I'm starting to encounter this a lot more now - is this a new thing? I'm running 4-5 concurrent claude code cli sessions on the terminal. Super annoying
I keep watching coding agents like Claude Code call tools when the answer is already in the prompt and this grinds my gears so much.
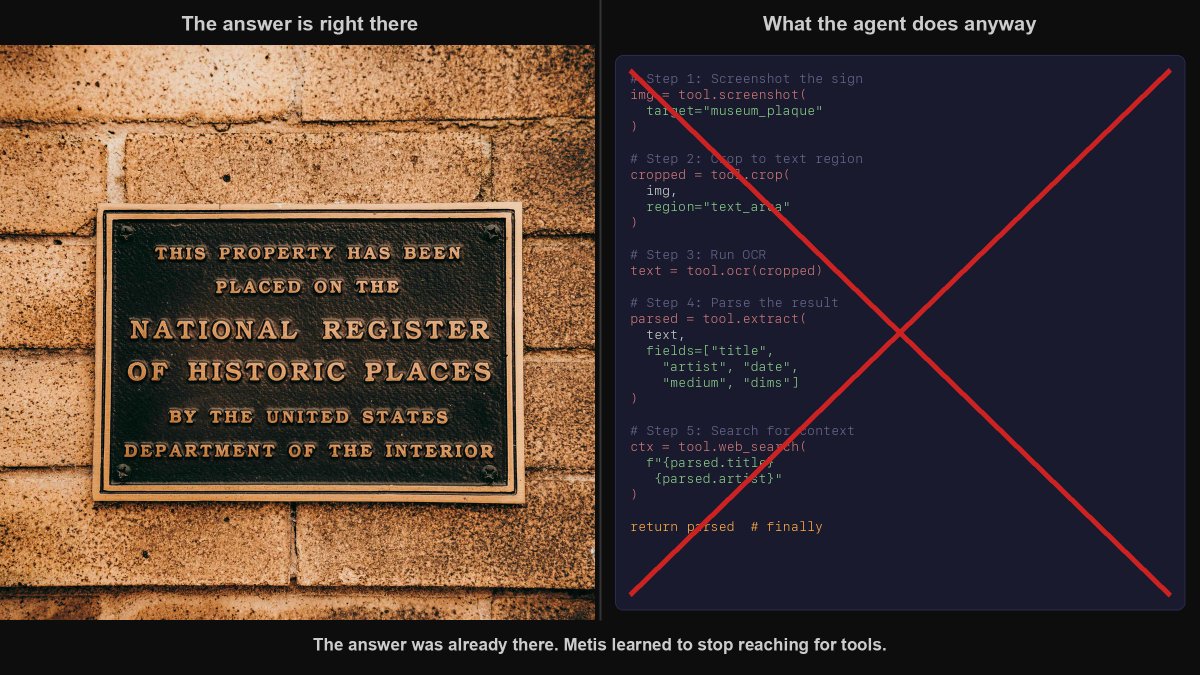
An agent looking at a museum sign with perfectly legible text will still write a Python script to crop and OCR the image. Alibaba just put numbers on how expensive that reflex is. Their Metis agent cut tool invocations from 98% to 2%. And accuracy went up, not down.
The researchers call it a "metacognitive deficit." Current AI agents cannot tell the difference between a task that needs an external tool and a task they already know how to solve. So they default to calling tools on everything. That is not intelligence. That is a reflex.
The team at Alibaba's Accio Lab, led by Shilin Yan and Jintao Tong with researchers from Huazhong University of Science and Technology, built a framework called HDPO, Hierarchical Decoupled Policy Optimization. The core idea is that accuracy and efficiency are two separate objectives, and if you train them together in a single reward signal, their gradients interfere destructively. The model gets confused about whether it is being rewarded for getting the right answer or for being efficient.
HDPO splits optimisation into two independent channels. The accuracy channel maximises correctness across all rollouts. The efficiency channel optimises execution economy, but only within trajectories that already got the right answer. An incorrect response is never rewarded simply for being fast. This creates what the paper calls an "implicit cognitive curriculum." Early in training the model focuses on accuracy. As it improves, the efficiency signal gradually strengthens.
The results on an 8 billion parameter model built on Qwen3-VL: 91.1 on V*Bench versus 86.4 for the base model. Average math and logic score of 66.9 against 59.4 baseline. It also beat Skywork-R1V4-30B-A3B on V*Bench. Skywork is a mixture-of-experts model, 30B total parameters but only 3B active per inference. Different architecture, same benchmark, Metis wins.
I run a stack of Lambdas for the CtrlAltDebrief pipeline and the API costs are real. Every unnecessary tool call is latency and money.
The expensive part of agents is not always the model. Sometimes it is the reflex to ask for help. The whole thing is open source under Apache 2.0.
I've done more than 200 interviews and reviewed thousands of resumes in my career. I used to think resume bias came from humans reading too fast or pattern-matching on school names. This paper points at a stranger version.
Researchers from the University of Maryland, NUS, and Ohio State tested what happens when the same LLM writes a resume summary and screens it. Across 2,245 real resumes and 24 occupations, they had 9 different LLMs generate resume summaries, then had each model evaluate pairs of human-written vs AI-generated versions. When the same model writes and screens, the candidate is 23-60% more likely to be shortlisted.
GPT-4o preferred its own resume summaries 82% of the time after controlling for content quality. GPT-4-turbo hit 72%. LLaMA 3.3-70B sat at 79%. DeepSeek-V3 came in at 72%. These numbers held even when human annotators rated the human-written version as higher quality.
LLMs develop recognisable stylistic fingerprints in their outputs. Specific sentence structures, token patterns, word choices, even how they distribute commas. When the same model evaluates text, stylistic alignment with its own outputs appears to push scores higher. The researchers call it "self-recognition." The model is not just judging quality. It is also pattern-matching against its own tendencies.
Resume screening already had all sorts of bias baked in before AI got involved. But this is a new category entirely. The bias doesn't come from the content or the candidate. It comes from stylistic alignment between the generator and the evaluator.
The occupation breakdown matters too. Sales and accounting showed the largest disparities. Agriculture and arts the smallest. So the fields most likely to adopt AI hiring tools are the same ones most affected by this bias.
There's a partial fix. A majority voting ensemble, basically running resumes through multiple models and averaging the result, reduced GPT-4o's bias from 82% to 30%. LLaMA dropped from 79% to 23%. System prompt interventions alone were less effective, only cutting bias by 17-62% depending on the model.
If you're building a hiring pipeline right now and you pick GPT-4o as your screener, you've just given a silent advantage to every candidate whose resume summary was also written by GPT-4o. Nothing to do with talent. And you'd have no way of knowing it was happening.
I went looking for the land-use case against data centres because the panic on my timeline was getting louder. NIMBYism, farmland loss, environmental catastrophe. So I pulled the actual numbers and they kept pointing somewhere else entirely.
Data centres will use roughly 1,400 square miles of US land by 2028. Buildings, surrounding campus, the lot. The actual building footprint? Around 25 square miles. That is 0.005% of prime farmland. It is 1/15th the acreage of American Christmas tree farms.
The US dedicates about 30 million acres to growing corn for ethanol. That's 1.5% of the entire contiguous United States, mandated by law, to produce 15 billion gallons of fuel annually. 40% of all American corn goes into car fuel, not food. The data centre footprint by 2028 is a rounding error next to ethanol acreage.
The water argument is built on worse foundations. Karen Hao's book Empire of AI claimed a proposed Google data centre near Cerrillos, Chile would use "more than one thousand times" the water consumed by the town's 88,000 residents. Andy Masley fact-checked it in a separate analysis and found the underlying government document listed figures in cubic metres that Hao read as litres. A 1,000-fold unit error that cascaded through her calculations. The actual ratio was roughly 0.22x. The data centre would have used less water than the town, not a thousand times more. That claim got repeated everywhere.
The ethanol corn crop withdraws 1.5 to 2 trillion gallons of water per year. Lawrence Berkeley National Laboratory projections for data centre water use through 2028 come in at roughly 40x less than that. A typical hyperscale facility uses about 8 million gallons annually. In White County, Indiana, that is equivalent to one 35-acre irrigated corn farm, about 0.4% of the region's agricultural irrigation.
Where the numbers get genuinely interesting is revenue density. Loudoun County, Virginia has given 3% of its land to data centres. Those facilities now generate 38% of the county's entire general fund revenue. There is no other building type in the US that produces anything close to that ratio.
Data centres are an easy target because they're new and visible and owned by companies people already distrust. The policy energy aimed at them would do more good pointed at ethanol mandates.