BRAIn Lab × MBZUAI — 5 years of collaboration 🔥
Together, we’ve prepared a survey on Byzantine attacks — link below 👇
https://t.co/sNGzIN0K5L
Despite a challenging period in Abu Dhabi, the work continues. Supporting our colleagues 🙏
To get more details👇🏻
📄 Paper: https://t.co/mOhT8fwWEi
🖇️ References:
[1] https://t.co/rxHD8xjE0e
[2] https://t.co/WoVDUw4qLi
[3] https://t.co/Anw3bZp5ox
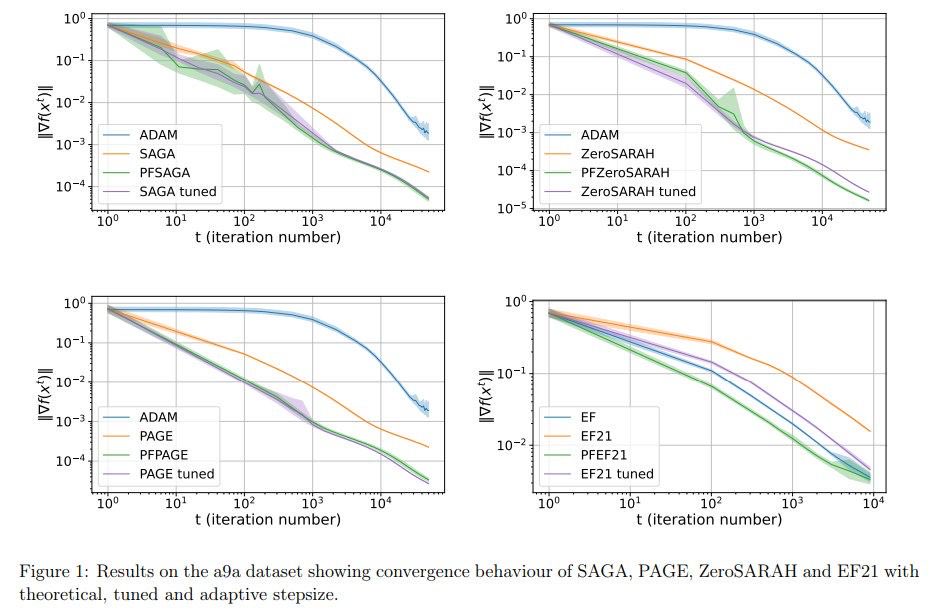
Adaptive step sizes without knowing the smoothness constant? That’s real! Compatible with ANY variance-reduction method — finite-sum, distributed, coordinate sketches included
📜 Unified Theory of Adaptive Variance Reduction
From pure SGD to advances like variance reduction
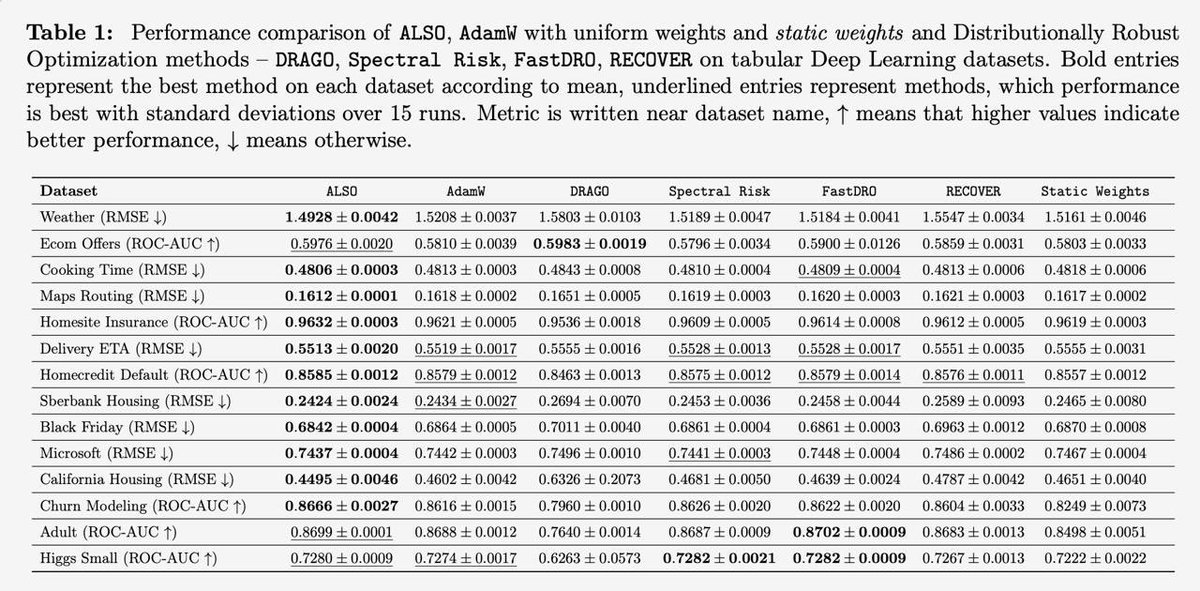
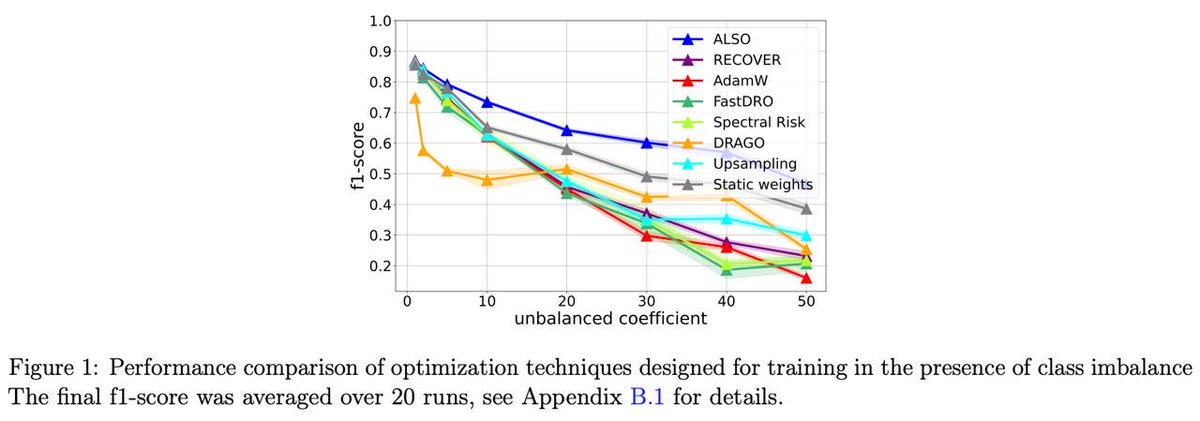
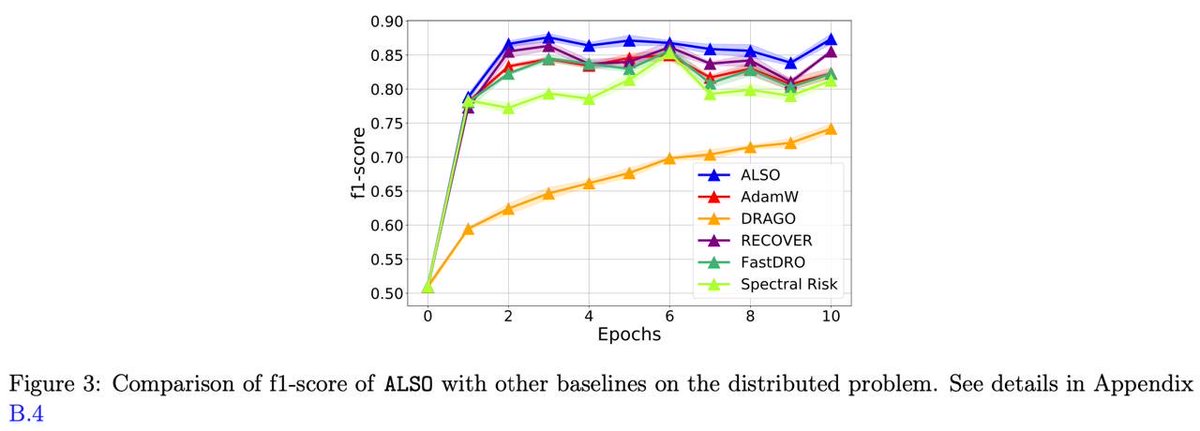
Struggling with data heterogeneity in your deep learning projects? We introduce ALSO, a new, practical Distributionally Robust Optimizer (DRO)🚀
📜 Paper thread for "Aligning Distributionally Robust Optimization with Practical Deep Learning Needs"
We tested ALSO across diverse setups with real-world data heterogeneity, including:
• Class-imbalanced datasets
• Tabular DL
• Robust & distributed training
• Split learning
In all scenarios, ALSO showed superior performance over both standard approaches and DRO baselines