1/ What if we treated LLM prompt engineering not as vibes, but as rigorous, validation-gated gradient descent?
By formalizing natural language skills as trainable parameter states, we can systematically optimize LLM agents with zero inference-time overhead. 🧵
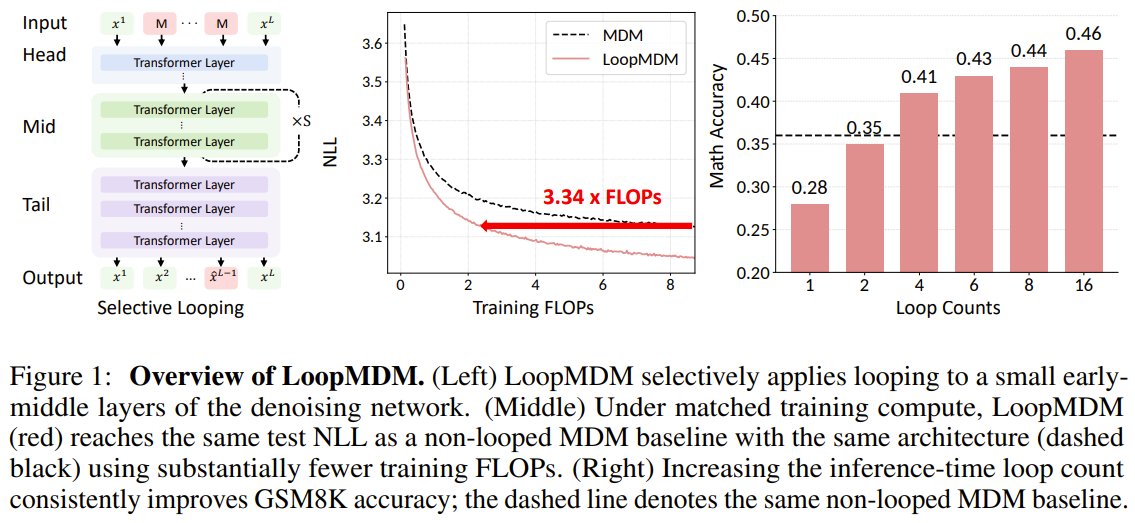
What if you could make AI language models smarter by reusing the same layers over and over?
Researchers from KAIST, KRAFTON, and UC Berkeley present LoopMDM(Looped Diffusion Language Models).
They selectively loop early-middle transformer layers in masked diffusion models—no extra parameters, just smart recycling of computation.
The result? LoopMDM matches standard models with 3.3x less training compute, then beats them on reasoning benchmarks like GSM8K by up to +8.5 points. It even outperforms deeper models trained with equal compute, and can scale performance at inference by looping more. Simplicity that punches above its weight.
I trust myself enough to keep going, even when I don’t see the result yet. Even when progress feels invisible, even when doubt is louder than hope. I may not be where I want to be, but im closer than I was yesterday.
And that’s enough for me to continue.
Some of us grew up w/ critics, not coaches. So yah, valid to feel happy for them and grieve what we never got. Both can coexist. No guilt. No comparison.