet, so we're upping the ante.
We’re now offering $10K to the first person to pass all eight levels, and $20K to the first person to pass all eight levels with a universal jailbreak.
Full details: https://t.co/As1zPIQGOx