@dani_avila7 What did prevent them from visualizing that inside of TUI? Let’s say by running /workflow [name] command? I agree with the fact that observability as well as the ability to customize/adjust/reuse is everything.
Working on a much more powerful (and useful), way more transparent version for the https://t.co/DQFh3idzVT coding agent. Eventually you’ll be able to generate your workflow based on skills, scripts, and integrations based on prompts, including contracts among stages. You should be able to reuse the flows, customize them for your needs: have steps that connect your harness to external systems, and the ability to access your data the way you want, use deterministic logic in place and use the models you wish in each components. The only good idea in Anthropic’s version is dynamic generation. I don’t see any reason to generate Python under the hood and have a runtime based on subagents only, without the ability to bend that flow for your needs or use skills as the steps. Anthropic’s version is half-baked and very limited, as it doesn’t let you build a real harness that you’re in control of.
Look preview of rpiv-workflow package on my github:
https://t.co/xMRSP4GnFh
@badlogicgames Having several sessions in one process. No RPC, no bootstrap, zero infra, just in-process sync. If the flow is stateless or needs no durability, process-per-session is pure overhead. Flue-like, the process boundary is just the priciest tier.
Agree same time there is a nuance ... they are trying to eat this time a part of the control flow around the models (as usual hiding it), a one possible consequence that the deterministic flows and loops we own will be pushed up if properly utilized the "new" abilities or get more dynamic as well.
might be that just self-soothing or self-calming on my side :) only time shows... I am glad you found the thoughts insightful. I do believe in the direction for sure - human will stay inside the loop for a while but not everyone keep the job ... human should learn how to push models back even along SDD, steer it timely, reject decisions etc. Believe or not I am quite often following agent output from stage to stage ... just to see a moment one goes off the rails :)
This anthropic's representative post shows the limits of their current approach in prompting. That's exactly why "wrapper builders" have good odds.
The highest-leverage primitive in agentic engineering isn't a smarter model. It's the structured pause - the ability to ask before committing. A post-hoc "I picked X because Y" is exhaust (still helpful pattern), a postmortem journal of decisions the model already made in one forward pass. By the time you read it, X is already an import, a schema, a public type. And no matter how detailed the spec, ambiguities exist. I learned that the hard way.
The reason labs can't quietly absorb this layer is structural. Every autonomous coding eval scores the model on completing without asking, so asking is a leaderboard loss. But that's the symptom. The deeper structure: a forward pass is just generation... It can't pause itself. Deterministic control flow (pauses, gates, checkpoints) lives outside it ... reliability comes from architecture, not instruction.
The harness has the opposite gradient. The user is the eval and the driver, not the benchmark. The harness can enforce pauses because pauses are control flow, not sampled tokens.
An opinionated metaflow (like mine https://t.co/pU8NwonxtI, @dexhorthy's CodeLayer/HL, the many other flows enthusiasts built on top of the models) is uncompressible into a general purpose API. Not because the model can't learn workflow shapes, but because workflows are control flow around the model.
This is a product competition on even ground. Not a model eating a layer.
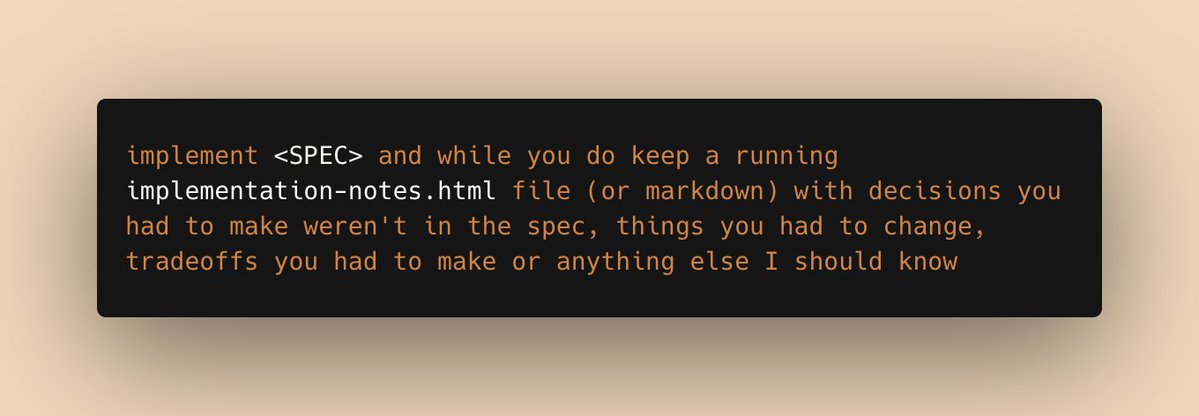
a prompt I've been using a lot recently:
implement <SPEC> and while you do, keep a running implementation-notes.html file (or markdown) with decisions you had to make weren't in the spec, things you had to change, tradeoffs you had to make or anything else I should know
Three years ago I was on the same page. Classical Detroit school, state-based, avoid mocks. AI changed my mind, but less than I first thought.
what AI actually killed is the maintenance cost. Tests got so cheap to write and rewrite that a lot of coupled tests I used to throw away are worth keeping now (bellow why). In that sense, yes, coverage starts to outweigh coupling....
The coupling had a second cost that has nothing to do with how cheap tests are ... false confidence. When the agent writes the code and the test at the same session, the test just confirms its own assumptions instead of constraining them.
So I don't think it's "fewer seams" vs "more coverage". There are two kinds of tests now (in my point of view). A few behavioral outside - the real proof the system works. And a pile of cheap coupled ones for the agent's loop
The cheap ones still matter, just not as assurance. They localize. When the agent breaks something, a fine-grained test points at the exact function, so the loop is fast and it self corrects instead of hunting
Your point that some apps can't reduce to one seam sounds right for me. That's where mocks lie the most, so there one may spend on one real integration seam instead of ten mocked ones...
Keep a few outside seams as the real proof, prompt the agent to protect that layer (those tests are forbidden "to fix by modification" and let the pile stay disposable.
7th to the table https://t.co/SbzQ9t5KUt. The article answers why SDD and I know exactly the answer on Pi + SDD = ? … we will see some benefits quite soon.