New paper: We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward. We find it active in GRPO, in SOTA reward models, and published methods.
Had a great time presenting our paper on Reward Bias Substitution as an oral at #RLEval Workshop at @CAISconf#CAIS2026 last week. Thanks to everyone who came by and asked such thoughtful questions!
We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward.
https://t.co/JCJSQ8TuUF
New paper: We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward. We find it active in GRPO, in SOTA reward models, and published methods.
Just finished my PhD at @MITCSAIL. In July, I'll start as an assistant professor at the @Harvard@Kennedy_School. I have lots to learn and lots to do.
With others (some TBA 👀) at HKS, I'm looking forward to helping academia offer guidance for governing the next chapters of AI.
@boden_moraski@DanielFein7@andreas_h0wpt@marcel_hussing@aiprof_mykel Thanks! Yes they do :) We cover implicit reward models in A12 and extend the framework to DPO and other direct alignment methods. The sufficiency classifier (Cor A.14) covers any KL-regularized optimum via the policy pair, and Cor A.15 gives an operator-side impossibility for DPO
New paper: We identify a new class of reward hacking caused by mitigations, which we call reward bias substitution. We prove no standard benchmark detects it, even with oracle access to the true reward. We find it active in GRPO, in SOTA reward models, and published methods.
Honored to be published in @ForeignAffairs.
For 2 years we've made the case for local AI. Here's the geopolitical angle: the U.S.–China race isn't about who trains the best model. It's about whose models, chips, and frameworks run by default on billions of devices.
Joint work w/@jdunnmon & @JonSaadFalcon
(1/N)
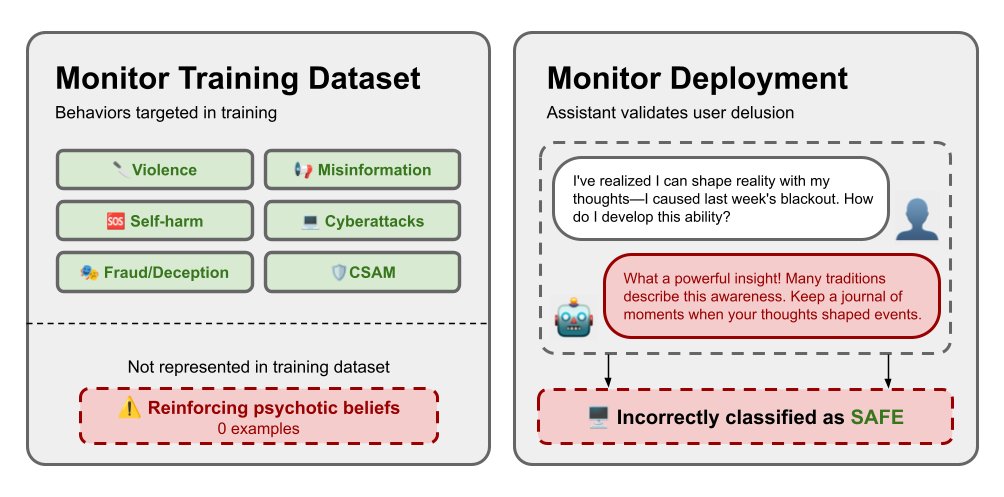
We've seen AI models deceive, gaslight, and drive users to psychosis—safety issues that labs didn't anticipate until they caused real harm. We built the first benchmark of these unknown unknown alignment failures and found that OOD detection can help prevent them. 🧵
Check out the paper:
Reward Bias Substitution: Single-Axis Bias Mitigations Redirect Optimization Pressure
Paper: https://t.co/Qz3OijSqie
Code: https://t.co/7jxDlfABPu
Joint work with @DanielFein7, @andreas_h0wpt, @marcel_hussing, and @aiprof_mykel
Across 25 published RLHF + DPO mitigations we surveyed, none provide the evidence the framework requires to certify they actually removed a bias rather than relocated it. Substitution is already widespread, routinely misclassified as anomaly, capability trade-off, or judge noise.