Licenciado en Ciencias Físicas. Carrera profesional dedicada Gestión del Contenido / Conocimiento, no siempre coinciden. Fanático basket y juegos de estrategia.
19 de junio de 1987. El Comando Barcelona de la banda terrorista ETA introduce un coche bomba cargado con 30 kg de amonal, cien litros de gasolina, escamas de jabón y pegamento hasta sumar 200 kg de carga explosiva, en el aparcamiento del hipermercado Hipercor de Barcelona. A las 16:10 horas actuó el temporizador que activaba los explosivos, ocasionando una enorme explosión que voló por los aires la primera planta del garaje, y provocando un socavón de 5 metros de diámetro en el suelo del establecimiento por el que penetró una bola de fuego que abrasó a todas las personas que encontró a su paso. Fueron asesinadas 21 personas y resultaron heridas otras 45.
He decidido dejar el As.
No hace falta que especuleis con el mótivo, ya os lo digo yo: la pasta. Me ofrecieron un dinero para continuar, pedí otra cantidad, me hicieron una contraoferta no satisfactoria y hasta aquí.
Mil gracias a jefes y compañeros por cinco años inolvidables
A freelance journalist who had never taken a statistics course wrote a 142-page book in 1954 that professional statisticians still hand to students before anything else, because nobody before him had bothered to explain the tricks in plain language.
His name was Darrell Huff. The book is called How to Lie with Statistics.
I read it in one sitting and spent the next three days noticing the tricks everywhere.
Over 1.5 million copies have sold in English alone. It became a standard college textbook in the 1960s and 70s. Seventy years later it is still in print, still assigned, still the first thing a working statistician reaches for when they want to teach someone to think clearly about numbers.
The man who wrote it was not a researcher. He was a freelancer who wrote how-to articles for magazines. He had no PhD, no academic post, no institutional affiliation. He just understood that numbers could lie without technically being wrong, and he thought someone should explain how.
His opening line sets the whole tone of the book.
"The crooks already know these tricks; honest men must learn them in self-defense."
That one sentence is the entire argument. The manipulation is not coming. It already happened. It happened this morning in the article you read and the chart someone showed you at work and the study your doctor quoted. The only question is whether you know what to look for.
Huff called the first trick the Well-Chosen Average.
When someone tells you the average salary at a company is $80,000, they have told you almost nothing. If the CEO earns $2 million and the 20 employees earn $30,000 each, the mean is $80,000. The median is $30,000. Both are technically correct. One is a lie. The person reporting the number chose which average to use, and they almost always chose the one that served their argument. Huff's rule: whenever you see an average with no description of which average it is, ask.
The second trick he named the Gee-Whiz Graph.
A line chart shows company profits rising. The line shoots nearly vertical, almost doubling in height across the chart. You feel impressed. Then you look at the y-axis and notice the chart does not start at zero. It starts at 94. The actual increase in profits was 3 percent. The dramatic visual was produced entirely by cropping the bottom of the chart. Nothing in the data changed. The picture changed everything.
Every news organization on earth still does this every day.
The third trick is the one that should change how you read every study you ever encounter. Huff called it Post Hoc Rides Again, which is short for the Latin phrase post hoc ergo propter hoc. After this, therefore because of this.
Cities with more churches have more violent crime. Therefore churches cause violence. The logic is airtight. The conclusion is absurd. Both church attendance and crime go up as population grows. The two numbers track each other because a third variable drives both. The correlation is real. The cause is invented.
Huff showed that this structure is not a rare mistake. It is the default pattern of almost every study reported in a newspaper, because causation is a boring word and because proves is a better headline than correlates with.
The fourth trick was the one that floored me. He called it the Semi-Attached Figure.
A headache pill company claims their product is twice as fast as the competition. The study behind the claim is real. The product was tested and the numbers are accurate. What the advertisement does not mention is that the study measured absorption rate into the bloodstream, not relief of headaches. The two things are related but not identical. The statistic is real. It is attached to the wrong conclusion.
Huff said this is the most dangerous trick of all because the number is never fabricated. You cannot fact-check a semi-attached figure by verifying the statistic. You have to ask whether the statistic actually measures what the claim requires it to measure.
Almost nobody asks.
There is one part of Huff's story that most people who recommend the book leave out.
Years after he wrote it, he was hired by the tobacco industry. He worked on a follow-up manuscript called How to Lie with Smoking Statistics, designed to cast doubt on the research connecting cigarettes to cancer. The book was never published. He testified before Congress in an attempt to undermine the statistical evidence against tobacco.
The man who wrote the clearest guide to spotting statistical deception spent the end of his career deploying those same tricks against evidence that was killing people.
That detail does not make the book wrong. The tricks he described are real and the defenses he taught are still the right ones. But it is a reminder that the tools in the book are neutral. Understanding how lies are built does not protect you from choosing to build one.
The crooks already know these tricks.
Some of them wrote the manual.
What is one statistic you have seen recently that you now think deserves a second look?
Nobody talks about the lonely part.
“People always talk about talent, but what they don’t wanna talk about is loneliness. The empty gym…”
- Larry Bird
Confidence.
Nobody gives it to you.
You build it rep by rep.
In the gym when no one’s watching. https://t.co/4zIilqfX40
#Taldíacomohoy, un 23 de mayo de 1951, nace en Zlatoúst (URSS) 𝗔𝗻𝗮𝘁𝗼𝗹𝘆 𝗞𝗮𝗿𝗽𝗼𝘃
🎂El gélido Tolia sopla hoy 75 velas y deseamos que se encuentre en buen estado de salud y jugando al #ajedrez como siempre hizo
📲Vuelve a ver el #VintageKarpov👉https://t.co/Riy3jyAkGE
Hace unas semanas me topé con una de esas pruebas que parecen una anécdota tonta y resultan ser bastante reveladoras. La tenía apuntada para escribir sobre ello, y hoy me he sentado a hacerlo.
Se llama "Car Wash Test"
La pregunta es esta:
"Quiero lavar mi coche. El lavadero está a 50 metros. ¿Voy andando o conduciendo?"
Hazle esto a casi cualquier LLM y te dice que vayas andando.
ChatGPT te lo dice. Gemini te lo dice (algunos). Llama y Mistral te lo dicen siempre. Y la mayoría de las veces, también lo hace Claude.
La respuesta correcta, claro, es ir conduciendo. Por una razón muy simple: el coche tiene que estar en el lavadero para poder lavarlo, no ?
Cualquier humano lo pilla en un segundo. Bueno, casi cualquiera (luego volvemos a esto).
El estudio que ha cuantificado todo esto es de Opper, y los datos son bastante demoledores. Probaron 53 modelos sin system prompt, una sola pregunta, dos botones (conducir o andar).
A la primera, solo 11 de 53 lo aciertan. Los otros 42 te mandan andando.
Pero lo interesante viene cuando repiten cada test 10 veces para ver si la respuesta es estable. Solo 5 modelos aciertan 10 de 10. Otros 15 a veces sí y a veces no. Y 33 modelos no lo aciertan ni una sola vez. Entre esos 33 están todos los Llama, todos los Mistral, GPT-4o, GPT-4.1, GPT-5.1, GPT-5.2 y casi todos los Claude (excepto Opus 4.6).
Para que veas la magnitud: hicieron también la pregunta a 10.000 humanos en una plataforma de feedback, mismo formato, dos botones. El 71,5% contestó "conducir". Es decir, 48 de los 53 modelos rinden peor que un humano medio que decide en un segundo sin pensar.
Esto solo ya da que pensar.
Vamos por partes, que esto tiene miga.
Los LLMs son, en el fondo, máquinas de predecir el siguiente token. Cuando ven "50 metros", se les dispara una heurística de distancia: corto, mejor andando. Y a partir de ahí construyen toda la respuesta sobre esa señal: ahorras combustible, haces ejercicio, contaminas menos, no arrancas el motor en frío, no hay que buscar aparcamiento.
Razonamiento impecable... sobre el problema equivocado.
Lo más jugoso del estudio son los ejemplos de modelos que casi lo pillan y aún así se equivocan.
Claude Opus 4.5 (no el actual) llegó a recomendar literalmente "ve andando al lavadero y luego conduce el coche por el túnel". El coche, que recordamos está en casa, supongo que iba a teletransportarse solo.
Sonar de Perplexity dio en una de sus versiones la respuesta correcta... pero por motivos delirantes. Citaba estudios de la EPA y argumentaba que andar quema calorías que requieren producir comida que contamina más que conducir 50 metros. Respuesta correcta, razonamiento de manicomio.
Claude Sonnet 4.5 escribió literalmente "la única excepción sería si necesitas conducir el coche al lavadero para un lavado automático". Vio la respuesta. La articuló. Y aun así eligió "andando".
Eso último (vio la respuesta y la rechazó) es lo que más me llamó la atención.
Hasta aquí, lo previsible: pantallazos virales, "la IA es tonta", a otra cosa.
Pero a mí me interesaba más saber si esto es de verdad un problema del modelo o un problema de prompt.
Lo probé con Claude Opus 4.7, el modelo más avanzado disponible hoy y el que utilizo a diario para construir prácticamente todo lo que monto. Le hice la pregunta tal cual.
Me dijo que andando.
Y mira qué casualidad, el mismo patrón que Sonnet 4.5 en el estudio: terminaba añadiendo "la única excepción sería que sea un túnel de lavado donde tienes que entrar conduciendo, claro". O sea, casi lo pilla. Pero la respuesta principal seguía siendo "andando".
Probé también con K2 (el último modelo grande de Moonshot) y la respuesta fue peor. "Te recomiendo ir andando", sin matices, y de propina te dice que así puedes "supervisar el lavado sin preocuparte por dejar el coche mal estacionado". Supervisar el lavado de un coche que no está en el lavadero. Joder.
Entonces hice el experimento que de verdad me importaba. Volví a Claude. Misma pregunta. Pero le añadí una línea al principio del prompt:
"Antes de responder, identifica el objetivo de mi petición y los prerrequisitos físicos que deben cumplirse."
Mismo modelo. Misma pregunta. Acertó a la primera, sin titubear.
Y aquí está la parte que creo que merece la pena retener.
El "fix" no fue darle más información. Fue obligarle a articular el objetivo antes de generar la conclusión. En cuanto el prompt forzó al modelo a explicitar lo que estaba intentando hacer, la restricción implícita (el coche tiene que estar en el lavadero) apareció como texto explícito. Y a partir de ahí, el razonamiento se condicionó correctamente.
El cuello de botella no era el conocimiento. Era la secuencia de pensamiento.
Y aquí volvemos a los tres tipos de modelo que el estudio diferencia, porque me parece la lectura más útil para cualquiera que esté construyendo con IA.
Están los que no aciertan nunca: tienen tan grabada la heurística "distancia corta igual a andar" que no consiguen sobreescribirla con razonamiento contextual. La capacidad simplemente no está accesible.
Los que aciertan a veces: la capacidad existe, pero compite con la heurística, y en cada llamada gana una u otra.
Y los que aciertan siempre: el razonamiento contextual gana sin discusión.
La categoría intermedia es la peligrosa. La más peligrosa con diferencia. El modelo pasa tu evaluación, te emocionas, lo metes en producción y entonces empieza a fallar de forma impredecible. Si una pregunta de un único paso lógico ya descoloca al modelo a veces, imagina lo que pasa con cadenas de razonamiento reales, casos límite y lógica de negocio ambigua.
Por eso estoy convencido de que la próxima frontera para los que estamos construyendo con IA no es buscar el modelo más potente. Es construir el contexto y la arquitectura de prompt que hace que el modelo razone bien siempre, no solo a veces.
Un prompt no es el primer paso. Es el último. El primero es el framework de pensamiento.
Los que están sacando consistentemente más partido de la IA no escriben prompts más largos. Construyen arquitecturas que obligan al modelo a identificar objetivos, sacar a la luz restricciones implícitas y secuenciar el razonamiento antes de generar una sola palabra de salida.
Me da que esa va a ser la línea que separe cada vez más a los que avanzan de los que se quedan estancados culpando a la herramienta.
Esa es la diferencia entre usar la IA y dominarla ;)
(El estudio completo aquí, vale mucho la pena leerlo entero: https://t.co/cUmrxbEaLJ)
Uzbekistán 🇺🇿 se ha consolidado como una de las grandes potencias mundiales del ajedrez. Este fenómeno responde a una estricta política estatal que introdujo el ajedrez en el currículo de las escuelas públicas y promovió la creación de centros de alto rendimiento en todo el país. El ajedrez forma parte del plan de estudios oficial en las escuelas primarias y secundarias y se utiliza como una herramienta pedagógica para potenciar el pensamiento lógico y la concentración. Todo financiado por el gobierno.
¿Crees que sería positivo que el ajedrez fuera una asignatura escolar obligatoria?
Adiós al cobre: Finlandia ya envía energía por el aire. #Matelec2026
¿Y si los cables eléctricos fueran historia?
La empresa Emrod ya está enviando energía a kilómetros sin cables, usando microondas y seguridad por láser.
Esto va a cambiar por completo cómo diseñamos nuestras ciudades y el coste de la red eléctrica.
¿Te imaginas un mundo sin cables colgando por todas partes?
La montaña de mierda que nos ha regalado la NBA esta noche es consecuencia de lustros de constante trabajo hacia la superficialidad. La mejor liga del mundo.
https://t.co/YwXjudeGKm
LAS BICICLETAS ME ESTÁN QUITANDO EL PAN (O NO)
Ayer leí que un ciclista es un desastre para la economía.
No compra coches. No paga seguros. No necesita gasolineras. No usa aparcamientos de pago. No engorda. No va al cardiólogo. No compra estatinas.
Vamos, que un ciclista, no aporta nada al PIB.
Aunque yo me reí.
Porque el ciclista es uno de los mejores clientes que tiene un traumatólogo.
Clavículas, muñecas, caderas...
¿Sabes cuánto cuesta una placa de clavícula? Más que la bicicleta.
Pero tengo que reconocer una cosa: cada vez da menos negocio. La gente la está dejando.
Por suerte, nos ha llegado la salvación.
El patinete eléctrico.
Ese aparato glorioso que combina la inestabilidad de un monopatín, la velocidad de una moto y la protección de tu cara en el asfalto.
El resultado es una colección de fracturas de codo que no habíamos visto en décadas. Hablando con los representantes, me comentan que estamos batiendo récords de implantes de prótesis de cabeza de radio.
Y lo mejor: ninguna ventaja cardiovascular.
El ciclista al menos compensaba. Se rompía la clavícula, pero tenía el corazón de un atleta.
El del patinete no.
Llega a urgencias con una fractura de radio y la tensión por las nubes. Negocio redondo.
Traumatología y cardiología en el mismo paciente.
Ese economista debería estar orgulloso del rumbo que está tomando nuestra sociedad. El patinete no solo genera fracturas. Genera placas, tornillos, rehabilitación, revisiones y segundas cirugías.
Eso sí es aportar al PIB.
Cada vez que veo a alguien subirse a un patinete eléctrico sin casco... siento estabilidad laboral.
#LaTraumatologaGeek
Después de muchos años Granada vuelve a tener un open internacional de ajedrez clásico, que valdrá para normas de MI y GM. Estoy tan feliz que voy a regalar 3 de mis cursos de ajedrez en vídeo a 3 de los que hagan retuit.
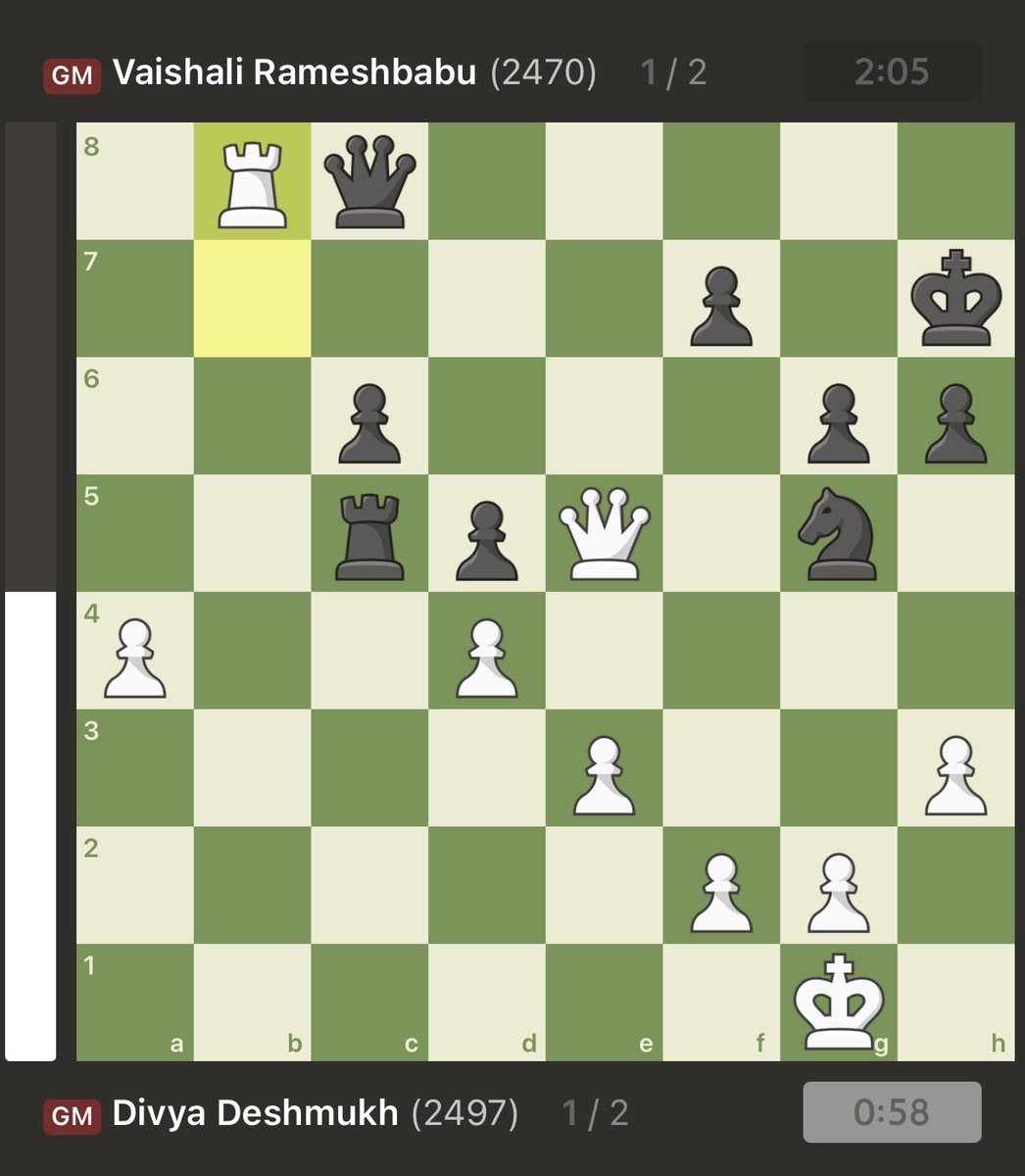
Incredible move alert!! Just when she looked dead in the water, Vaishali pulled off a miracle save against her countrywoman Divya Deshmukh. The Candidate tournaments in Cyprus have been dramatic and exciting so far!
🚨BREAKING: OpenAI published a paper proving that ChatGPT will always make things up.
Not sometimes. Not until the next update. Always. They proved it with math.
Even with perfect training data and unlimited computing power, AI models will still confidently tell you things that are completely false. This isn't a bug they're working on. It's baked into how these systems work at a fundamental level.
And their own numbers are brutal. OpenAI's o1 reasoning model hallucinates 16% of the time. Their newer o3 model? 33%. Their newest o4-mini? 48%. Nearly half of what their most recent model tells you could be fabricated. The "smarter" models are actually getting worse at telling the truth.
Here's why it can't be fixed. Language models work by predicting the next word based on probability. When they hit something uncertain, they don't pause. They don't flag it. They guess. And they guess with complete confidence, because that's exactly what they were trained to do.
The researchers looked at the 10 biggest AI benchmarks used to measure how good these models are. 9 out of 10 give the same score for saying "I don't know" as for giving a completely wrong answer: zero points. The entire testing system literally punishes honesty and rewards guessing.
So the AI learned the optimal strategy: always guess. Never admit uncertainty. Sound confident even when you're making it up.
OpenAI's proposed fix? Have ChatGPT say "I don't know" when it's unsure. Their own math shows this would mean roughly 30% of your questions get no answer. Imagine asking ChatGPT something three times out of ten and getting "I'm not confident enough to respond." Users would leave overnight. So the fix exists, but it would kill the product.
This isn't just OpenAI's problem. DeepMind and Tsinghua University independently reached the same conclusion. Three of the world's top AI labs, working separately, all agree: this is permanent.
Every time ChatGPT gives you an answer, ask yourself: is this real, or is it just a confident guess?