BREAKING:
Keir Starmer says he won’t remove the exemption which allows Sikhs to carry large ceremonial knives on them.
Meanwhile, English women are being prosecuted for carrying regular pepper spray on them when out on the streets at night
llama.cpp now has an official website: https://t.co/vztdUpdBWL
Our goal is to make local AI accessible to everyone, and improving the user experience is a big part of that. On the new landing page you’ll find a single-line cross-platform installer. The installation provides a single unified `llama` entrypoint which you can use to run/serve models and interface with 3rd-party agentic applications.
While oriented towards simplified user experience, the new `llama` application also provides all the advanced functionality of the existing llama.cpp tooling with which experienced users are already familiar. Also note that all GGUF models that you might have already downloaded with llama.cpp in the past will be automatically available to use without downloading again (they are stored in the common HF cache on your machine).
We have many improvements in the pipeline both at the UX and at the engine level and we plan to iteratively ship new things over the coming months. One of the main focuses will be seamless integration with local-friendly 3rd-party agents (such as Pi). In the meantime, we’ll continue to listen for feedback from the community and adjust accordingly, so keep letting us know what you think and need.
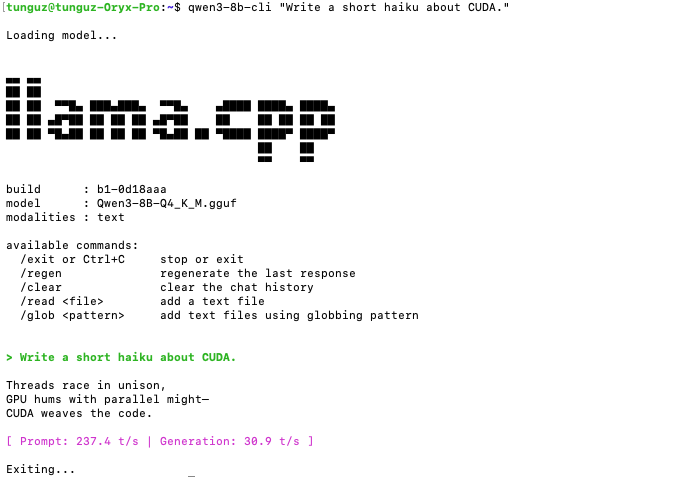
After seeing these tweets, I decided to try it out on my own old Ubuntu computer with RTX 1070 GPU (the one that I just upgraded from 16.04 all the way to 24.04 the other day). Asked Codex on my Mac to connect to that machine and install and test qwen3 8b. So far really impressive - running 30 tok/s!