@OpenAI is so lucky to have @TairanHe99!
@TairanHe99 is the first PhD student to graduate from my group, and it only took him two years and eight months to get this degree (Sep 2023 → Apr 2026).
When @TairanHe99 joined my group, I thought general-purpose humanoids were an interesting research problem, rather than a solution. Humanoid whole-body control barely worked. Hardware broke everyday. Physical AGI was not even a legitimate dream.
I always joke that “nothing really works in robotics,” but looking back, the community has made incredible progress—and Tairan has been a big part of that journey.
I am incredibly proud of everything @TairanHe99 has achieved: @CMU_Robotics Presidential Fellowship, @nvidia Graduate Fellowship, many open-source contributions to the community, and WhynotTV podcast—one of the most influential deep tech podcasts, to name just a few.
@TairanHe99’s thesis: Scalable Sim-to-Real Learning for General-Purpose Humanoid Skills. Committee members: me, @ChangliuL, @kkitani, Marco Hutter, and @pabbeel.
some news: I’ve joined OpenAI.
After wrapping up my PhD in Robotics, I’m excited to keep working toward AGI in the physical world.
exciting journey ahead :)
I’m so tired of writing rebuttals to this kind of “lack of novelty” review: “This paper trivially combines A, B, and C, so the algorithmic novelty is limited.”
Technically, most (if not all) robotics papers are convex combinations of existing ideas.
I still deeply appreciate A+B+C papers—especially when they deliver:
- New capabilities: the “trivial combination” unlocks behaviors we simply couldn’t achieve before
- Sensible & organic design: A+B+C is clearly the right composition—not some arbitrary A′+B+C′
- Nontrivial interactions: careful analysis of the dynamics, coupling, or failure modes between A, B, C
- Rehabilitating old ideas: A was dismissed for years, but paired with modern B/C, it suddenly works—and teaches us why
- System-level & "interface" insight: the contribution is not any single piece, but how the pieces talk to each other
- Scaling laws or regimes: identifying when/why A+B+C works (and when it doesn’t)
- Engineering clarity: making something actually work robustly in the real world is not “trivial”
- New problem formulations: sometimes the real novelty is in the reformulation—only under this view does A+B+C make sense.
Maybe worth keeping these in mind when reviewing the next A+B+C paper : )
Generative models (diffusion/flow) are taking over robotics 🤖. But do we really need to model the full action distribution to control a robot?
We suspected the success of Generative Control Policies (GCPs) might be "Much Ado About Noising."
We rigorously tested the myths. 🧵👇
We tried to rethink modern robot learning policy design in this paper. TL;DR: Generative policies perform well NOT because of their distributional-learning formulation or their ability to capture “multi-modality.” Our proposed Minimal Iterative Policy (MIP) achieves similar performance to flow with much lower inference & training cost.
Some interesting takeaways:
1. “Multi-modal behavior” is a very nuanced concept in robotics. Robot learning cares about the conditional distribution P(a|o), where a is the action (chunk) and o is the observation.
The objective of generative modeling in vision/language is fundamentally different from the goal in control. In vision/language, we want diverse samples from the data distribution. In control, any action that leads to better downstream performance is sufficient.
Also, robotics has very little (labeled) action data, and they lie on a low-dimensional manifold. As a result, even if the marginal P(a) is multi-modal in many tasks (e.g., PushT), the conditional P(a|o) is often not multi-modal in sparse-data regions.
Empirically, we observe that the common explanation—“flow/diffusion policies win because demonstrations are multi-modal”—does not hold for most studied behavior cloning benchmarks.
2. Architecture and action representation matter more than flow vs. regression. We find that the strong performance of flow/diffusion policies is largely due to their modern architectures and action representations. UNet / Transformer designs and action chunking play a vital role. In fact, L1/L2 regression policies can match flow/diffusion when paired with the right architectures and chunking, except in a few high-precision tasks.
3. What actually helps in flow/diffusion? Stochasticity injection and supervised iterative computation.
To isolate these factors, we performed a “surgery” on flow to design Minimal Iterative Policy (MIP), a deterministic two-step policy that keeps only these mechanisms.
Surprisingly, with far lower compute, MIP is comparable to—or even better than—flow in most studied behavior cloning benchmarks.
Why? We hypothesize that these mechanisms provide good inductive biases that improve manifold adherence, especially for OOD states. Flow and MIP exhibit significantly better manifold adherence than regression.
I don’t think these conclusions are complete—there are still many mysteries. But I strongly feel we need a new subfield: “the physics/science of robot learning,” aimed at understanding fundamental learning mechanisms and principles for data-driven robotics.
As @ilyasut said for LLMs: “We’re moving from the age of scaling to the age of research.” For robot learning, I believe we must embrace the age of research to unlock better scaling to ignite the age of scaling.
🕸️ Introducing SPIDER — Scalable Physics-Informed Dexterous Retargeting!
A dynamically feasible, cross-embodiment retargeting framework for BOTH humanoids 🤖 and dexterous hands ✋.
From human motion → sim → real robots, at scale.
🔗 Website: https://t.co/ieZfG2Q4L0
🧵 1/n
Introduce SPIDER - a unified scalable dynamics-level retargeting method for both dex hand and humanoid!
What does "dynamics-level retargeting" mean? Human motions in, physically feasible high-quality robot motions out (BOTH state and action).
These robot motions are so good that you can directly open-loop execute the action sequence in the real world! Also, dynamics-level retargeting makes the downstream RL policy learning super easy since it only needs to figure out a "small residual" on top of the already physically feasible refs.
Even better, we can easily do physics-level data augmentation & robustification, such as adding external forces and changing frictions. SPIDER can be used as a data engine for real2sim2real and learning from human data.
How it works? It is based on the diffusion-inspired sampling-based optimal control framework we developed in the past (MBD, DIAL-MPC) and virtual contact guidance.
Led by @ChaoyiPan and collaboration with @Meta FAIR.
Meet BFM-Zero: A Promptable Humanoid Behavioral Foundation Model w/ Unsupervised RL👉 https://t.co/3VdyRWgOqb
🧩ONE latent space for ALL tasks
⚡Zero-shot goal reaching, tracking, and reward optimization (any reward at test time), from ONE policy
🤖Natural recovery & transition
Excited to release BFM-Zero, an unsupervised RL approach to learn humanoid Behavior Foundation Model.
Existing humanoid general whole-body controllers rely on explicit motion tracking rewards, on-policy PG methods like PPO, and distillation to one policy.
In contrast, BFM-Zero directly learns an effective shared latent representation that embeds motions, goals, and rewards into a common space, which enables a single policy zero-shot perform multiple tasks: (1) natural transition from any pose to any goal pose, (2) real-time motion following, (3) optimize any user-specified reward function at test time, etc.
How it works? We don't give the model any specific reward in training. It builds upon recent advances in Forward-Backward (FB) models, where a latent-conditioned policy, a deep "forward dynamics model" and a deep "inverse dynamics model"are jointly learned. In such a way, the learned representation space understands humanoid dynamics and unifies different tasks.
More details: https://t.co/s6lTOHDcc9
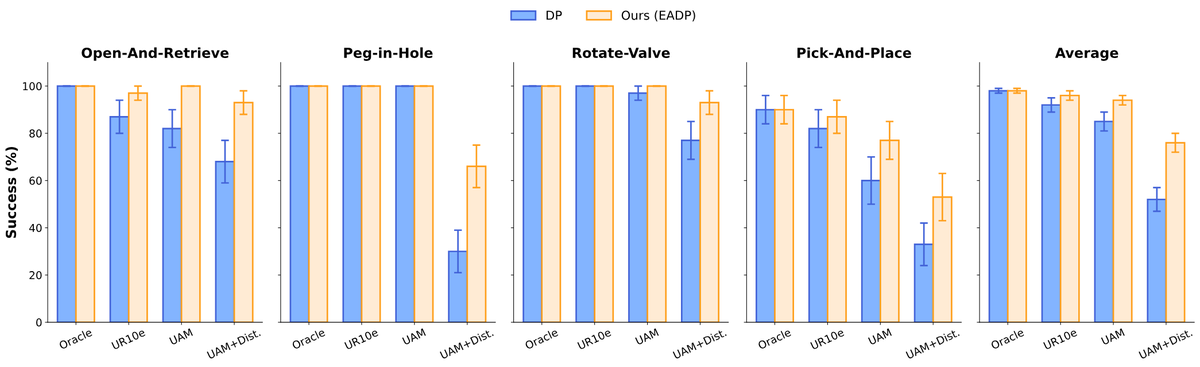
✈️🤖 What if an embodiment-agnostic visuomotor policy could adapt to diverse robot embodiments at inference with no fine-tuning?
Introducing UMI-on-Air, a framework that brings embodiment-aware guidance to diffusion policies for precise, contact-rich aerial manipulation.
100% human data -> long-horizon💡insertion on an aerial manipulator
Key: Embodiment-aware diffusion policy (EADP) steers UMI's embodiment-agnostic DP using the gradient of the low-level controller's tracking error.
My favorite: We quantify how "UMI-able" different robots are.
Didn't get chance to attend #CoRL2025 in person, but students from @LeCARLab will present three papers:
- Sampling-based system ID for legged sim2real https://t.co/sfNchZIpMU at Oral5 by @NikhilSoban353
- HoldMyBeer: learning humanoid end-effector stabilization control https://t.co/BlkgmAyboH at Spotlight3 by @li_yitang
- Humanoid Policy ~ Human Policy https://t.co/573HnICAXw at Spotlight1 by @chaitanya_cha
Check them out!
We present HDMI, a simple and general framework for learning whole-body interaction skills directly from human videos — no manual reward engineering, no task-specific pipelines.
🤖 67 door traversals, 6 real-world tasks, 14 in simulation.
🔗 https://t.co/ll44sWTZF4
On my way ✈️ to ATL for @ieee_ras_icra!
@LeCARLab will present 8 conference papers (including DIAL-MPC as the Best Paper Finalist) and one RA-L paper. Details: https://t.co/GKJwGkGkjD
Hope to meet old & new friends and chat about building generalist 🤖 with agility 🚀
🦾How can humanoids unlock real strength for heavy-duty loco-manipulation?
Meet FALCON🦅: Learning Force-Adaptive Humanoid Loco-Manipulation.
🌐: https://t.co/JbmiifEsSb
See the details below👇:
I've been working on dynamics model learning in robotics for >6 years (from the Neural-Lander paper). Training a small DNN + some regularization + some online weight adaptation have proven to be effective for specific robots in specific tasks.
LLMs have shown the power of transformer, large-scale pertaining, fine-tuning, and in-context adaptation. Can we do the same thing for dynamics model learning?
Excited to introduce AnyCar🚗, a transformer-based universal vehicle dynamics model that adapts to various cars & envs & tasks & state estimators, via in-context adaptation. It has some interesting designs akin to LLMs:
1. A seq2seq model aware of history. Input: K-step noisy state/action history, H-step future action. Output: H-step future state prediction;
2. Large-scale pertaining using 100M sim data collected in diverse sims, including Isaac Sim, MuJoCo, and F1-level Assetto Corsa;
3. Real-world "alignment" via fine-tuning on 20K real data;
4. Online "reasoning" by sampling-based MPC that rolls out action sequences using the learned model.
AnyCar shows strong adaptability in many scenarios, such as drifting in the wild with 3D-printed plastic tires.
Fully open-sourced (including the 1/16 racing car design): https://t.co/k2yrGsAz3b
🎙️I gave a talk "Building Generalist Robots with Agility via Learning and Control: Humanoids and Beyond" at the CMU RI Seminar and Michigan AI Symposium. It covers @LeCARLab's research and my thoughts on building agile generalist robots.
Recording: https://t.co/BsReMgpGSx
H2O (👉https://t.co/JvgjKGiqSi) and OmniH2O (👉https://t.co/XRxdXIUDUX) are open-sourced!
Check out our fully open-source code: https://t.co/w15CM2rsXr, featuring simulation training, motion data retargeting, and real-world deployment.
Have fun with your humanoids!