PROGRESSION: Claude Opus 4.8 (@AnthropicAI) sets a new high on LLM Stats Index after 3 years of progress.
> 68 on LLM Stats Index
> Frontier gained 85 index points over the 3.3-year window
This shifts the predictions towards a more optimistic scenario of complete benchmarking saturation.
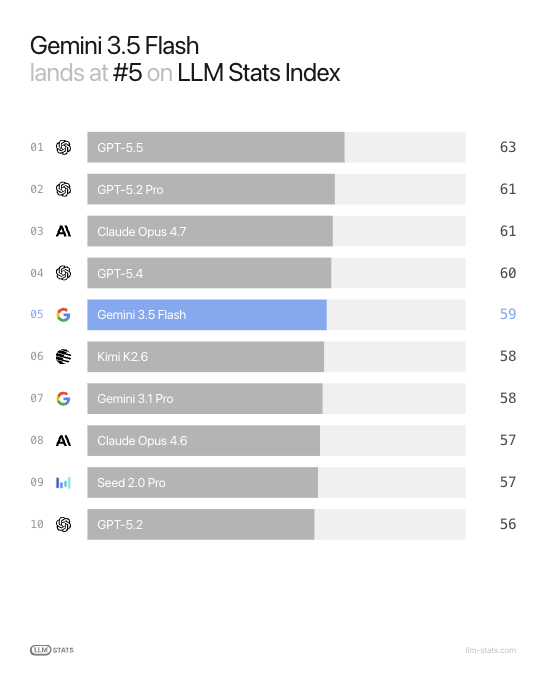
NEW: Gemini 3.5 Flash (@GoogleDeepMind) lands at #5 on LLM Stats Index.
>4x faster than other frontier models
>$1.50 / $9 per 1M tokens
It's significantly faster than other frontier models and the quality has increased significantly.
It's also the best tool calling model we've tested lately.
@polynoamial Hey Noam! We're in the process of building new hard benchmarks focused on coding/long-ctx.
We're a team of 2, fully focused on AI capability tracking since last year.
Is it possible we could talk with someone from your team to align on what is maximally useful to measure?
@LlmStats' index predicts benchmark saturation by mid-2027. GPT-5.5 leads, but human-knowledge evals are topping out. Surprised me, now focusing on intelligence per watt and inference speed. That's the ceiling for agent productivity in real workflows.
Today we're introducing the LLM Stats Index.
For 3.2 years, we've tracked every frontier model release. The Index aggregates 200+ benchmark results into a single TrueSkill rating per model, spanning law, healthcare, coding, tool calling, vision, and reasoning.
Across every category and every modality, the leading model on the Pareto Frontier is GPT-5.5 (@OpenAI).
On our trajectories, human-knowledge benchmarks saturate by mid-2027.
Capability has been the primary axis. The field is converging on it. Two more are opening.
The first is efficiency: total task cost is the cleanest proxy we have for intelligence/watt. The second is throughput: inference speed becomes the productivity ceiling once models are cheap and good enough.
We're building the next generation of long-horizon coding, tool use, and long context benchmarks.
If you're working on long-horizon evaluation in real domains, we'd like to chat.
We estimate that GPT-5.5 will be the strongest available model for all use cases according to our Reasoning Index, that covers 110+ benchmarks, GPT-5.5 is surpassing Claude Opus 4.7.
Congrats @OpenAI 🔥
Kimi K2.6 is now the best Open Weights model on LLM Stats.
Congrats @Kimi_Moonshot team.
It's the first time we see an open model directly competing with closed alternatives at 25% of the cost.