Thanks for sharing, @_akhaliq !
Feel free to check out our new SoTA video depth estimator.🥳🤗👏💪
Useful links ⬇️
Demo: https://t.co/sFTHW1BNbq
Code: https://t.co/WXPJ3FkGwb
Paper: https://t.co/IDRUJECeGf
Page: https://t.co/cLbyaLa2c8
One of the wildest emergent capabilities of Genie 3 is that maps actually work.
As I walk around the forest, the GPS display updates its heading in real time.
Remember. There is no game engine here. This is an AI hallucinating a working navigational instrument purely from next frame prediction. 🤯
✨Thinking with Blender~
Meet VIGA: a multimodal agent that autonomously codes 3D/4D blender scenes from any image, with no human, no training!
@berkeley_ai#LLMs#Blender#Agent 🧵1/6
Thanks @_akhaliq for sharing our work!
🤗Our StereoPilot is an efficient feed-forward architecture that leverages pre-trained video diffusion priors to directly synthesize novel views for stereo conversion.
🥳 Page: https://t.co/rNfXYZoRD9
Thanks @_akhaliq for sharing our work!!!🌹
Lotus-2 effectively analyzes the DiT-based rectified-flow formulation and leverages the pre-trained generative model as a deterministic world prior, achieving SoTA performance with significantly finer details.🥳
Thanks so much for sharing @_akhaliq ! The code and @huggingface demos are publicly released, please have a try!
🤗demos: https://t.co/QvGryEhgDk; https://t.co/2pAVCS8jQI
Code: https://t.co/NhU6XZQ2mw
Thanks @_akhaliq for your kind promotion! The 🤗 @huggingface@Gradio demo and the inference code are released now! Please give it a try!🚀
Huggingface Space: https://t.co/wAj2TVIlwe
Github Repo: https://t.co/0i6CIqpxLC
Project Page: https://t.co/z7tL4nBWjn
Thanks @_akhaliq for sharing our work! The code and demo will be public soon. Please have a look if you are interested.🥰🥰🥰
Paper: https://t.co/rywt2tPEKz, https://t.co/2b4lEhKk05
Github: https://t.co/0i6CIqpxLC
Project page: https://t.co/z7tL4nBWjn
Thanks for sharing!!! @_akhaliq 🔥
This work focuses on 360° depth estimation, called DA^2: Depth Anything in Any Direction,
We first built a large-scale training data (scales-up existing data in nearly 10 times!), then we trained a Sphere-aware ViT using the scaled-up data. Finally, DA^2 achieves remarkable geometrical fidelity and strong zero-shot generalization, which we believe can enable various 3D scene related applications, e.g., world models. Please check out below links for more details: 😊
Paper: https://t.co/wlX7LLmPa6
Huggingface daily paper: https://t.co/LvPBUmhiOP
Code (coming soon): https://t.co/2WaDeYnRfd
Project page: https://t.co/T0ANj8pe26
A beautiful collaboration with Tencent Hunyuan @TencentHunyuan@TencentGlobal! Thanks all co-authors! @MaskerZW, @Jingheya, @LeoLau_yuhao, @XinLin321, Xin Yang, @YingCongChen1, Chunchao Guo
@RolandWank Yes! You can do video depth estimation using our demo (https://t.co/SjwBu46wgT). Our latest depth model in disparity brings more consistency!
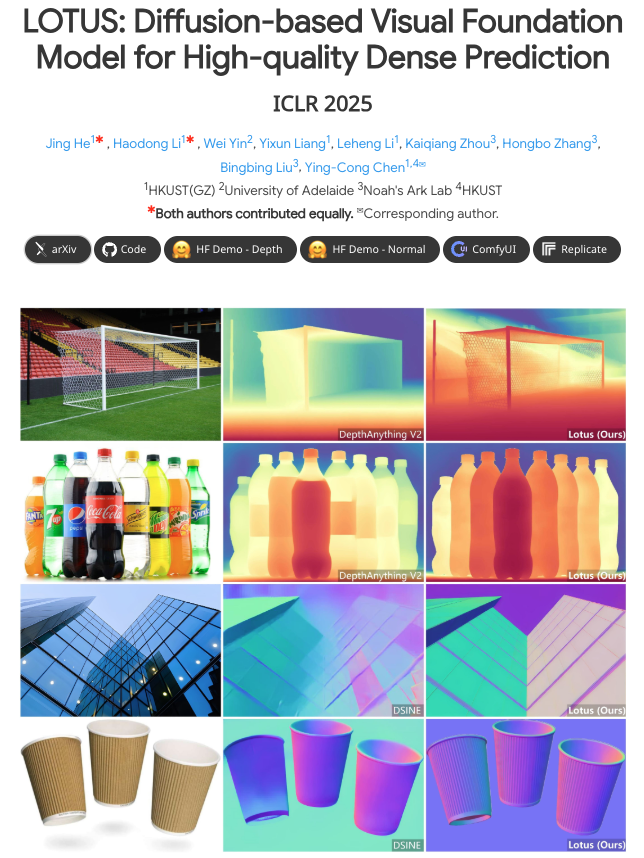
Thrilled to share that our paper, "LOTUS: Diffusion-based Visual Foundation Model for High-quality Dense Prediction", has been accepted to #ICLR2025! 🎉 Many thanks to @YingCongChen1@haodongli00 and all co-authors!
Github: https://t.co/U6IohPw6lS
@chrisoffner3d @ChongZitaZhang Just added a resizing pre-processs to force the input image with a resolution ranging from 384 to 1024 in the demo (https://t.co/z6QcYypxyp). Here are some examples:
That make scenes, because our model is not trained on (RGB, Depth) pairs that have multiple resolutions, so the model performs best when the ratio of resolution / image content close to the data used.🥲
Inference on images that is too large or small will leads to artifacts due the increasing domain gap between inference and training.🥲
Hi @chrisoffner3d , thanks so much for your interest! The latest version of LOTUS - Depth trained in disparity space works for your cases🥹🥹🥹 Here is the @huggingface@Gradio demo: https://t.co/h4A6upCEiT Please have a try using this link if the original version fails on some cases🤣🤣🤣