Why do open-source image editing models lag behind closed-source giants like GPT-Image-1, Seedream, & Google-Nano-Banana? 🤔
It’s mainly due to the quality of the training reward signal.
We’re bridging the gap. Meet EditReward! 🏆
What if the very pretrained prior that lets an RL agent explore tools also destroys the format that made it tool-native?
We name this the Tool Prior Paradox — and tame it with PARA-GRPO.
🚀 Introducing ParaVT: parallel video tool use × agentic RL.
🙏 If you find this useful:
⭐ Star the repo → https://t.co/Mgc3urfLGg
👍 Upvote on HF Daily Paper → https://t.co/1Hn3mrdYDS
🔁 Retweet to help us reach researchers working on world models, video gen & reward modeling
🌍 Can today's video generators REASON about how the world should evolve — or do they just render it beautifully?
Introducing WorldReasonBench: a human-aligned stress test that re-frames video generation as future world-state prediction.
🌐 https://t.co/c0HBr58WRu
Qualitative example — when SOTA still fails 🎬
Visually plausible ≠ world-aware.
Even top models get classic prompts wrong:
• "Pencil in water" — refraction direction inverted
Browse all qualitative cases on the project page 👇
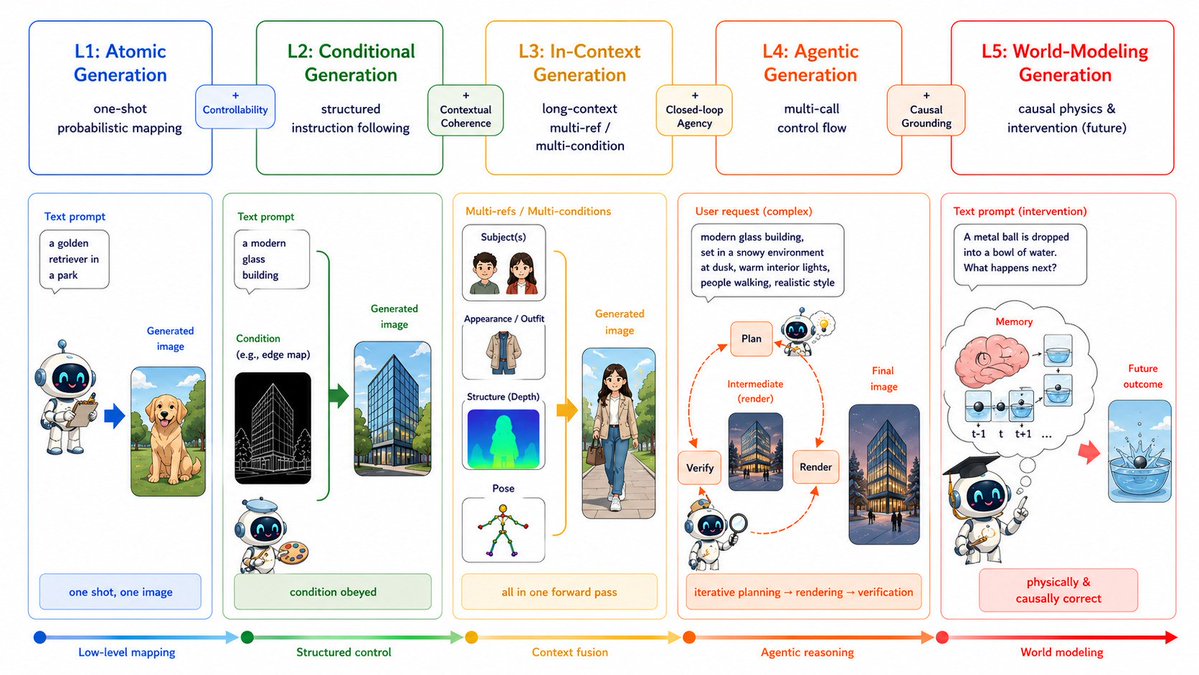
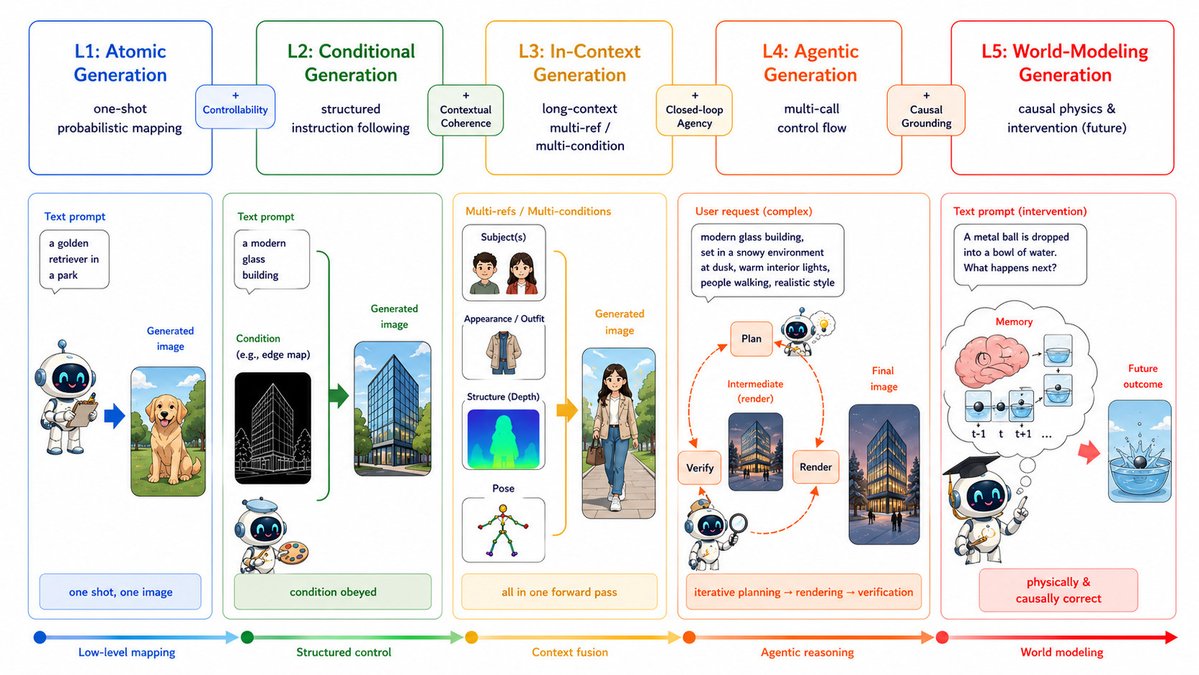
Excited to share a fun project I recently collaborated on: a roadmap for thinking about where visual generation is heading next. The key question is no longer just “can it make beautiful images?”, but whether it can handle memory, interaction, and eventually world modeling.
Takeaway:
The future is not just higher-fidelity images.
It is controllable, interactive, verifiable, and world-aware generation.
arXiv: https://t.co/F40gaRS939
HF Daily Paper: https://t.co/jnC75XxbGf
GitHub: https://t.co/G50LYzKrLJ
WebPage: https://t.co/cB510BFxfp
Excited to share our new roadmap:
Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling
What does it mean for image generation models to become truly intelligent?
HF Daily Paper: https://t.co/jnC75XxbGf
WebPage: https://t.co/cB510BFxfp
Benchmarks often reward visual quality.
But real progress also needs spatial reasoning, topology, symbolic structure, and code/math-grounded correctness.
We stress-test physical and causal reasoning:
These examples probe the boundary between image synthesis and world modeling.
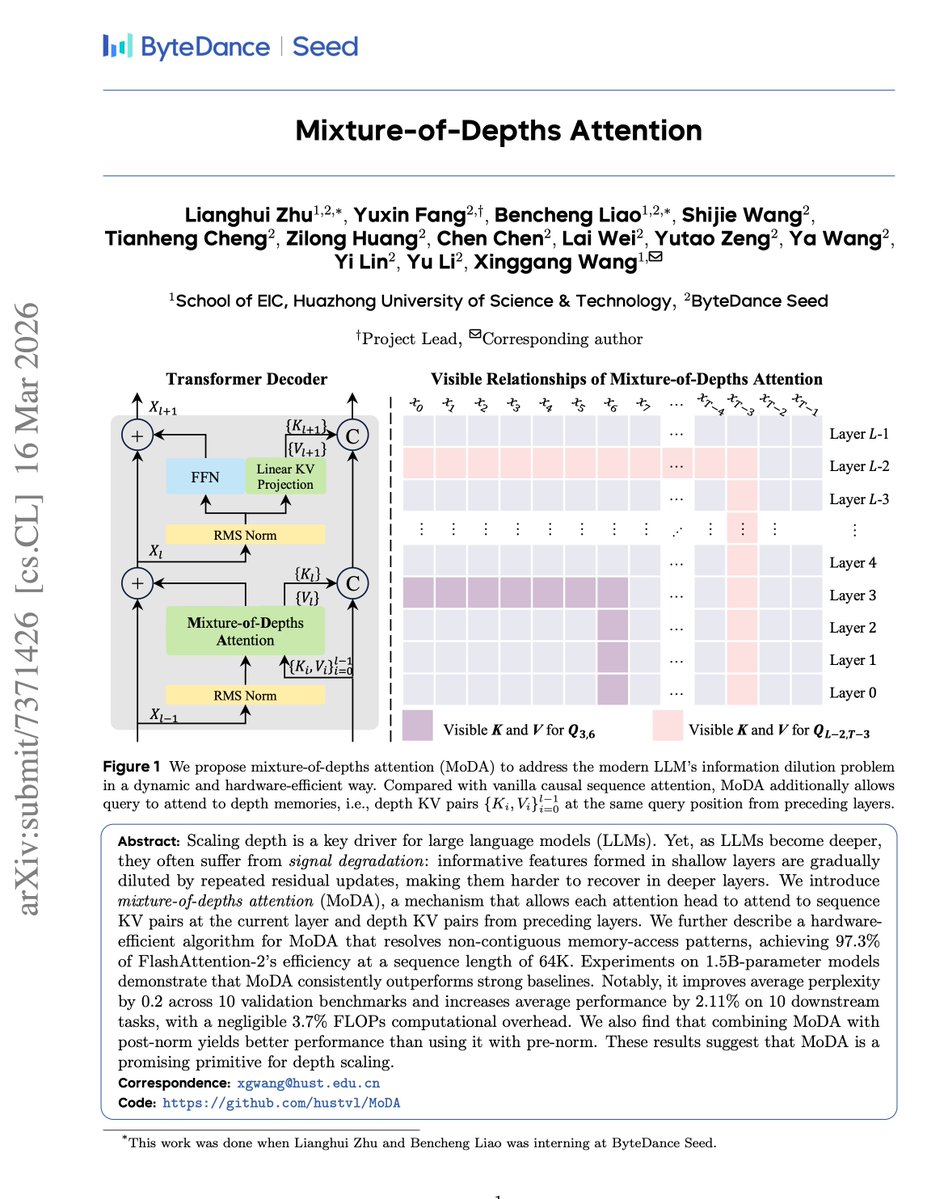
For a decade, we've made models wider and deeper—but we've barely changed how layers *talk* to each other.
Since ResNet's `x + F(x)` in 2015, the depth residual has been the only highway for inter-layer communication.
It's time to upgrade the staircase. 🧵
The TurboQuant paper (ICLR 2026) contains serious issues in how it describes RaBitQ, including incorrect technical claims and misleading theory/experiment comparisons.
We flagged these issues to the authors before submission. They acknowledged them, but chose not to fix them. The paper was later accepted and widely promoted by Google, reaching tens of millions of views.
We’re speaking up now because once a misleading narrative spreads, it becomes much harder to correct. We’ve written a public comment on openreview (https://t.co/nDVjmNhATM).
We would greatly appreciate your attention and help in sharing it.







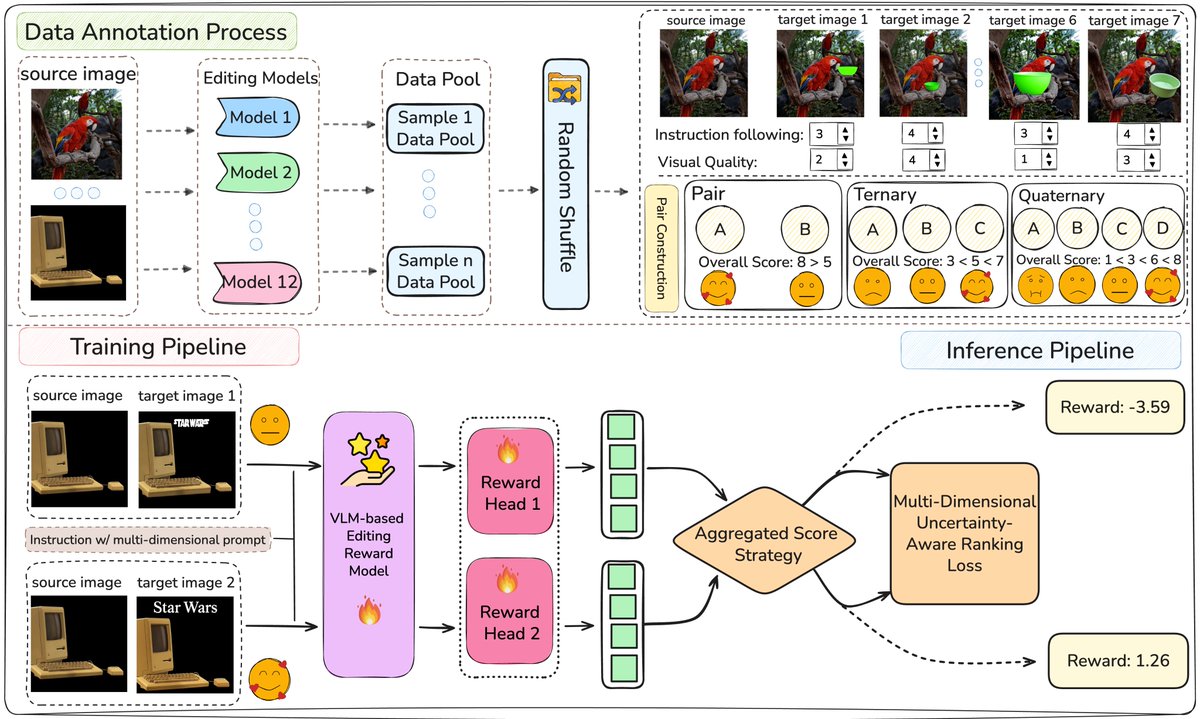


![CSVisionPapers's tweet photo. Visual Generation in the New Era: An Evolution from Atomic Mapping to Agentic World Modeling
Keming Wu, Zuhao Yang, Kaichen Zhang, Shizun Wang, Haowei Zhu, Sicong Leng, Zhongyu Yang, Qijie Wang, …
https://t.co/3PaATxbfiA [𝚌𝚜.𝙲𝚅]
💬Project: https://t.co/e06OsM7VfL https://t.co/UZPUODjtl0](https://pbs.twimg.com/media/HHPZYnYXIAA_4T3.png)