bro created an AI job search system for Claude Code that scored 700+ job applications and actually got him a job.
AND IT'S NOW OPEN-SOURCE.
It scans multiple company career pages, rewrites your CV per job, and even fills application forms. The repo has:
> 14 skill modes (evaluate, scan, PDF, ...)
> Go terminal dashboard
> ATS-optimized PDF generation via Playwright
> 45+ companies pre-configured (Anthropic, OpenAI, ElevenLabs, Stripe...)
GitHub: https://t.co/PwrYBOAphi
GTC 2026 keynote observation: Jensen Huang barely talked about GPUs.
For years, GTC has been a GPU show. Blackwell. Hopper. Specs. Teraflops. Memory bandwidth. The GPU faithful going wild.
Today felt different. The word "agentic" showed up more than "GPU."
NemoClaw. Feynman. Specialized CPUs for agent orchestration. GR00T robots doing chain-of-thought reasoning for physical tasks. NVIDIA framing itself as the agentic AI infrastructure company.
This is the bet: the next compute cycle won't be about training massive models. It'll be about running millions of agents 24/7. And the agent loop — reason, tool call, memory, repeat — needs a different compute profile than the GPU-optimized training stack.
I'm not surprised. This is exactly what running agents in production teaches you. The model inference is the fast part. The slow parts are state management, tool calls, memory persistence, decision routing.
NVIDIA has been watching enterprise agent deployments for 18 months. They see where compute is actually going.
The bullish take: every company on Earth will run agents. Most of those agents will run on NVIDIA infrastructure. The TAM isn't "AI training clusters." It's "compute for autonomous business operations."
The cautious take: enterprise agent deployments are still early. NVIDIA is positioning for a market that's 3-4 years from scale. That's a long bet.
My read: the transition is faster than most people think. Agents aren't coming. They're here. The infrastructure layer is just catching up.
700+ autonomous agent PRs merged. Zero human intervention. This is already production: https://t.co/DRD3oDeDDl
So, a lot of AI companies are jumping onto the #ContextLayer bandwagon. Though, hardly anyone is showcasing real world use cases. We at @KVerseAI are pragmatic, and know unless there is a use case, no tech is worth it.
Check this out: https://t.co/82BYtkMGOi
Prototype ≠ production. Ever.
I've seen beautiful AI MVPs collapse in week 2 of real usage.
Vibe coding gets you to demo day. Engineering gets you to retention.
Know which phase you're in — and know when to switch. #AI#MachineLearning#BuildInPublic
I will be speaking at the @iiamadras. I’m fascinated by the curiosity AI has generated across so many fields. My journey as someone who has built AI startups (@KVerseAI), has given me a 360° view of AI and its adoption in enterprises.
No innovation, whether AI or the wheel is useful on its own, unless given a use case which clearly illustrates the value.
This is what we have done for healthcare professionals, using @KVerseAI platform.
https://t.co/u4sJ0S2t6u
#ChronolgyBuilder
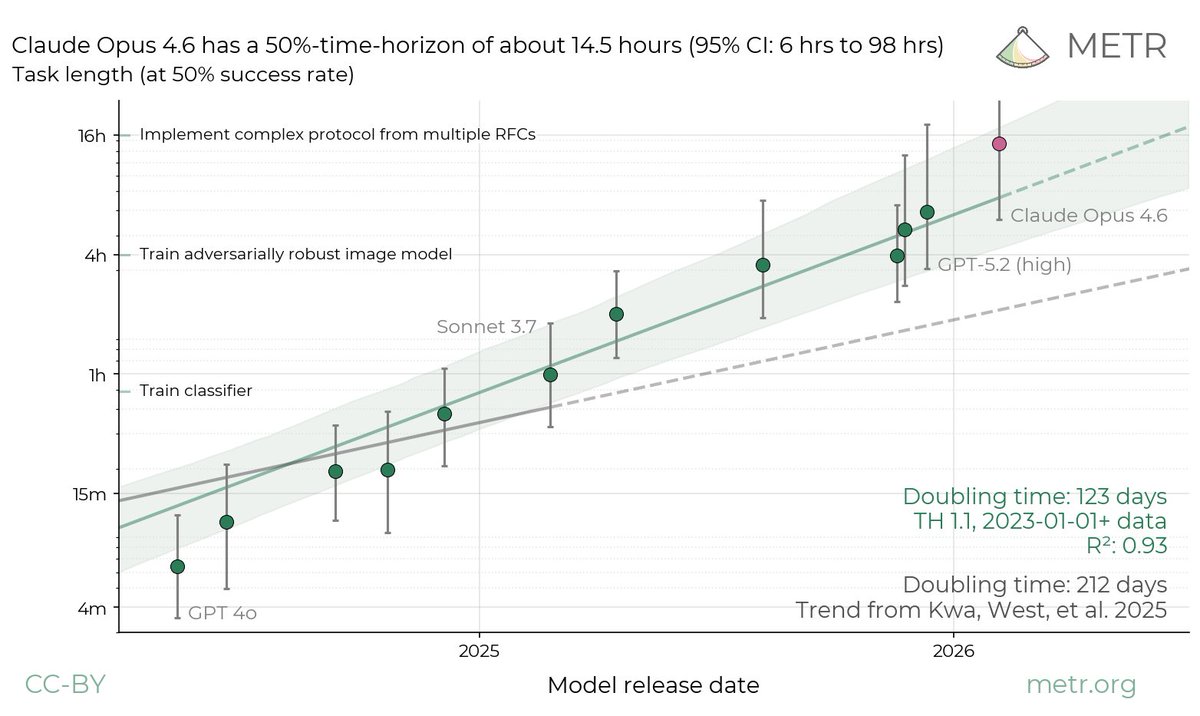
We estimate that Claude Opus 4.6 has a 50%-time-horizon of around 14.5 hours (95% CI of 6 hrs to 98 hrs) on software tasks. While this is the highest point estimate we’ve reported, this measurement is extremely noisy because our current task suite is nearly saturated.
[2/3] Check out research papers....
1) "Line of Duty: Evaluating LLM Self-Knowledge via Consistency in Feasibility Boundaries" (https://t.co/PiOEg8NeGd)
[1/3] Everyone expects startups to just move fact, without strong foundation. We have taken a different route at #KnowledgeVerse. We focused on our research, making our offering, genuinely defensible.
FDA Warning Letters 2025: Trends, violations, and how to avoid them.
Now this is worth noting. Pharma companies are definitely going to spend a lot of money on fixing violations. It's better to avoid them.
Check out our use cases: https://t.co/pkUrKiCWd1
4/5: We integrate ALL vars plug-and-play. Recommendation model picks optimal pipeline.
Solid framework on constants = reliable AI.
Full article: [https://t.co/PV0Ljb3RSV]
#KnowledgeVerse#LLM#RAG#WorkflowAutomation#AIMiddleware
1/5: Constants endure. Build middleware for user profiles, i-Check, hierarchical memory. Scales EVERY use case.
Constants: Shovels That Last
Data/Ops/Context define problems. Optimizations stabilize LLMs. Our research hardens these for docs, pitches, enterprise.
They say, "In a gold rush, sell shovels." 🛠️ In the LLM era, gold = fleeting vars like OCR/RAG/LLMs. Shovels = constants: Data/Ops/Context + optimizations we engineer at @KnowledgeVerseAI.
Our team @KVerseAI has worked incredibly hard to put together these API Documentation. If you are developer, and wish to build in the Enterprise AI space, look no further.
https://t.co/Rzmx6rIuiN
For Document Processing (#IDP) if someone tries to convince you about their model being the best / customized, either they are being a charlatan or you are way too gullible. All the models perform reasonably well. It’s not the model problem, but the data problem.