Day 6 and it finally clicked — why there are two completely different LLM serving stacks.
vLLM = the friendly one.
Install → point at model → it just works. Great defaults, easy swaps, fast enough for 90% of use cases.
TensorRT-LLM = what NVIDIA runs at massive scale.
A compiler that bakes your model + hardware + workload into one ultra-optimized binary. Often dramatically faster (sometimes 2-3x).
The cost? Steep learning curve, rebuilds, painful debugging.
Simple decision rule:
→ Normal product / most use cases? vLLM
→ Huge scale where milliseconds = serious $? TensorRT-LLM
For my DGX Spark + real estate analyst? vLLM wins.
For OpenAI scale? Different story.
What are you running in production right now? (vLLM, TensorRT-LLM, SGLang, or other?)
@Scobleizer Excellent. Let me know if he needs a tester. Have one sitting in my drawer from when it was first released but couldn’t really do anything with it at the time.
You can make a big model 2-3x faster without retraining it, without quantizing it, without changing a single weight.
Here's the trick: you run a fast, dumber model alongside the big one. The small one drafts a few tokens. The big one verifies them all in one pass instead of generating them one at a time.
The math works because verifying tokens is way cheaper than producing them. The big model does one forward pass to check 5 tokens instead of 5 separate passes to produce them.
Net result: 2-3x throughput, no loss in quality. The exact same output the big model would have produced solo, just faster.
This is what Medusa and EAGLE do under the hood. Open-source frameworks like vLLM and TensorRT-LLM ship it.
The thing that surprised me today: one of the breakthroughs that made modern AI serving practical wasn’t a new model or a new chip.
It was memory management.
When a language model generates tokens, it stores attention memory for everything it has already processed. That memory is called the KV cache, and it gets huge fast.
Older serving stacks often reserved or managed this cache in large chunks, which meant GPU memory got wasted when conversations were shorter, uneven, or finished at different times.
The vLLM team borrowed an old idea from operating systems: virtual memory and paging. Split the KV cache into small blocks. Allocate them on demand. Store them wherever there’s room. Reclaim them when the request ends. Share them when requests reuse the same prefix.
The result: far less wasted GPU memory, bigger batches, and much higher throughput.
It’s an OS-level idea applied to a model server.
Day 4 and I finally understood why vLLM is the library everyone talks about.
Picture a hotel. The old way of running an inference server was like giving every guest a huge room based on how long they might stay. You filled up the hotel fast, even though most rooms were half empty.
PagedAttention is the hotel learning to split rooms into modular blocks, give each guest only what they actually need, add space as their stay gets longer, and reclaim it the moment they leave.
In LLM terms, that means managing the KV cache like virtual memory. Less wasted GPU memory, more requests batched together, higher throughput.
That’s why vLLM matters. Not because it changed the model, but because it changed how efficiently the model could be served.
Yesterday's learnings: the GPU is a kitchen. One user = one chef cooking one dish.
The thing I didn't get until today: even with one chef, there's a ton of dead time. Plating happens, the chef walks across the kitchen, the oven preheats. That's wasted capacity.
Continuous batching is the kitchen learning to start cooking dish two while dish one is plating. Dish three slides in while dish two is on the stove. Nobody waits for someone else's dessert to finish before they can order.
That's how a single DGX Spark goes from serving 1 person to serving multiple people on the same chip.
I have talked to some AI companies that have built this for the construction market. They have reported it works really well and the client saved a ton of money on not only inventory management but time to build on projects.
Seems like the construction inventory management would be harder to solve. Or we are about to have a bunch of horribly built homes and industrial buildings.
Sources: Starbucks shut down an AI program for automating inventory counts, nine months after deploying it, after it frequently miscounted and mislabeled items (@waylon_wc / Reuters)
(Visit Techmeme dot com for the link and full context!)
@mr_r0b0t@NVIDIAAI I was one of these people. Didn't really know what I was going to use it for. Bought it to experiment. Using NVIDIA free resources now and had Codex create me a 12-week course to learn the NVIDIA ecosystem step by step.
https://t.co/SZkOFhrm8g
Spent days redesigning a landing page with Claude and Codex. Thought it was solid.
My wife took one look and started picking it apart.
Sent her comments to Claude.
Claude replied: “Your wife is right. She just saved you from a real mistake.”
So now my wife loves AI.
If even Microsoft is feeling the AI spend, how is the average small business supposed to play?
The labor TAM for AI sits mostly with SMBs. They make up roughly half of private sector employment. But right now the vast majority of them are barely touching AI at all.
Recent numbers show only 25 to 35 percent of small businesses have tried any generative AI tools. Most of that is light use. The ones actually stitching together subscriptions and avoiding big API bills are probably under 15 percent of the market. That means we have only scratched a tiny fraction of the potential labor TAM.
When the cheap options get more expensive or go away, it will be even harder to get these businesses onboard. Most SMBs do not have the budget for heavy API usage. They do not have the internal skills or time to train up and incorporate AI. And they do not have money for a consultant team or FDEs.
That means the big productivity gains and labor market changes people are talking about will take longer than expected.
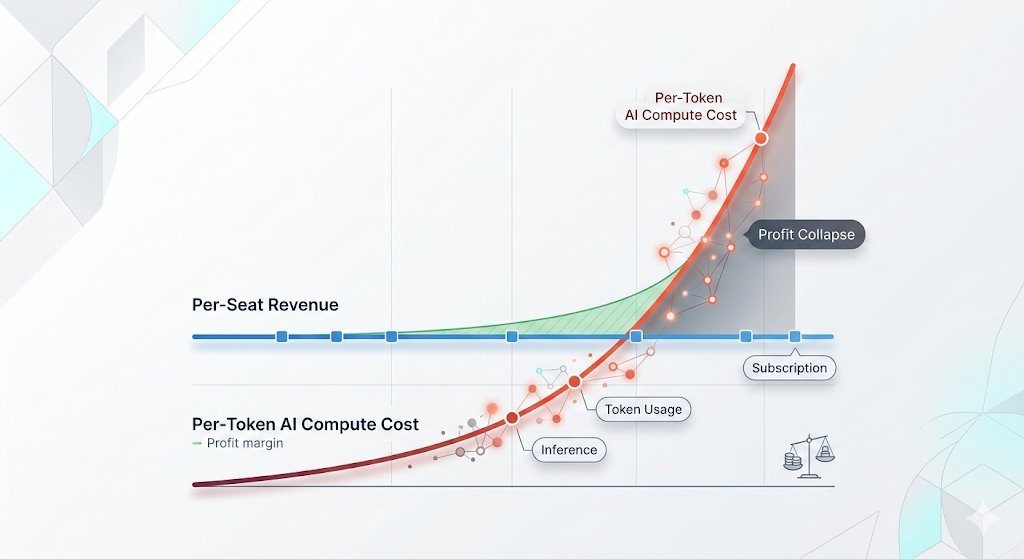
🦔Microsoft canceled its internal Claude Code licenses this week after token-based billing made the cost untenable, even for a company with effectively infinite cloud resources. Uber's CTO sent an internal memo warning the company burned through its entire 2026 AI budget in just four months. American AI software prices have jumped 20% to 37%, and GitHub (owned by Microsoft) is dropping flat-rate plans for usage-based billing across its products.
My Take
The AI subsidy era is ending in real time. The same company that put $13 billion into OpenAI and built the Azure infrastructure powering most of Anthropic's compute just looked at the bill from a competitor's coding tool and decided it was not worth paying. That is not a productivity failure on Anthropic's end. Token-based pricing is forcing every enterprise customer to confront the actual cost of running these models at scale, and the number turns out to be far higher than the flat-rate experiments suggested.
This ties directly to my Gemini Flash post yesterday. Anthropic, OpenAI, and Google all raised effective prices in the last six months. Enterprises that built workflows assuming AI costs would keep falling are now watching annual budgets evaporate in months. Two outcomes look likely from here. Either enterprises scale back AI usage to fit budgets, which slows the revenue ramp the labs need to justify their valuations ahead of IPOs, or the labs cut prices and absorb the losses, which makes the unit economics worse at exactly the wrong moment. Both paths land in the same place, the numbers stop working, and somebody has to take the writedown.
Hedgie🤗
Probably the best framing on some of the decision that have been made regarding staff reductions.
The biggest issue is that is has not come out of the leaders mouth.
Everyone is obsessed with AI making a 10x engineer a 1000x engineer.
The recent reductions at CloudFlare and Click have me me realize the plot is equally about the inverse: AI amplifies the *negative* impacts of poor performers.
If a person with poor taste, who makes mediocore judgement calls, and doesn't properly build things customers love is able to produce 10x more work - does a company want that?
Hell no! Productivity isn't just about as many people as possible tokenmaxxing. AI is a double edged sword, especially when it's used to produce net new work.
If you give a bad artist a pen that can draw 100x as fast, you're going to pile up with a lot of junky artwork very quickly.
And since it happens so quickly leaders are now able to see quickly who is Picasso and who is not and adjust accordingly.
Biggest takeaway so from from @ARKInvest Big Ideas Summit
“Don’t let AI do your thinking” - Andy Tang, Draper
You also have to question how many investment memos are drawn up by AI where there is no real thought behind it.
The same model can be "fast" or "slow" depending on whether you're asking as a user or as the person running the service.
If you're a user, fast means: did my answer come back quickly?
If you're running a service, fast means: how many total tokens did the GPU produce across all my users this hour?
These pull against each other. You can give one user a really fast response by giving them the whole GPU. Or you can serve multiple users at once by making each of them wait a tiny bit longer. You can't do both at the same time on the same hardware.
Most people benchmark the first kind and ship the second kind. That's where "we tested it and it was fast, why is production slow?" comes from.
Today I learned that "fast inference" isn't one number, it's three. And I'd only been thinking about one.
Tokens per second is the obvious one. How quickly the model writes. That's what benchmarks usually report.
Time-to-first-token is the one I didn't know mattered. It's how long you wait before the first word shows up. Even if a model writes fast once it gets going, a long pause at the start makes everything feel slow. Streaming that starts in 200ms feels faster than streaming that starts in 2 seconds, even if the fast starter is slower per token overall.
Then there's throughput vs latency. One user wants their own answer fast. A service running for 30 users wants the total output across everyone to be high. You can optimize for one, but not both.
When someone says "we have fast inference," ask which one they mean.