Very excited to announce our paper: "DiffCD: A Symmetric Differentiable Chamfer Distance for Neural Implicit Surface Fitting" at #ECCV2024!
Paper: https://t.co/D9ebBoXrbU
Code/project: https://t.co/r05UpSMZEh
Happy to share NOVA3R! 🔥 #ICLR2026
We explore latent 3D representations with global decoding for non-pixel-aligned reconstruction. Our model recovers visible and occluded geometry with non-overlapping structures, taking a step toward faithful synthesis of real-world scenes.
🚀 #CVPR2026 paper alert: 🦏 RINO: Rotation-Invariant Non-Rigid Correspondences
Our network learns robust SO(3)-invariant features directly from raw 3D geometry. End-to-end, no pre-alignment or handcrafted descriptors!
Joint work @tumcvg & @Stanford.
Krea real-time editing is so cool..! Great job team Krea. Love that you continue to push for these real-time workflows WITH control ❤️
Here, I've combined it with my favorite 3d sculpting tool, Dreams (someone should pick this up and continue the incredible work Media Molecule started), and a bit of point-cloud magic with Apple sharp and Octane render.
Share this if you agree its incredible, or heck, share it and make fun of me for continuing to think workflows like this is the future if you don't agree :P
@tumcvg goes #ICCV2025 in Hawaii! 🛫🌋
We are very proud of our students who will present five papers (+ 1 workshop) during the conference!
In particular, check out Back-on-track, which is an award candidate. (Congrats @wrchen530!)
Our paper "The Monado SLAM Dataset for Egocentric Visual-Inertial Tracking" has been accepted at #IROS2025!
Because SLAM/VIO datasets were getting a bit too easy :)
🔗 https://t.co/R4E4vrawUx
📄 https://t.co/lID5TL1HY3
🎥 https://t.co/6jL16CEcds
(1/5)
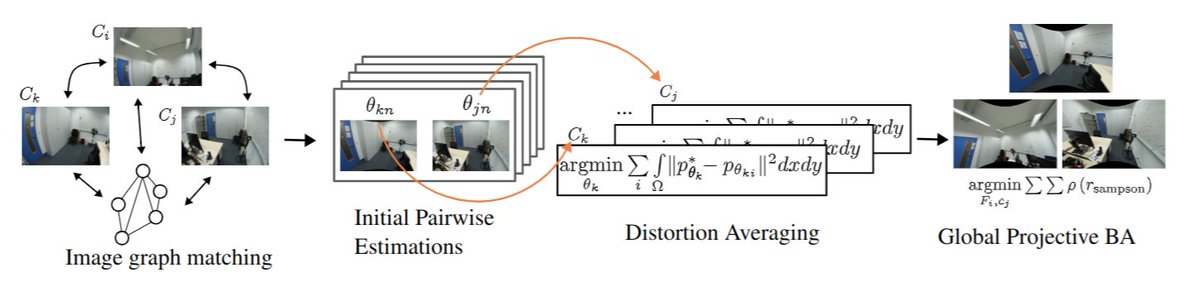
The code for our #CVPR2025 paper, PRaDA: Projective Radial Distortion Averaging, is now out!
Turns out distortion calibration from multiview 2D correspondences can be fully decoupled from 3D reconstruction, greatly simplifying the problem
https://t.co/P3zAhYfoKM
The key is working in projective space, estimating only fundamental matrices and distortion parameters. These can then be used to initialize full SfM, leading to an overall more robust pipeline.
Paper: https://t.co/MqzHlCMvvz
🦖 We present “Feed-Forward SceneDINO for Unsupervised Semantic Scene Completion”. #ICCV2025
🌍: https://t.co/bHLwuTDqar
📃: https://t.co/jhKiToJrAO
💻: https://t.co/vSEcJKxlaR
🤗: https://t.co/ZUGMQagRyv
w/ A. Jevtić @felixwimbauer@olvr_hhn C. Rupprecht @stefanroth D. Cremers
Join us for a full-day 3D Shape Analysis tutorial at @CVPR in Nashville, on Thursday, June 12, from 9:15 AM to 5:00 PM in Room 204!
👉 More details and the full schedule are available at: https://t.co/YupPJr6SHx
Can we match vision and language representations without any supervision or paired data?
Surprisingly, yes!
Our #CVPR2025 paper with @neekans and Daniel Cremers shows that the pairwise distances in both modalities are often enough to find correspondences.
⬇️1/4
Can you train a model for pose estimation directly on casual videos without supervision?
Turns out you can!
In our #CVPR2025 paper AnyCam, we directly train on YouTube videos and achieve SOTA results by using an uncertainty-based flow loss and monocular priors!
⬇️
Check out our recent #CVPR2025 paper AnyCam, a method for pose estimation in casual videos!
1️⃣ Can be directly trained on casual videos without the need for 3D annotation.
2️⃣ Based around a feed-forward transformer and light-weight refinement.
♦️ https://t.co/fB6pYn4uDJ
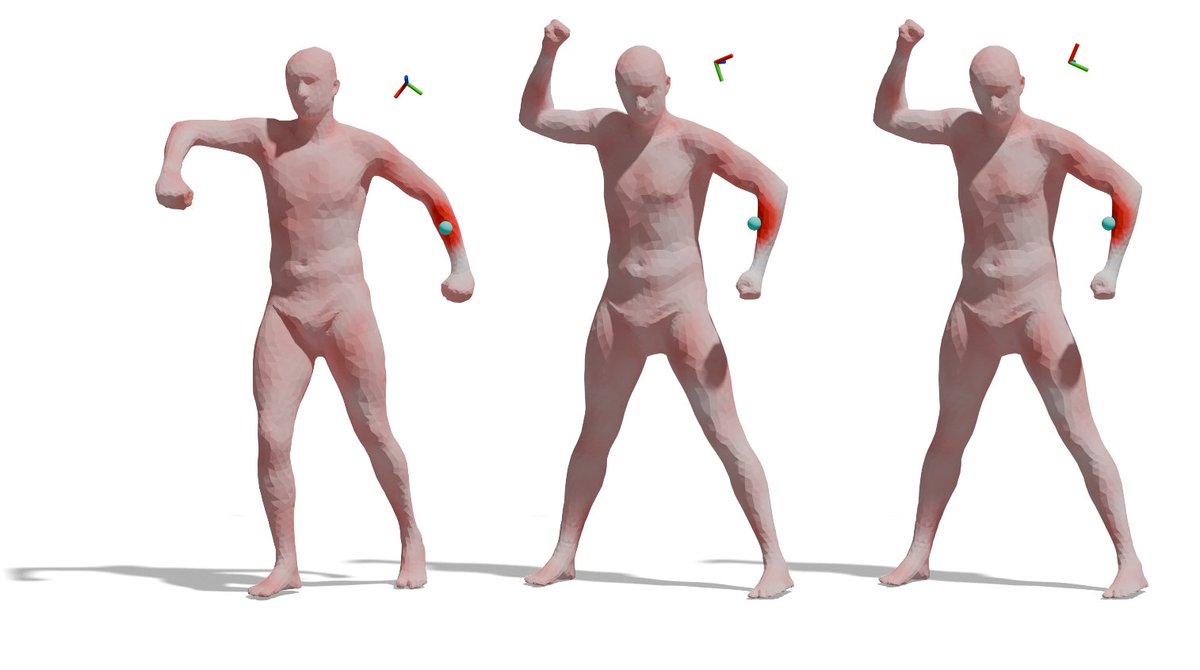
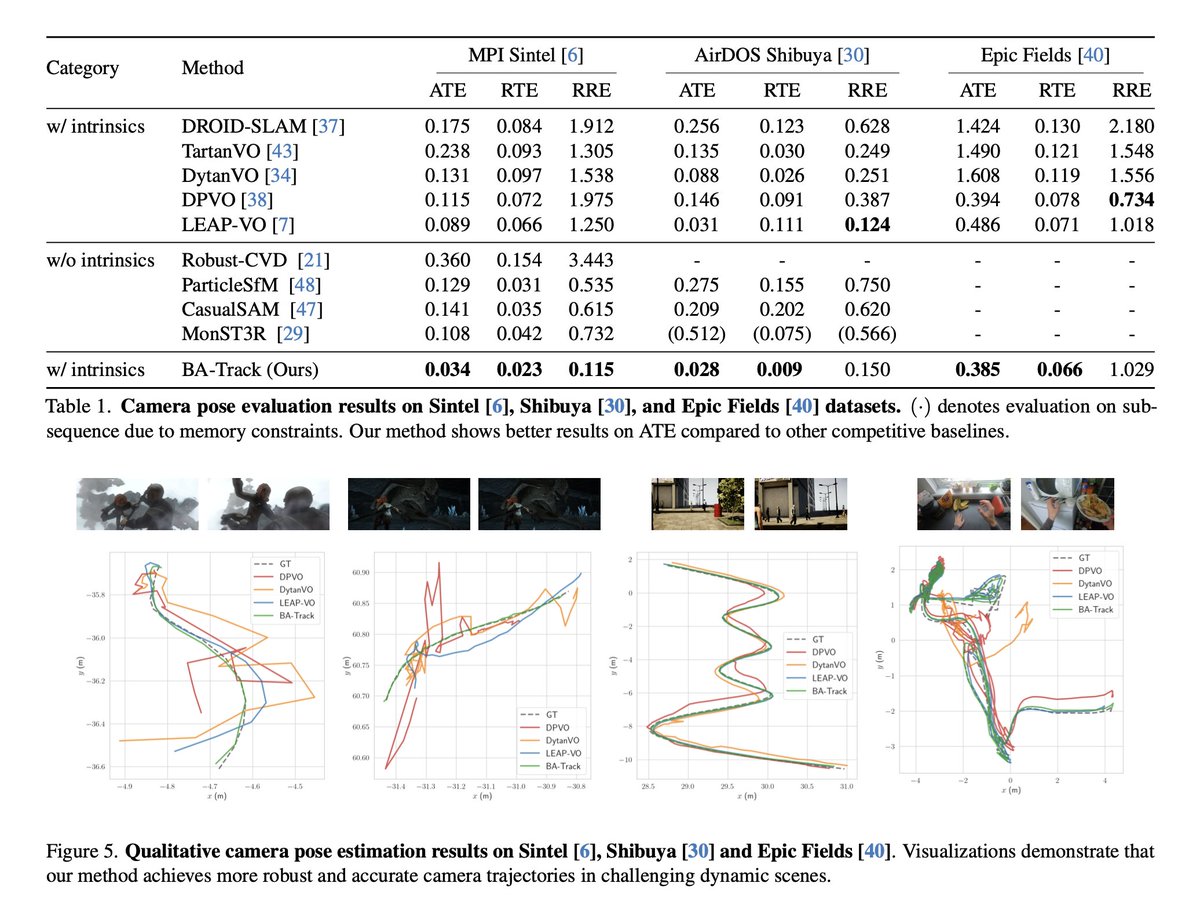
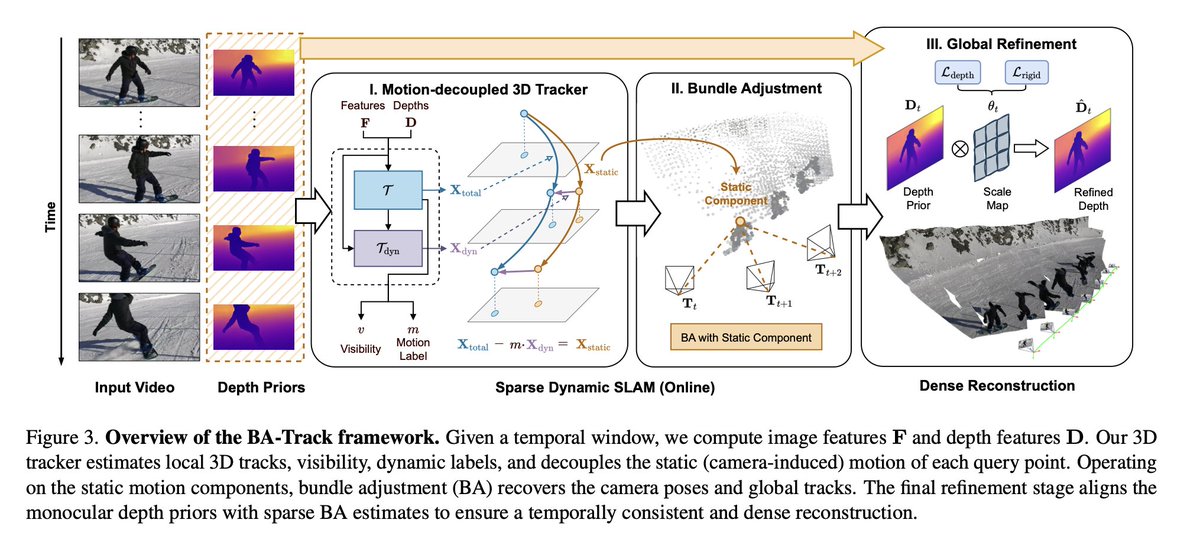
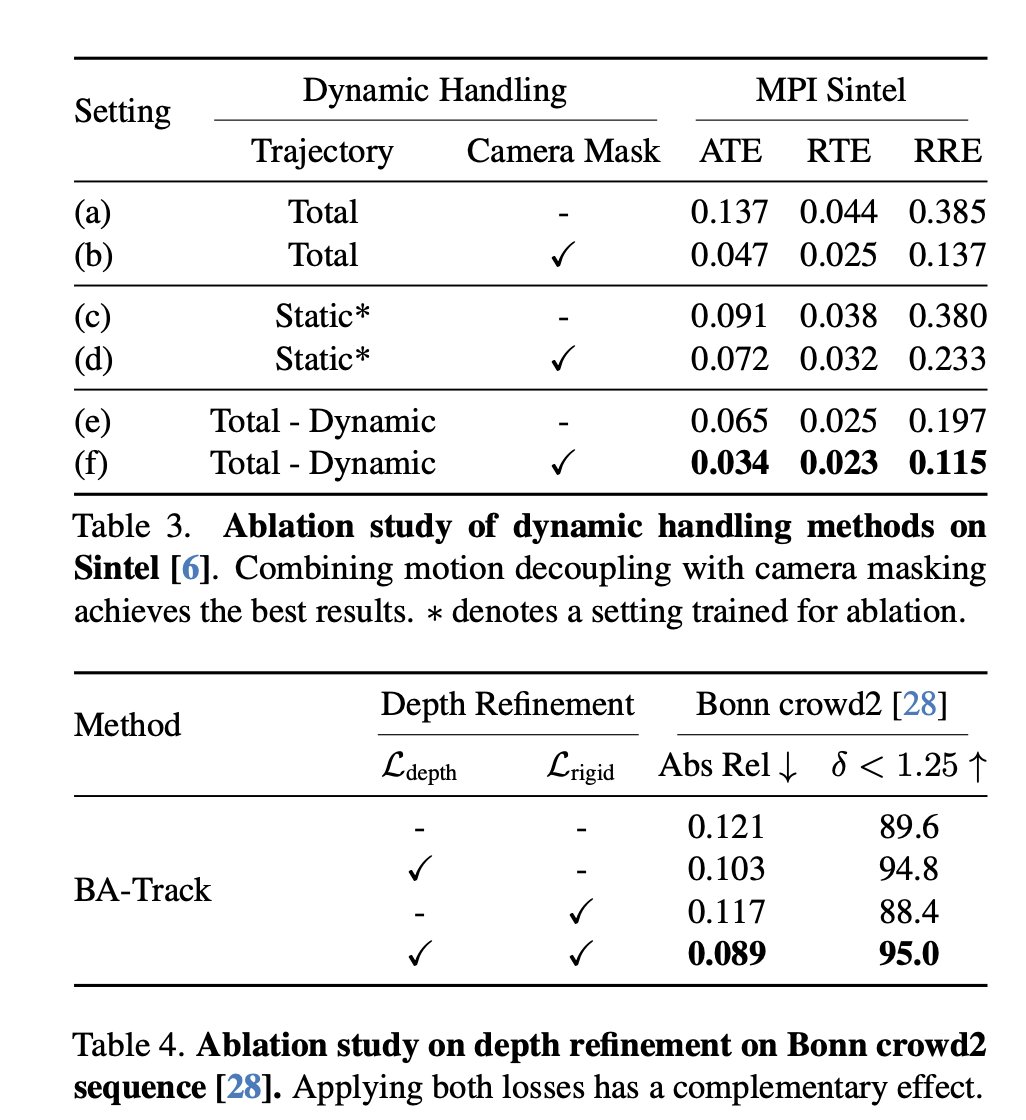
Back on Track: Bundle Adjustment for Dynamic Scene Reconstruction
Weirong Chen, Ganlin Zhang, @felixwimbauer , Rui Wang, @neekans Andrea Vedaldi, Daniel Cremers
tl;dr even for non-rigid SfM you can do BA on static parts -> improves everything.
https://t.co/zBDkqBHfs4
We are thrilled that our group has twelve papers accepted at #CVPR2025! 🚀
Congratulations to all of our students for this great achievement! 🎉
For more details, check out: https://t.co/pTTuMlMUdp
🥳 Thrilled to announce that our work, "4Deform: Neural Surface Deformation for Robust Shape Interpolation," has been accepted to #CVPR2025
💻 Check our project page for more details: https://t.co/JvMEkLWony
👏 Great thanks to my amazing co-authors. @zehranaz98@_R_Marin_
Introducing MASt3R-SLAM, the first real-time monocular dense SLAM with MASt3R as a foundation.
Easy to use like DUSt3R/MASt3R, from an uncalibrated RGB video it recovers accurate, globally consistent poses & a dense map.
With @eric_dexheimer*, @AjdDavison (*Equal Contribution)