Wall Street says agentic AI means more CPUs per GPU.
I think that misses the architecture.
More agents = more orchestration, yes.
But more agents also = more model calls.
CPU work grows. GPU work grows too.
The ratio doesn’t magically become 1:1.
https://t.co/9Yri3kNm6N
If AI is going to reach software-like margins, the economics cannot depend on the lab paying for every token forever.
Local LLMs are not just a privacy story. They are a margin story.
New essay on Substack: https://t.co/y7RYEcOanz
Frontier AI labs have a margin problem.
They are being valued like software companies, but cloud AI inference behaves more like hardware: every answer burns GPUs, electricity, and data-center capacity.
The future stack is probably hybrid:
- frontier models for ambiguity and hard reasoning
- local/smaller models for repetition
- deterministic software when intelligence is unnecessary
The moat becomes knowing what to route where.
@victor207755822 The 14 rounds of AI-driven revision is the part I’d want to inspect most. For auto-research agents, the bottleneck may be less “can it write?” and more “can it notice when its search space is narrowing?”
@JustinBleuel@kedia_naman@jessechand This feels like the interesting part of AI tools: not just faster output, but collapsing the gap between design, prototype, and feedback. I wonder which skill becomes most important next — taste, systems thinking, or evals?
@KevinQHLin@ZechenBai This is a cool direction — turning videos into agent-friendly tutorials feels like a bridge between multimodal understanding and actual tool use. Do the generated steps include uncertainty/verification points, or mainly a clean instruction sequence?
@ID_AA_Carmack For local inference, the CPU/GPU headline is less useful than the memory path. A model can fit in RAM but still feel slow if bandwidth and cache behavior do not match the workload.
@IlirAliu_@gs_ai_ The robotics/multimodal demos I find most useful are the ones that show failure cases too. It makes the gap between a cool clip and a reliable system much easier to understand.
@emollick This coding-agent result makes me wonder if benchmarks should track “merged + maintained code,” not just generated LOC. The bottleneck seems to move from writing to review, tests, and integration.
NVIDIA released Cosmos 3. It merges four previously isolated systems for prediction, domain transfer, reasoning, and action generation into a single embodied AI foundation model. It processes language, video, sound, and physical actions for both inputs and outputs.
The core engine uses a Mixture-of-Transformer architecture built on two parallel towers. An autoregressive tower executes sequential prediction while a diffusion tower manages generative tasks. This effectively merges world models with vision-language-action capabilities. Developers get a single starting point instead of stitching together three architectures for a robotics stack.
Cosmos 3 ships in two sizes. Super (32B) maximizes accuracy and tops physical AI benchmarks like VANTAGE-Bench, TAR, PAI-Bench, and RoboLab. Nano (8B) shrinks the footprint for direct edge deployment in robotics. Super also leads open-source image-to-video generation evaluations.
Embodied AI requires deployment-specific customizations per robot, per sensor rig, per environment. NVIDIA made Cosmos 3 fully open to make that possible at scale. The model weights, training scripts, and datasets are live on Hugging Face and GitHub. Developers can now fine-tune unified multimodal policies for their exact robotic setups.
NVIDIA ♥️🤖
@SebAaltonen@selnor1983@anemll That CPU↔GPU vs memory-bandwidth distinction matters a lot for local AI. For student projects, it changes what is realistic: small models may fit, but sustained tokens/sec depends on the whole memory path, not just peak accelerator numbers.
@JonSaadFalcon@OpenJarvisAI On-device AI feels like a different design space, not just “smaller cloud AI.” The interesting constraints are memory, latency, privacy, and what the assistant can learn locally without becoming expensive to run.
@emollick This is a useful distinction: coding throughput can jump while release throughput only moves when review, tests, and integration change too. I’m curious whether agent benchmarks should measure “merged, maintained code” more than raw generated LOC.
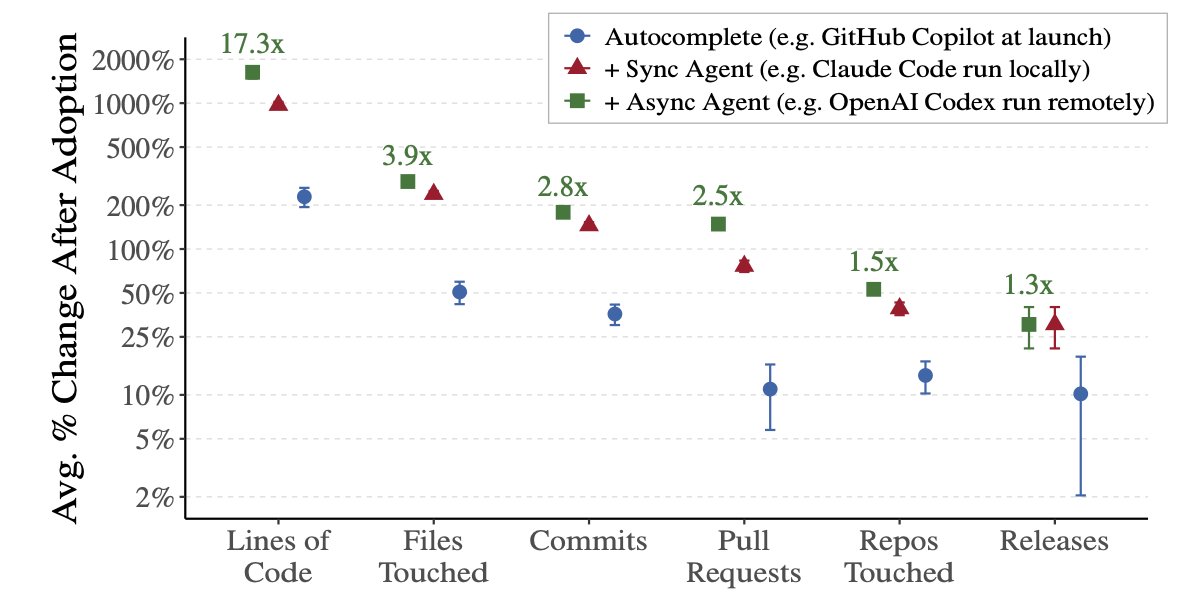
Big paper on AI coding agents using Github & other data
The auto-complete tools (Copilot) led to 2.2x more code, local agents like original Claude Code led to 7.4x, & current remote coding agents 17.3x(!)
But human bottlenecks in coding means actual releases "only" went up 30%
@VaibhavSisinty This is a great student-project idea: make “can my laptop actually run this?” visible before downloading a model. I’d love to see memory bandwidth and thermal throttling added next to benchmark scores.
@JonSaadFalcon@OpenJarvisAI This local-vs-cloud split is exactly what I’m trying to understand better. Do you think the first durable on-device use cases are mostly latency/privacy, or can small models also win on cost once agents run many steps?
LLM inference batching has a hidden curve.
Small batch:
weights dominate
GPU underutilized
expensive per token
Medium batch:
weights amortized
GPU utilized
= best economics
Large batch:
KV cache dominates
memory bandwidth becomes bottleneck
latency rises
At low batch size, you pay to reload the model.
At high batch size, you pay to remember everyone’s context.
@bridgemindai This makes me think the real moat for coding agents may be the eval loop, not just the agent UI. If the benchmark maps to actual repo work, the demo becomes much easier to trust.