Anthropic's Fable 5 vs Opus 4.8 — a Ferrari with a Honda's soul.
And I mean that literally, not as a diss. Quick breakdown:
Fable 5 (out June 9) is the first public "Mythos-class" model — a new tier above Opus entirely.
But when a query touches cyber/bio/chem, it auto-hands the answer to Opus 4.8. Under 5% of sessions.
The Ferrari ships with a Honda engine for certain roads. By design.
The numbers, from Anthropic's launch data:
• SWE-bench Pro: 80.3% vs 69.2%
• FrontierCode: 29.3% vs 13.4% — more than double
• Their own framing: the longer the task, the larger the lead
The price: $10 in / $50 out per million tokens, vs $5/$25 for Opus 4.8.
Exactly 2x.
And on short, well-scoped tasks — i.e., most production traffic — the two are nearly indistinguishable.
The routing playbook:
1. Default every workload to Opus 4.8 (or smaller)
2. Promote a task to Fable 5 only when the cheaper model demonstrably fails
3. Re-audit monthly — routing is a living config, not a one-time choice
To be fair: if your work lives at the frontier — multi-day agent runs, gnarly migrations — the 2x pays for itself fast. Stripe reportedly compressed a months-long migration into days.
The point isn't "skip the Ferrari." It's "know which trips need it."
Practical note: Fable 5 is included in Claude paid plans only until June 22, then moves to usage credits while capacity scales.
Full sketchnote below.
Which of your AI tasks actually need the Ferrari?
@RGVzoomin Try this prompt on hour choice of AI tools and the result will tell you how humans are still superior to AI..
Prompt: I want to wash my car. The car wash is 50 mts away. Should I walk or drive?
Fake candidate profiles: Most expensive bug in the enterprise hiring pipeline
A company spends six weeks and a few thousand dollars vetting a candidate. Interviews. Reference checks. An offer. Onboarding. System access.
Then someone realizes the person doing the job isn't the person they interviewed.
If that sounds far-fetched, the numbers say otherwise.
Building a deepfake good enough to pass a video interview now takes about 70 minutes.
Gartner projects 1 in 4 candidate profiles will be fake by 2028. And a single wrong hire costs 30–50% of that role's salary — on top of the ~$4,700 you already spent getting them in the door.
Here's the part nobody likes to say out loud: we've built a hiring process expensive enough to feel rigorous, and leaky enough to still get catfished.
The tools meant to help each guard one stage. One screens. One proctors. One checks for deepfakes. One verifies ID.
Each is fine on its own — but fraud doesn't attack a stage. It walks through the seams between them.
So the industry's current "fix" is to fly everyone back in for in-person interviews, quietly throwing away the entire cost and reach advantage of hiring remotely.
That's not a solution. That's a retreat.
This is the bug nobody's actually patched — they keep building around it. The real question isn't "how do we catch more fakes," it's "why is the pipeline built so the seams exist at all?" — and how you close them without treating every honest candidate like a suspect.
I've been working on the root fix. It's in active proof-of-concept, and I'll be revealing it soon.
#FutureOfWork #Hiring #TrustAndSafety #AIArchitecture
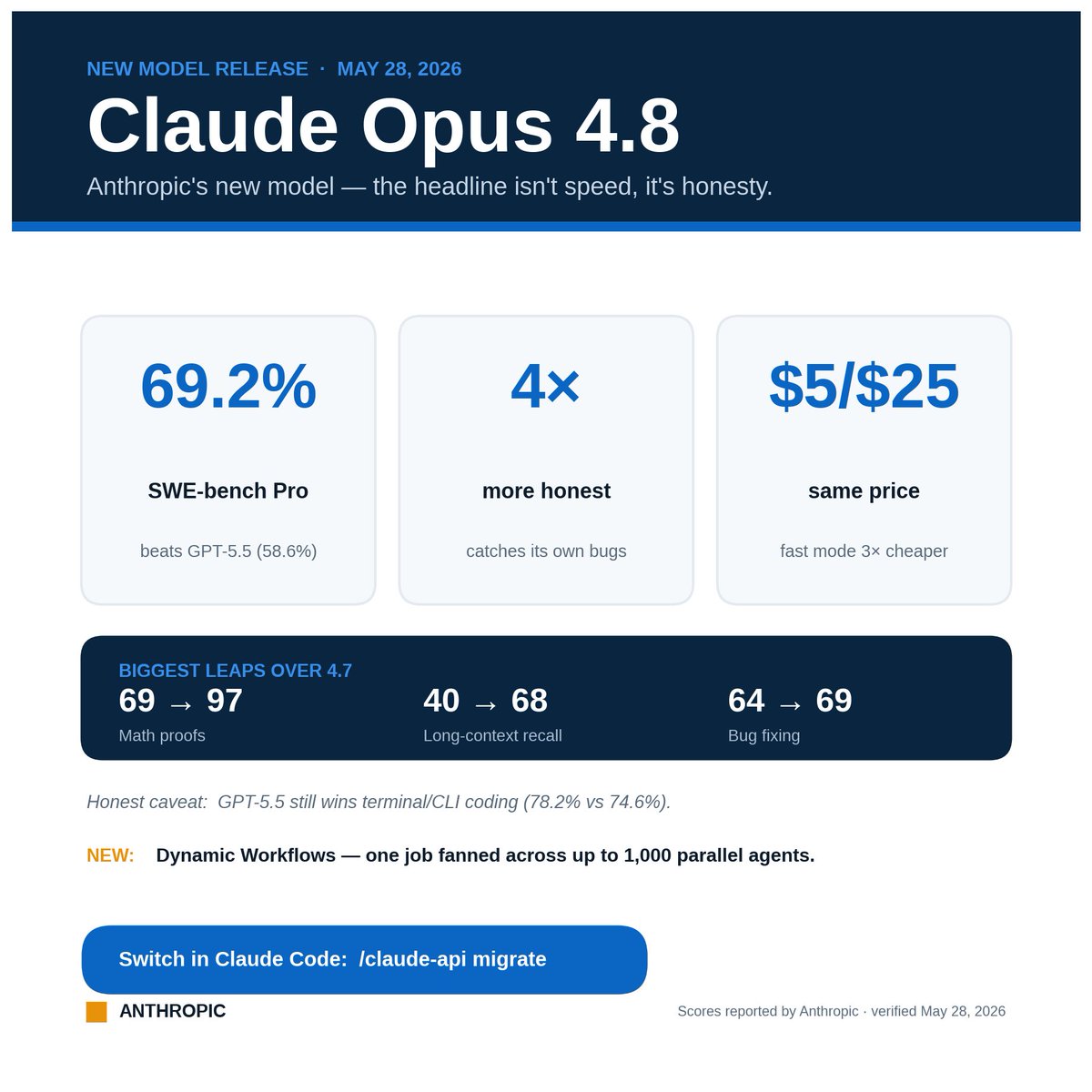
Most AI launches brag about being faster.
Anthropic's new Claude Opus 4.8, out today, has a stranger pitch: it's better at admitting when it's wrong.
Sounds soft. It isn't.
The most maddening habit of AI coding tools is quiet confidence — they write something broken, hand it over like it's perfect, and let you find the bug later.
Opus 4.8 is ~4× less likely than the last version to let a flaw in its own code slip by unflagged. It's also the first Claude to score 0% on passing off flawed work as "done."
Translation: you babysit it less.
It also just got smarter, in places dramatically:
• Math-olympiad proofs: 69% → 97%
• Finding facts inside a million words of text: 40% → 68%
• Fixing real software bugs (SWE-bench Pro): 69.2% — beating GPT-5.5 (58.6%) and Gemini 3.1 Pro (54.2%)
Honest caveat: it doesn't win everything. GPT-5.5 still leads on terminal/CLI coding (78.2% vs 74.6%). If that's your main workload, don't auto-switch.
The flashiest new trick lives in Claude Code: "dynamic workflows."
Claude fans one giant job out across hundreds of parallel agents (up to 1,000), keeps the plan in code instead of its own memory, and checks the work before reporting back.
Anthropic's demo: migrating a codebase across hundreds of thousands of lines, with your test suite as the bar.
And it all ships at the same price as before. A bigger model class, Mythos, is already running inside a few orgs, with wider release teased "in the coming weeks."
The real shift here isn't horsepower. It's trust.
An AI you have to re-check constantly isn't saving you time. One that tells you when it's unsure just might.
(Scores reported by Anthropic.)
#AI #Claude
Tweet 4/4
With a 150K-word memory and the ability to generate live, interactive UIs on the fly, Claude isn't just a chatbot—it's a cognitive engine. Are you extracting its full potential? I'll be sharing a deep dive on prompt engineering for Claude next week. Stay tuned!
Tweet 1/4
ChatGPT got the hype, but a silent revolution has happened in the background. For deep systems architecture and complex coding, there is a new undisputed king. Here's why tech giants are making Claude their default "thinking" engine. 🧵👇 #AI#Claude#Anthropic
Tweet 3/4
The benchmarks are clear:
GPT = The Sprinter (fast math, high-volume)
Gemini = The Librarian (massive 2M context window)
Claude = The Architect (deep logic, multi-step coding)
Amazon and Google Cloud are now integrating it natively due to enterprise demand.
Prompt: "Car wash is 50m away. Walk or drive?"
ChatGPT/Claude/Grok: Write essays on fuel efficiency and the health benefits of a 60-second walk.
Gemini: ✅
Perfect reminder that AI can optimize flawlessly for the exact wrong objective.
#AI#TechHumor#LLMs#MachineLearning
@Jake__Wujastyk Time in the market >>>> timing the market.
Proved time and again — especially in April 2025 and now again in April 2026.
Reminder: missing the best days (or panicking out at the lows) is far costlier than riding through the volatility. Staying invested wins in the long run.