LocalAI 3.9 and 3.10 are out! 🎉
Now we are a fully extensible OS for your AI applications.
Highlights:
🤖 Support for Open Responses and Anthropic API
🗓️ Schedule background jobs (Cron/API)
🎥 New UI for Text-to-Video, Qwen TTS
⚡ Easy GPU: One docker image for everything👇
Scaling LLMs across nodes? When a follow-up lands on a replica that never saw your chat, the whole prompt is recomputed and the KV cache wasted.
LocalAI fixes this at the router: cache-aware routing across a mixed fleet of vLLM + SGLang + llama.cpp + ...
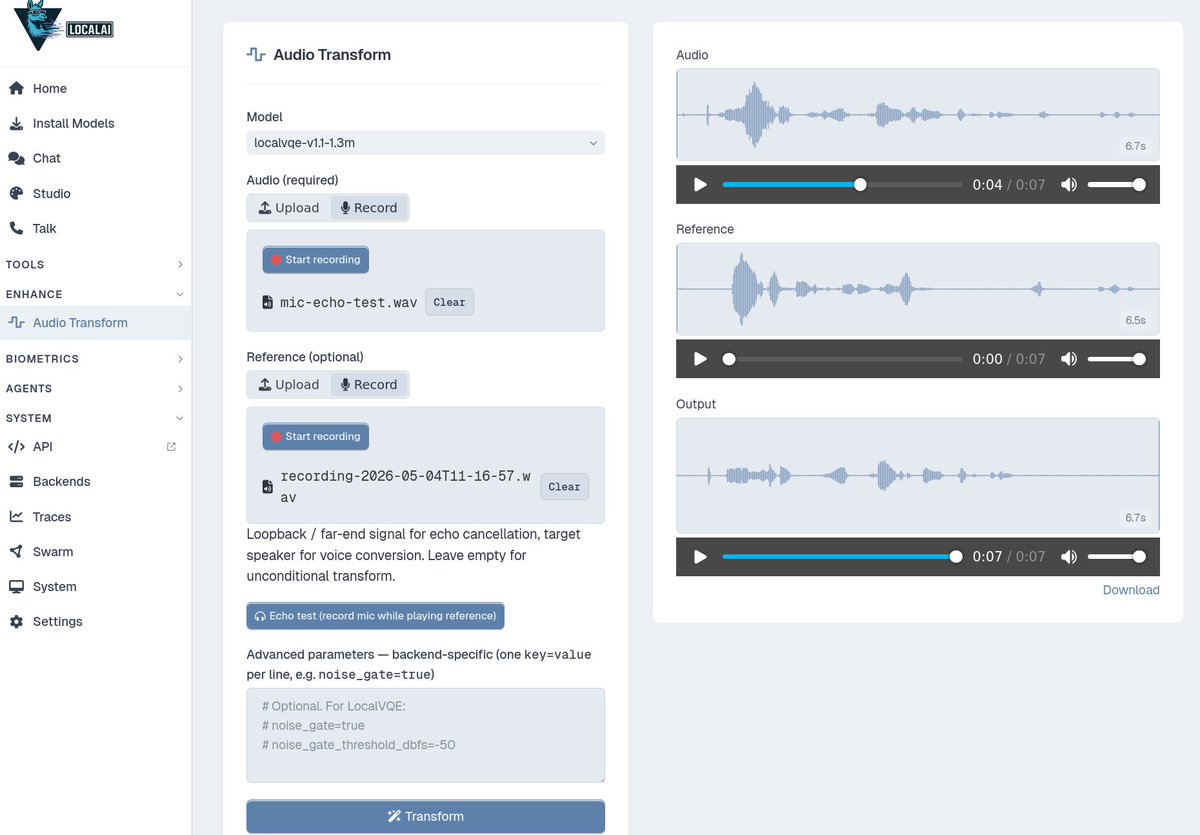
LocalVQE v1.3 released! This tiny neural network cancels echo and suppresses noise in realtime on CPU (thanks to GGML). This new release ups the model size slightly and better suppresses noise around near-end speech.
This kind of model helps when having voice conversations on loud speaker and in noisy environments.
parakeet.cpp: native C++/ggml (@ggml_org) inference for @NVIDIAAIDev's Parakeet, one of the best speech-to-text models out there, from the @LocalAI_API team.
Every Parakeet model (TDT/CTC/RNNT/hybrid + cache-aware streaming), byte-for-byte identical output to NeMo, now running anywhere with no Python and even a bit faster, on CPU and GPU.
Quantized GGUF on @huggingface 🤗
Huge thanks to @ggerganov for ggml and to @NVIDIAAIDev for releasing Parakeet! 🧵
rf-detr.cpp: native C++/ggml (@ggml_org ) inference for @roboflow 's RF-DETR (my go-to for object detection and segmentation!) from the @LocalAI_API team.
All 11 variants (5 detection + 6 segmentation), running at PyTorch speed (slightly, ~8% faster on CPU benchmarks), without Python dependencies at f16.
Models available in @huggingface 🤗
Thanks to @ggerganov for ggml and @SkalskiP for rf-detr to make this possible!
🧵
LocalAI ( @LocalAI_API ) 4.2.0 is out, just few numbers and facts:
- +392 commits ( we squash these 😄 )
- +11 Backends: voice and face recognition, vibevoice.cpp (from me), LocalQVE from @jichiep and among @sgl_project , @__tinygrad__ , @no_stp_on_snek 's Turboquant, ik_llama.cpp, sam.cpp from @el_PA_B
- Many new QoL improvements, increased sglang and VLLM support and hardening on distributed mode
- 16+ new contributors ! Thanks to the community!
LocalAI is all about give you flexibility to run the latest from the community, and ds4 support from @antirez is on its way!
This is the year of Local AI!
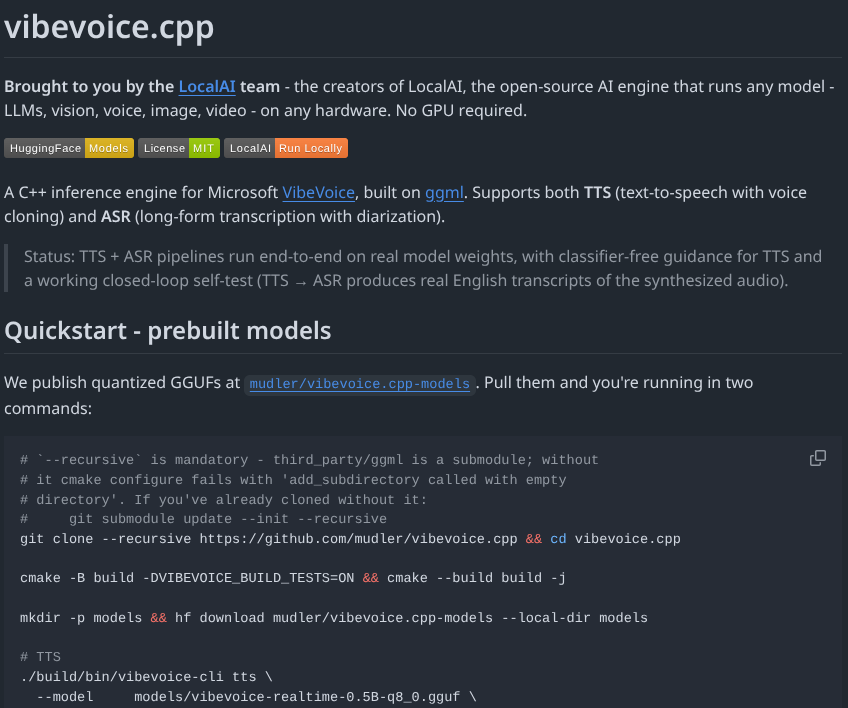
Say hello to vibevoice.cpp, @Microsoft 's Vibevoice in pure C++ with @ggerganov 's ggml (@ggml_org).
TTS and ASR (with diarization). CPU + CUDA + Metal + Vulkan via ggml backends. Quantized models live on @huggingface.
Built with ❤️ from the @LocalAI_API team
https://t.co/ZhFYd54uhz
@LocalAI_API next release will blow it. It features many new backends that lets you swap and run AI models in different ways and bench side by side in a way that you couldn't do before:
- tinygrad (by cc @__tinygrad__ ) - one of the most flexible and promising torch replacement (if you'd ask me)
- sglang ( @sgl_project ) one of the fastest engine out there
- ikawrakow/ik_llama.cpp fork which optimizes GGUF on CPUs
- TheTom/llama-cpp-turboquant ( Turbo quant llama.cpp fork by @no_stp_on_snek )
- qwen3tts.cpp (qwen 3 tts everywhere!)
- kokoros (rust implemenetaion of kokoro, damn fast on CPU!)
All in a compact, extensible framework that lets you download, manage, remove and manage backend releases with ease, allowing to share your instance with authentication and distribute it across all your devices!
How to install and run @LocalAI_API using Docker compose. Including a tour of the basic features like installing models and backends for inference, debugging requests, chatting, images, TTS, voice sessions, using the API and so on.
Not everyone knows - but @LocalAI_API has two ways of distributing load across nodes (if you are building a cluster of GPUs)
1) P2P Fedaration: this uses @libp2p behind the scenes - has a ledger and an in-memory state storage which is distributed across nodes. It uses Gossip protocol for co-ordination, suited for community use (very simple to setup)
2) full-fledged distributed mode: LocalAI uses workers that are connected via NATS and to the frontend. This allows to scale horizontally multiple frontends and to multiple worker machines. LocalAI orchestrates building, maintenance, of models and backends. LocalAI has an extensible backend system that allows to support ANY backend for inferencing.
With 2) you get control, with 1) you get decentralization.
Ok, notoriously I don't sleep that much. Time to share @LocalAI_API 4.1.0 (why not?) !
TLDR:
- Distributed, hybrid clusters with production ready setup
- Built-in auth, quota, user metrics
- Fine-tuning and quantization from the UI
🔥Details below! 👇
I just blind-tested two quants of Qwen3.5-35B-A3B (MoE, 35B total / ~3B active):
• Unsloth UD-Q4_K_XL (standard 4-bit)
�� APEX-I-Quality (MoE-aware, near-Q8 claims, +~1GB)
And, I am quite excited ;)
I've just released APEX (Adaptive Precision for EXpert Models): a novel MoE quantization technique that outperforms @UnslothAI Dynamic 2.0 on accuracy while being 2x smaller for MoE architectures.
Benchmarked on Qwen3.5-35B-A3B, but the method applies to any MoE model.
Half the size of Q8. Perplexity comparable to F16. Works with stock @ggml_org's llama.cpp.
Open source (of course!), with ❤️ from the @LocalAI_API team.
👇Links to the model, repository and benchmarks below! (+ Bonus TurboQuant benchmarks with @no_stp_on_snek's TQ+! )