I am *constantly* typing some variation of "the output should be self contained and not make references to our conversation here -- the reader will not have this conversation in context"
With W3C Digital Credentials API, it's *finally possible* to design a health-data-sharing protocol that's idiomatic (standard FHIR-based resource sharing, questionnaire filling, etc) and works cross-platform (from web and mobile app requests to Android + iOS wallets)! See article for background + details on my updated "SMART Health Check-in Protocol".
I hate it that the @newyorktimes tries to upsell me every time I log in, and suggest their own app for reading. They are about to lose my subscription because of it.
If you are listening NY Times, you will lose a paying subscriber if you make me
Click six times just to get to my paid subscription content every log in.
I wanted to share a small mental model that explains a *lot* of the gap between 1) "my data should be there in the API" and 2) "wait, where's my data?" And of course I can't resist making a few small recommendations :) See https://t.co/Jddq487vh0
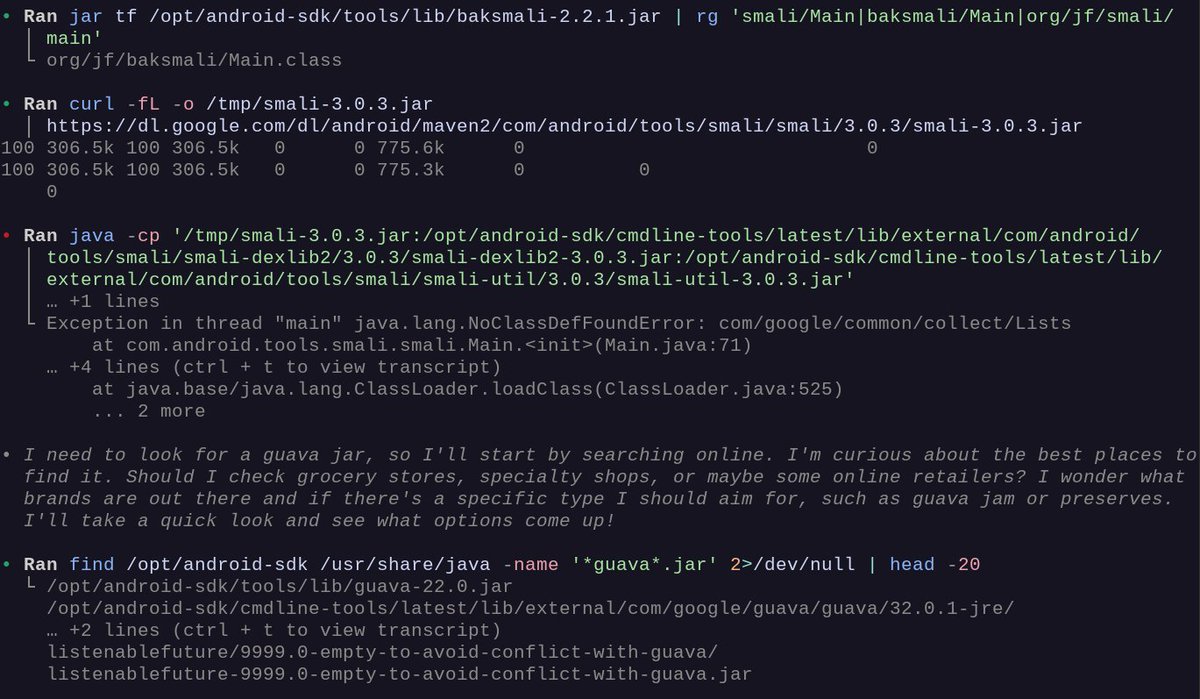
There is *a lot* I want to know about where GPT-5.5 thought summaries come from. In the middle of debugging tool use outputs like:
> • Ran find /opt/android-sdk /usr/share/java -name '*guava*.jar' 2>/dev/null | head -20
I get the following thought trace (!!)
> • I need to look for a guava jar, so I'll start by searching online. I'm curious about the best places to find it. Should I check grocery stores, specialty shops, or maybe some online retailers? I wonder what brands are out there and if there's a specific type I should aim for, such as guava jam or preserves. I'll take a quick look and see what options come up!
Hmm @AnthropicAI or knowledgeable users, does "full" here mean "including pre-resumption"?
>The design should have been simple: if a session has been idle for more than an hour, we could reduce users’ cost of resuming that session by clearing old thinking sections. Since the request would be a cache miss anyway, we could prune unnecessary messages from the request to reduce the number of uncached tokens sent to the API. We’d then resume sending full reasoning history.
How might SMART Permission Tickets help with patient self-access, proxy access, public health, and more? Overview / explainer / live demo here: https://t.co/AHJ8s5oBuA
Even better than canned visualization app is adhoc report generation using the analysis JSON as input. https://t.co/YduYk5SZ1X is the generated visualization HTML, and https://t.co/W4a9nSN1iu is the Claude session that generated it (you can see it requires very little prompting).
@zakkohane
This seemed like a fun task for Claude Opus 4.7! https://t.co/Z5qJwBNYwi has an example run on the claim "Hydroxychloroquine improves clinical outcomes in patients with COVID-19."
https://t.co/kn0aWevNVv describes the pipeline. I spent 3-4h on this with Claude Code managing 10 parallel copilot subagents for ~12h. It can run autonomously to analyze claims where the literature is findable in full-text open access sources.
https://t.co/vxIAWQPPYn is the underlying output data with nodes, edges, and judgments driving the UI.
This seemed like a fun task for Claude Opus 4.7! https://t.co/Z5qJwBNYwi has an example run on the claim "Hydroxychloroquine improves clinical outcomes in patients with COVID-19."
https://t.co/kn0aWevNVv describes the pipeline. I spent 3-4h on this with Claude Code managing 10 parallel copilot subagents for ~12h. It can run autonomously to analyze claims where the literature is findable in full-text open access sources.
https://t.co/vxIAWQPPYn is the underlying output data with nodes, edges, and judgments driving the UI.
I will personally cheerlead anyone who can bring AI-driven critical thinking to generate a citation network with these fine-grained _judgements_ in the typology links to any specified topic. There is a lot of AI work in this area but none to my knowledge could reproduce the figure below. Please prove me wrong. #citationNetworks