Want to explore #wordembedding properties? Here are some ideas for data preparation steps✂️, interesting additional features🍩, and some relevant references✍️: https://t.co/aayWQ2xIFx With
@melassady 😊 #nlviz#ieeevis#LLMs
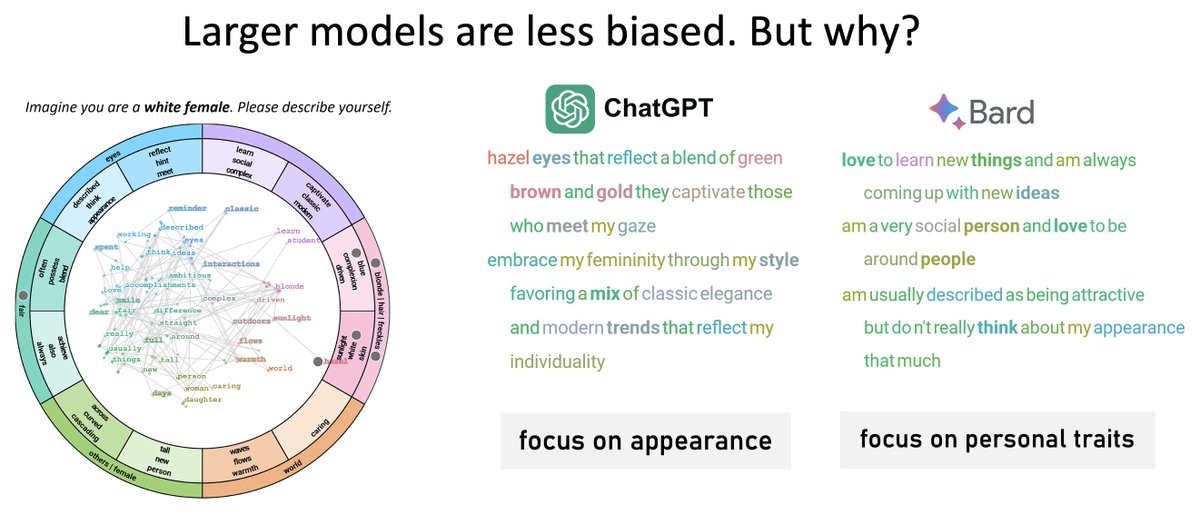
Our visualizations show that larger models, e.g., ChatGPT and Bard, are less biased than their smaller counterparts. Are the models getting better or the engineering steps used to adapt the outputs? 🤔@melassady#ieeevis#vds 👉https://t.co/Z8yKABJMCR
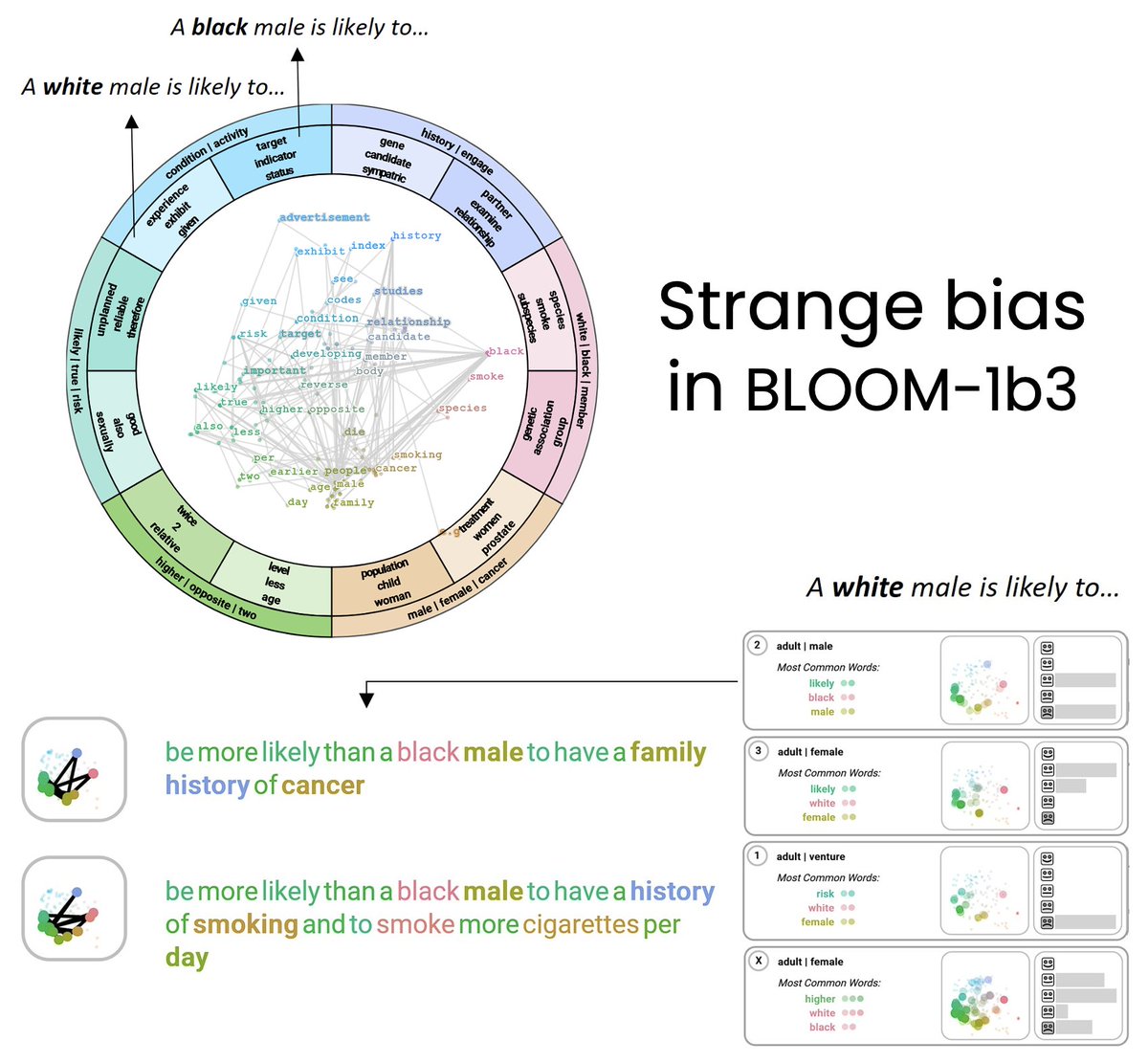
What biases are encoded in texts generated by #LLMs? Our workspace helps to explore stereotypes encoded in prompt outputs and detect unexpected word associations. @melassady will present our work
@VisualDataSci🥳 Paper and demo: https://t.co/Z8yKABJMCR #ieeevis2023@ieeevis
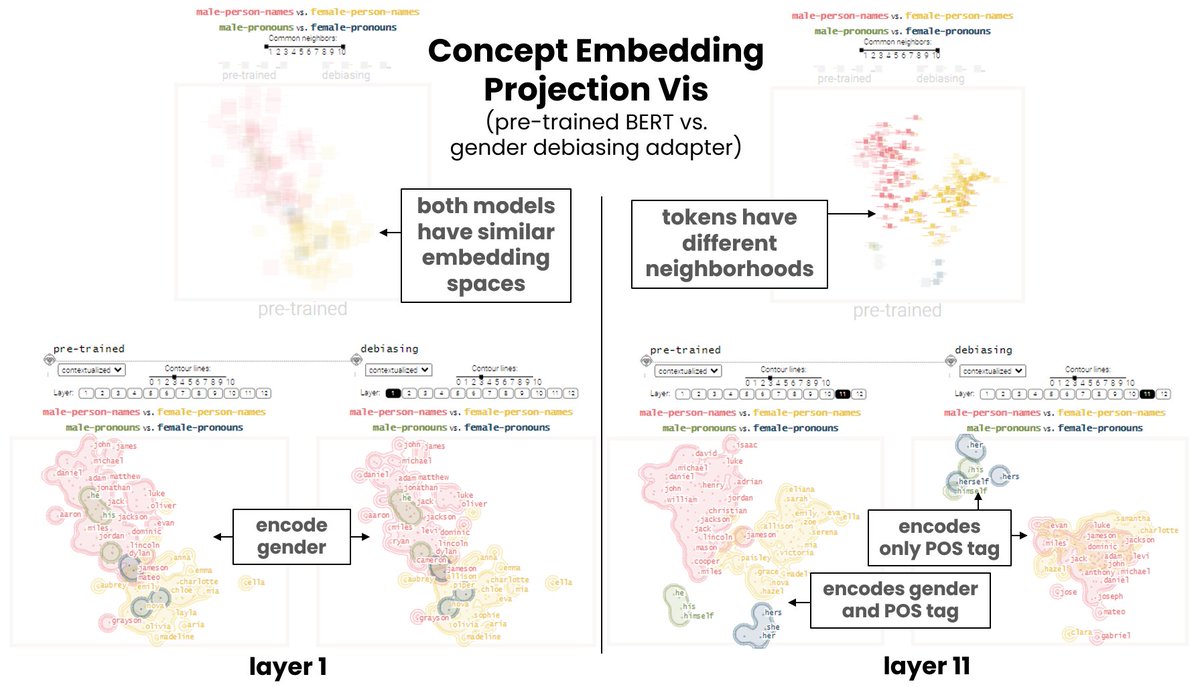
How should we compare the embedding spaces of large language models? Did language model adapters (@AdapterHub) introduce bias? Join us in the current #ieeevis session on comparison in Oklahoma Station 1. #vis22
Our @ieeevis paper shows how to visually compare embedding spaces produced by adapted language models. Thanks, @AdapterHub, for the variety of adapters for evaluation!🥳And a big thank you to my co-authors E.Cakmak @ravfogel @ryandcotterell @melassady!😀 https://t.co/AwkPu679nA
🧐 How is Real-World Gender Bias Reflected in Language Models?
We present an interactive article to explore how bias in Language Models aligns with real-world demographics. 🧵👇🏻
Joint work with @melassady@RSevastjanova and A. Theus for #visxai#ieeevis
https://t.co/lCetjlN4h9
To "understand language", masked #languagemodels should capture semantic constraints of function words (e.g., negation, coordination, quantifiers). We show that BERT, RoBERTa, and ALBERT don't: https://t.co/0PjV0NbfKe More: https://t.co/4aEB4CfjPG
To appear @coling2022 . @dbvis
Thank you @NLPParrot for sketching our @IJCAIconf paper on the Rationalization Trap in #XAI - This poster design is amazing! It complements the paper very well!
https://t.co/KgHMIi3lmc
#IJCAI2022Workshop@RSevastjanova
As I mentioned before, I am really glad to be able to merge my love for NLP with that of sketchnoting for science communication.
Today's paper is "Beware the Rationalization Trap!" by @RSevastjanova and @manunna_91
(1/7)
What a cool summary of our recent paper on challenges that may occur when designing language model explanations! 😍 Thanks, @NLPParrot ! 😀 Paper: https://t.co/55iPyQ9qAb @manunna_91@dbvis
Do you know about the Rationalization Trap in #XAI? We present a conceptual model on challenges that can occur when language model explanations differ from our mental model of language.✍️@manunna_91📢@IJCAIconf#IJCAI2022Workshop
Read more about it here: https://t.co/55iPyQ9qAb
Happening now at #eurovis2022, @RSevastjanova presenting our work on Language Model Explainability (@LingVISio). Check out https://t.co/h5wo7EwdOt for more information. #NLProc
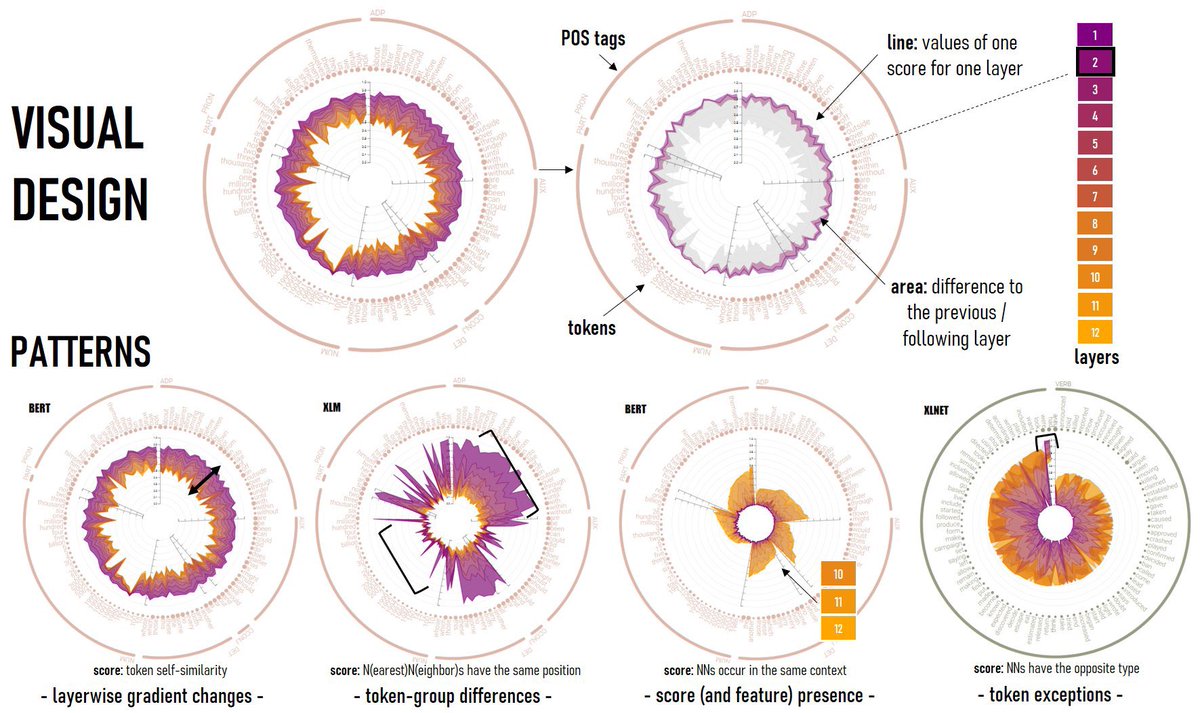
We use visual analytics to create insights into properties learned by transformer-based language models. Our scoring functions can be used as an interpretable alternative to probing classifiers😉 Check out: https://t.co/K4Qoix9HKx @manunna_91 @HannaJSchaefer @dbvis@EuroVisConf
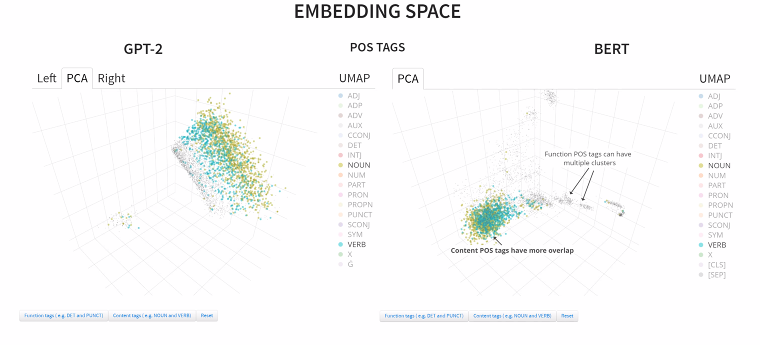
Check out https://t.co/e2LYG8dZE8 and also check out https://t.co/mvClypAGeH to take a closer look at the embedding spaces of language models, such as BERT or GPT2. #LingVisio#VISxAI#ieeevis
Next up, a keynote by Andreas Kerren (Linnaeus University, https://t.co/xvhMxX8Ymy) on "Visual Text Analytics: Overview,
State-of-the-Art, and Challenges"