SOC Analyst at Kaspersky | Personal Account | ChessPlayer | Bookworm | وَقُل رَّبِّ زِدْنِي عِلْمًا | Fellow at @QimamFellowship '22 | in love with malware ♥️
خلال الأيام الماضية انتشرت ورقة بحثية/تجريبية من Pine AI في مجتمع الذكاء الاصطناعي لأنها طرحت محاولة غير تقليدية لتقدير حجم النماذج المغلقة من زاوية مختلفة:
هل يمكن تقدير حجم النماذج المغلقة مثل GPT و Claude و Gemini من خلال قياس كمية الحقائق النادرة التي يعرفها النموذج؟
الورقة بعنوان
Incompressible Knowledge Probes: Estimating Black-Box LLM Parameter Counts via Factual Capacity
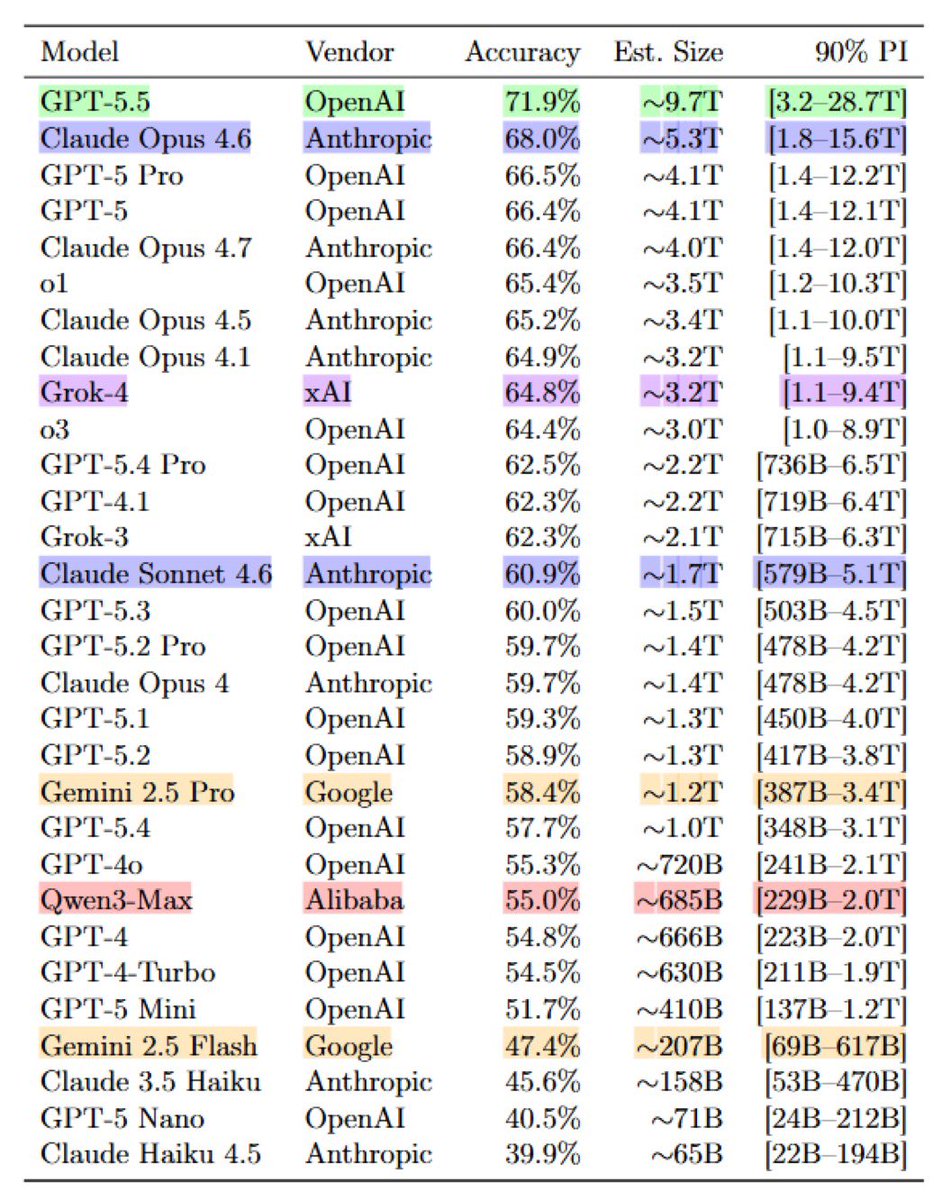
الفكرة كانت مختلفة عن الطرق المعتادة. بدل محاولة تخمين حجم النموذج من سرعة الاستجابة أو تكلفة التشغيل، طورت الورقة مجموعة أسئلة اسمها IKP تحتوي على 1400 سؤال ��ي 7 مستويات من السهولة إلى الندرة الشديدة.
المنطق بسيط: بعض الحقائق لا يمكن استنتاجها بالمنطق. إما أن النموذج شاهدها وتعلمها أثناء التدريب، أو لا يعرفها.
بعد ذلك، اختبر الباحث نماذج مفتوحة المصدر معروفة الحجم، ثم استخدم علاقة إحصائية بين أداء النموذج على هذه الأسئلة وحجمه المعروف.
النتيجة كانت علاقة قوية نسبيًا، حيث وصل R² إلى 0.917 على 89 نموذجًا مفتوحًا. وبشكل مبسّط، هذا يعني أن حجم النموذج كان يفسّر جزءًا كبيرًا من اختلاف أداء النماذج على أسئلة الحقائق النادرة.
وفي نماذج Mixture-of-Experts، وجد أن عدد المعاملات الكلي يفسّر المعرفة المخزنة أفضل من عدد المعاملات النشطة، مع R² حوالي 0.79 للمعاملات الكلية مقابل 0.51 للنشطة.
ومن هنا حاولت الورقة تقدير أحجام النماذج المغلقة، وكانت النتيجة التي أثارت النقاش أن GPT-5.5 قُدّر بحوالي 9.7T معامل، و Claude Opus 4.7 بحوالي 4T معامل.
لكن هذه الأرقام ليست رسمية، ولا تعني بالضرورة أنها الحجم الحقيقي للنماذج. الأدق أن الورقة تحاول قياس “السعة المعرفية الفعلية” للنموذج من خلال تذكّر الحقائق النادرة، ثم تحويل هذا القياس إلى تقدير تقريبي للحجم.
بعد انتشار الورقة ظهرت مراجعة مهمة للعمل وجدت مشكلتين أثّرتا بشكل واضح على هذه التقديرات.
لذلك من الأفضل قراءة الورقة كفكرة مختلفة لقياس “السعة المعرفية” للنماذج المغلقة، لا كإثبات نهائي لعدد معاملاتها الحقيقي.
الورقة طويلة وتتجاوز 70 صفحة، وفيها تفاصيل كثيرة وتحليلات إحصائية أعمق من هذا الملخص. هنا حاولت تبسيط الفكرة الأساسية، لكن أنصح بالاطلاع عليها مباشرة لمن أراد فهم المنهجية والنتائج بشكل أوسع.
⬇️ في التغريدة التالية: أبرز الملاحظات التي ظهرت بعد انتشار الورقة، وكيف غيّرت بعض التقديرات.
رابط الورقة:
https://t.co/EUtyuymCF0
أطلقت Anthropic أداة Claude Code Security، وهي أداة ذكاء اصطناعي تقرأ الكود وتحلّله مثل فكرة Code review، فتكتشف ثغرات زي التحكم بالصلاحيات والبفر اوفر فلو الي كثير تفوّتها الأدوات التقليدية وايضا الباحثين عن الثغرات.
العجيب انه باستخدام Opus 4.6 (يعتبر مو اخر اصداراتهم بعده Opus 4.7)، اكتشف فريقهم أكثر من 500 ثغرة في مشاريع مفتوحة المصدر ظلّت مخفية لسنوات.
للأمانه باقي ما جربته ولكن متحمس للأفكار الي ممكن تطبق بيه.
المصدر:
https://t.co/32aSVCQTgI
Claude Security is now in public beta for Claude Enterprise customers.
Claude scans your codebase for vulnerabilities, validates each finding to cut false positives, and suggests patches you can review and approve.
لما يصير اختراق لسيرفر أو شبكة، عندنا “Playbook” واضح: نرجع للـ logs، نفحص الـ endpoints، نتتبع بعض الادلة… لكن لما يصير الاختراق على نظام ذكاء اصطناعي، كثير من فرق السايبر ��وقفون مكانهم ويسألون: من وين نبدأ أصلاً؟
المشكلة أن الـ AI مو تطبيق عادي فيه input وoutput واضحين، هو منظومة متشعبة فيها طبقات، وكل طبقة لها سطح هجوم مستقل.
اول شيء بوضح انه هنا انا اتكلم اكثر عن تطبيقات AI، لانه موضوع الكلاود مثل حادثة Vercel وLovable لها طريقة تحقيق مختلف.
المهم خليني اكلمك عن الطبقات اللي المفروض يبدأ عندها أي تحقيق في حادثة اختراق AI، مرتبة من الأقرب للمستخدم للأعمق:
1. طبقة المدخلات (Prompt Layer)
أول مكان تبحث فيه هو سجلات الـ prompts. هل فيه Prompt Injection مباشر؟ أو الأخطر، Indirect Injection جاء من ملف PDF أو صفحة ويب أو إيميل النموذج قراه؟ كثير من الاختراقات اليوم تبدأ بنص مخفي داخل مستند يبدو بريء.
2. طبقة الـ System Prompt والـ Guardrails
افحص هل تم تسريب الـ system prompt (وهذا يحصل أكثر مما تتوقع)؟ هل فيه محاولات Jailbreak ناجحة في السجلات؟ الـ Guardrails تم تجاوزها بصياغة معينة؟
3. طبقة الـ RAG وقواعد البيانات المتجهة (Vector DBs)
إذا النظام يعتمد على RAG، فقاعدة البيانات المتجهة هي “ذاكرة” النموذج. تسميم البيانات هنا (Data Poisoning) يخلي النموذج يرد بمعلومات مزيفة أو ينفذ تعليمات خبي��ة بدون ما أحد يحس. راجع مصادر الـ ingestion: من له صلاحية يضيف مستندات؟
4. طبقة الأدوات والإضافات (Tools/MCP Layer)
هنا بالذات الخطر الأكبر اليوم. الـ AI Agent لما يكون متصل بـ MCP servers أو Plugins، كل أداة هي “باب” جديد. افحص:
•وش الأدوات اللي استُدعيت وقت الحادثة؟
•فيه استدعاءات خارج النمط الطبيعي؟
•الصلاحيات الممنوحة لكل أداة (مبدأ Least Privilege مطبق؟)
5. طبقة المفاتيح والهويات (API Keys & Identity)
الـ AI Agents غالباً تشتغل بـ service accounts صلاحياتها واسعة. افحص:
•هل فيه مفاتيح API مسربة في GitHub أو في logs؟
•Tokens الـ OAuth المربوطة بالوكيل تم استخدامها بشكل غير طبيعي؟
•من عنده صلاحية fine-tune أو deploy للنموذج؟
6. طبقة المخرجات (Output Layer)
آخر شي وأهم شي: وش طلع من النموذج؟ راجع هل فيه تسريب PII في الردود؟ أوامر نُفذت على أنظمة خارجية بناء على مخرجات النموذج؟ كود خبيث تم توليده ونُفذ مباشرة؟
7. طبقة المراقبة (Observability)
وهنا نكتشف أن أغلب المؤسسات عندها فجوة ضخمة�� ما عندهم baseline لسلوك النموذج الطبيعي. بدون baseline، ما تقدر تكتشف الشذوذ. لازم يكون عندك logging لكل tool call، كل prompt، كل retrieval.
الخلاصة: الـ AI ما يُخترق “كنموذج”، يُخترق كمنظومة. والمهاجم ما يحتاج يكسر النموذج نفسه، يكفيه يلعب على طرف واحد من هذي الأطراف السبعة.
قاعدة ذهبية في الـ DFIR للـ AI: “ابدأ من الأداة اللي استُدعيت آخر شي، وارجع للخلف”. غالباً سلسلة الاختراق تبان من هناك.
وأخيرا سؤالي لك: لو صار اختراق لـ AI Agent في جهتك اليوم، عندك الـ logs الكافية اللي تخليك تسوي تحقيق جنائي رقمي صحيح؟ أو لا؟
وسلامتكم!
لما يصير اختراق لسيرفر أو شبكة، عندنا “Playbook” واضح: نرجع للـ logs، نفحص الـ endpoints، نت��بع بعض الادلة… لكن لما يصير الاختراق على نظام ذكاء اصطناعي، كثير من فرق السايبر يوقفون مكانهم ويسألون: من وين نبدأ أصلاً؟
المشكلة أن الـ AI مو تطبيق عادي فيه input وoutput واضحين، هو منظومة متشعبة فيها طبقات، وكل طبقة لها سطح هجوم مستقل.
اول شيء بوضح انه هنا انا اتكلم اكثر عن تطبيقات AI، لانه موضوع الكلاود مثل حادثة Vercel وLovable لها طريقة تحقيق مختلف.
المهم خليني اكلمك عن الطبقات اللي المفروض يبدأ عندها أي تحقيق في حادثة اختراق AI، مرتبة من الأقرب للمستخدم للأعمق:
1. طبقة المدخلات (Prompt Layer)
أول مكان تبحث فيه هو سجلات الـ prompts. هل فيه Prompt Injection مباشر؟ أو الأخطر، Indirect Injection جاء من ملف PDF أو صفحة ويب أو إيميل النموذج قراه؟ كثير من الاختراقات اليوم تبدأ بنص مخفي داخل مستند يبدو بريء.
2. طبقة الـ System Prompt والـ Guardrails
افحص هل تم تسريب الـ system prompt (وهذا يحصل أكثر مما تتوقع)؟ هل فيه محاولات Jailbreak ناجحة في السجلات؟ الـ Guardrails تم تجاوزها بصياغة معينة؟
3. طبقة الـ RAG وقواعد البيانات المتجهة (Vector DBs)
إذا النظام يعتمد على RAG، فقاعدة البيانات المتجهة هي “ذاكرة” النموذج. تسميم البيانات هنا (Data Poisoning) يخلي النموذج يرد بمعلومات مزيفة أو ينفذ تعليمات خبيثة بدون ما أحد يحس. راجع مصادر الـ ingestion: من له صلاحية يضيف مستندات؟
4. طبقة الأدوات والإضافات (Tools/MCP Layer)
هنا بالذات الخطر الأكبر اليوم. الـ AI Agent لما يكون متصل بـ MCP servers أو Plugins، كل أداة هي “باب” جديد. افحص:
•وش الأدوات اللي استُدعيت وقت الحادثة؟
•فيه استدعاءات خارج النمط الطبيعي؟
•الصلاحيات الممنوحة لكل أداة (مبدأ Least Privilege مطبق؟)
5. طبقة المفاتيح والهويات (API Keys & Identity)
الـ AI Agents غالباً تشتغل بـ service accounts صلاحياتها واسعة. افحص:
•هل فيه مفاتيح API مسربة في GitHub أو في logs؟
•Tokens الـ OAuth المربوطة بالوكيل تم استخدامها بشكل غير طبيعي؟
•من عنده صلاحية fine-tune أو deploy للنموذج؟
6. طبقة المخرجات (Output Layer)
آخر شي وأهم شي: وش طلع من النموذج؟ راجع هل فيه تسريب PII في الردود؟ أوامر نُفذت على أنظمة خارجية بناء على مخرجات النموذج؟ كود خبيث تم توليده ونُفذ مباشرة؟
7. طبقة المراقبة (Observability)
وهنا نكتشف أن أغلب المؤسسات عندها فجوة ضخمة؛ ما عندهم baseline لسلوك النموذج الطبيعي. بدون baseline، ما تقدر تكتشف الشذوذ. لازم يكون عندك logging لكل tool call، كل prompt، كل retrieval.
الخلاصة: الـ AI ما يُخترق “كنموذج”، يُخترق كمنظومة. والمهاجم ما يحتاج يكسر النموذج نفسه، يكفيه يلعب على طرف واحد من هذي الأطراف السبعة.
قاعدة ذهبية في الـ DFIR للـ AI: “ابدأ من الأداة اللي استُدعيت آخر شي، وارجع للخلف”. غالباً سلسلة الاختراق تبان من هناك.
وأخيرا سؤالي لك: لو صار اختراق لـ AI Agent في جهتك اليوم، عندك الـ logs الكافية اللي تخليك تسوي تحقيق جنائي رقمي صحيح؟ أو لا؟
وسلامتكم!
في الأمن السيبراني، تعودنا أن الهجمات تجي من ثغرة في نظام أو إيميل احتيالي، لكن اليوم صار فيه "ناقل هجوم" جديد ومخفي: أدوات الذكاء الاصطناعي على جهازك.
كيف هذا ممكن يصير؟
في عالم السايبر، القاعدة دائماً تقول: "الثقة هي عدو الأمان"، وهذا ينطبق على مساعدك الذكي أكثر من أي وقت مضى. تذكر دائماً أن أي أداة تزيد إنتاجيتك بشكل سحري، غالباً لها ثمن أمني لازم تدفعه إذا ما كنت حذر.