Every time a frontier model crosses a new capability threshold, demand for frontier tokens jumps.
"Dynamic workflows" is Anthropic giving Claude the ability to write code that orchestrates dozens of other frontier Claudes in parallel, i.e. Agent Swarms
The labs are already pricing in a compute crunch
- Google just 3×'d Gemini Flash pricing
- OpenAI just doubled GPT-5 pricing
- Anthropic's impending Mythos class model release expected @ 5x the price of Opus
The marginal frontier token will be an increasingly scarce resource.
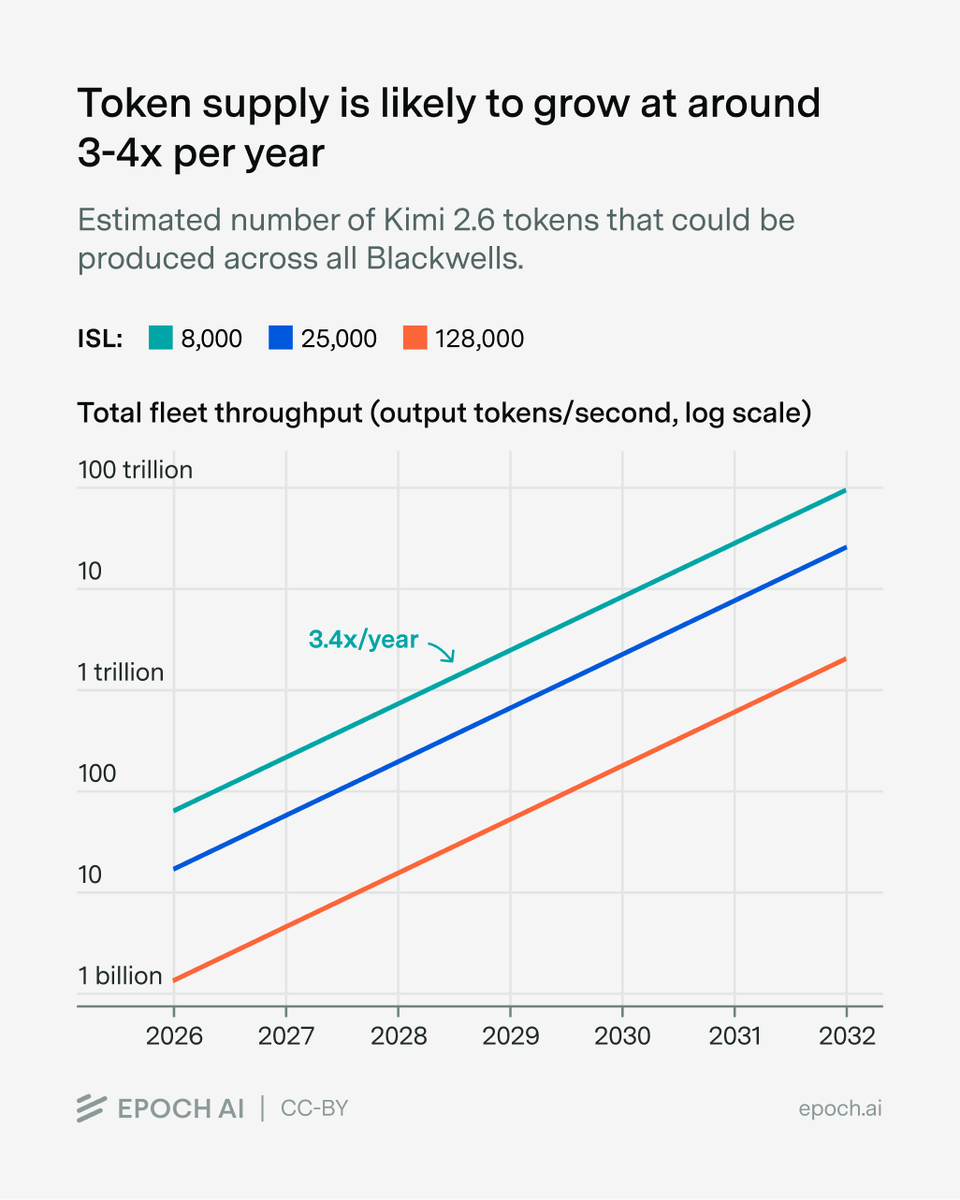
Are we nearing a compute crunch?
In our latest Gradient Update, @luke__emberson and @Jsevillamol estimate how many tokens all the Blackwell chips on Earth could serve, and compare this to total token demand. Direct comparisons are difficult, but it appears demand is growing much faster than supply.
This leans much more into harness engineering than token masking I think.
I tend to think of the LLMs stream of tokens (tool call => tool result => tool call => repeat) as the agent’s effective Markov state.
This is why context engineering matters: you are literally engineering the state representation the model acts from. The harness controls which observations enter that stream, in what information density, etc.
For agentic coding, the harness-as-state-representation matters quite a bit. So for example, in the recent Claude Code leak, Anthropic had some internal type checks, etc. that ran after every edit to provide the model with immediate feedback (for internal employees only).
If you train on these observations (only), the model should learn a (world) model of the consequences of it's own edits (I think): which tests break, which type constraints fail, which structural checks fail.
So the bitter lesson compatible move is not to hand-code a selective masking policy, but might be to build an environment with cheap, reliable, high-bandwidth feedback channels, let the agent query them & train it to predict the consequences!
Let me know what you think. What's the easiest way to test this out?
@DimitrisPapail Thanks ! That makes sense. Wondering whether a more general framing here is not "which terminal outputs should we predict" but “which feedback channels should the agent explicitly learn to query and model?”
New evidence that a well-specified harness (such as a Terminal) can be dual-use training infrastructure.
It produces both a reward signal for policy optimization & a prediction signal for the agent's own internal model of the environment.
One obvious extension: coding agents trained not just on whether the tests pass at the end (sparse), but on predicting compiler output at every intermediate step.
@anandcpatelmdms@socialwithaayan Yeah actually not that difficult to do. Would you be interested in running locally with your local files & Claude Desktop? Or do you want fully local with Ollama (no external providers at all) ?
@anandcpatelmdms@socialwithaayan@anandcpatelmdms Fair concern - especially for sensitive medical or research data.
The hosted version has complete isolation via Supabase RLS (your data is completely separate).
But for anything truly sensitive, the best option is local (I can look into adding support).
Quick update 🔥
You legends just pushed 25,000 pages through https://t.co/92fjgQnSA7 in the past few hours.
So I swapped the PDF backend to the excellent (and way cheaper) PDF Oxide
Good news: this means I can bump everyone's limits to 5000 pages and 5GB of storage.
Keep building those wikis. More coming soon.
It’s live and free to use right now at https://t.co/v2w0Qu1MR2
Fully open source → clone it, self-host it, fork it, improve it.
Github link at https://t.co/6mZ1EubGWr
Enjoy ! Ping me with questions.
I just open-sourced a full implementation of Karpathy's "LLM Wiki" over the weekend.
It's not a toy - or a half baked RAG rapper.
This is a real, production-grade tool where Claude directly builds and maintains your personal wiki for you
It compounds. It stays up to date. And it’s ridiculously easy to use.
https://t.co/92fjgQnSA7 with full source on GitHub
This is built more or less exactly against Karpathy’s original LLM Wiki spec
I took his high-level pattern and turned it into a real product you can use today.
No more “I wish my LLM would just maintain my knowledge base for me.”
It now exists