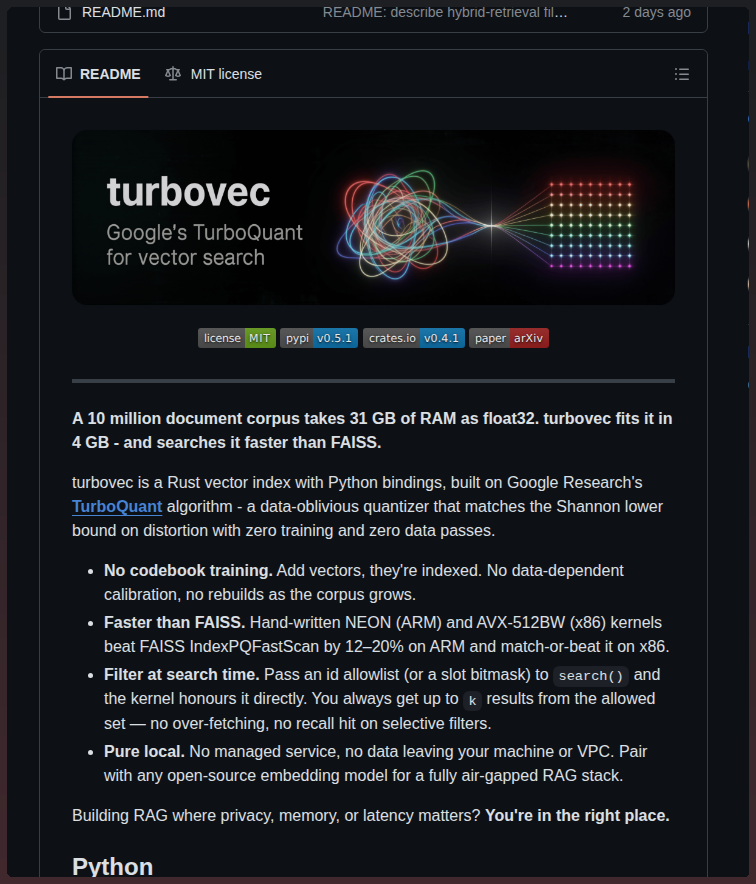
ETH Zurich just open-sourced their entire 2026 robot learning course.
Not a MOOC. The actual course. Slides, lecture recordings, coding assignments, GitHub repo.
The curriculum goes from imitation learning and RL all the way to Vision-Language-Action models and foundation models for robotics.
Guest lectures from the co-founder of Physical Intelligence. The creator of Diffusion Policy. Pieter Abbeel. Dieter Fox.
12 weeks. Free. No signup.
If you want to understand where robot intelligence is actually heading… this is the reading list the field is using right now.
📍[https://t.co/eKsIjILi60]
——
Weekly robotics and AI insights.
Subscribe free: https://t.co/9Nm01QUcw3
Trying a new generative loss: SDMatch.
No discriminator. No denoising chain. Just batch-level distribution matching.
Here’s an early CIFAR-10 attempt. Not solved, but interestingly image-like.
more info below
Thanks @ludocomito for help trying to make it work.
How much of your day are you looking at poorly formatted JSON data, just to see vibes?
I just created a very simple tool to solve JSON and LLM visualization.
Visualize differences across multiple output variants, easily verify correct schema, 100% local just like your data ✅
https://t.co/NoU0Lqrjm9
Excited to share Colored Noise Sampling (CNS)!🎉
Instead of injecting white noise, our SDE sampler exploits the inherent spectral bias of diffusion models. We dynamically color the injected noise to focus on frequencies where details are missing, substantially improving FID.🧵1/9
Gamma-World by NVIDIA.
a real-time engine for multiplayer environments.
- 24 FPS
- Cosmos-Predict2.5-2B
- multi-agent simulation + synchronized perspectives
It can build playable worlds from actions rather than hard-coded geometry.
https://t.co/Xqf5NUg6oa
Real-time neural rendering model @moonlake
Works on from any physics/game engine to close the sim-to-real gap.
If this is relevant to your team, I'd love to chat (my DM is open)!
The latent-vs-pixel debate misses the point.
GPT Image 2 shows what users notice: pixel-level fidelity.
Latent models show what scales: compact semantic structure.
We connect them by replacing VAE/RAE decoders with a Pixel Diffusion Decoder.
Code and Model available: https://t.co/JjtecJzF0W
🧵(1/N)
Awesome. NVIDIA dropped PiD - fast high-res latent decoding via pixel diffusion!
- replace VAE
- 4/8x upsampling
- 2k decoding in <1s on RTX 5090
- works with FLUX.1/SD3/Z
- rapid generation previews
sharper details, much lower hardware lag compared to standard methods.
https://t.co/60Pkqze0gR
I just pushed support for training Z-Image L2P 1k with AI Toolkit. This is a pixel space variant of Z-Image that has a cool unet on the end to recover that lost high frequency that a lot of pixel space models miss. Compute cost is about the same as normal Z-Image.
Microsoft finally releases the full weights for the Lens T2I 3.8B models (Lens/Turbo/Base).
- uses FLUX.2 VAE + GPT-OSS
- 1440x1440
- 4-step gen with Turbo
Looks pretty interesting
https://t.co/Pc8k4iFDJr
We built a bipedal robot for about $2,500.
A real, mostly 3D-printed robot you can build, repair, simulate, train, and control.
Today we’re releasing LeRobot Humanoid: an open robot-learning platform with hardware, runtime, identification tools, and training environments.
Blog post: https://t.co/zu2etb1NZo
Repo: https://t.co/4myLRUtZ3W
🚀Tired of floaters, flickering, and blur in 3DGS? We introduce a geometry-informed video generator that refines 3DGS renderings in the wild. 🎥✨
We let the video model actually "see" the rendering process using a Gaussian Primitive buffer. #CVPR2026@CVPR
Project page: https://t.co/IjE8h0QVuS
🔥 Highlights:
✅ Geometry-Buffer-conditioned video generator
✅ Refines optimization-based & feed-forward 3DGS
✅ Novel artifact simulation pipeline
✅ Highly efficient bidirectional processing ⚡
Thread ��




















![IlirAliu_'s tweet photo. ETH Zurich just open-sourced their entire 2026 robot learning course.
Not a MOOC. The actual course. Slides, lecture recordings, coding assignments, GitHub repo.
The curriculum goes from imitation learning and RL all the way to Vision-Language-Action models and foundation models for robotics.
Guest lectures from the co-founder of Physical Intelligence. The creator of Diffusion Policy. Pieter Abbeel. Dieter Fox.
12 weeks. Free. No signup.
If you want to understand where robot intelligence is actually heading… this is the reading list the field is using right now.
📍[https://t.co/eKsIjILi60]
——
Weekly robotics and AI insights.
Subscribe free: https://t.co/9Nm01QUcw3](https://pbs.twimg.com/media/HKb-vJNW8AATOjb.jpg)