Your RL post-training may be sabotaging your LLM’s test-time scaling!
Conventional RL pretends that you can collapse all reward signals *upfront* into a single *scalar reward*.
We introduce Vector Policy Optimization (VPO), which natively maximizes *vector-valued* rewards, boosting test time search performance, even on the original scalar.
@thsottiaux I regularly have codex cli starting the same compile job twice or more (record is 4!) because it got impatient with the progress. This happens evn after telling it to not do that in AGENTS.md…
Introducing 𝑨𝒕𝒕𝒆𝒏𝒕𝒊𝒐𝒏 𝑹𝒆𝒔𝒊𝒅𝒖𝒂𝒍𝒔: Rethinking depth-wise aggregation.
Residual connections have long relied on fixed, uniform accumulation. Inspired by the duality of time and depth, we introduce Attention Residuals, replacing standard depth-wise recurrence with learned, input-dependent attention over preceding layers.
🔹 Enables networks to selectively retrieve past representations, naturally mitigating dilution and hidden-state growth.
🔹 Introduces Block AttnRes, partitioning layers into compressed blocks to make cross-layer attention practical at scale.
🔹 Serves as an efficient drop-in replacement, demonstrating a 1.25x compute advantage with negligible (<2%) inference latency overhead.
🔹 Validated on the Kimi Linear architecture (48B total, 3B activated parameters), delivering consistent downstream performance gains.
🔗Full report:
https://t.co/u3EHICG05h
Latent world models learn differentiable dynamics in a learned representation space, which should make planning as simple as gradient descent.
But it almost never works.
What I mean is, at test time, you can treat the action sequence as learnable parameters, roll out the frozen world model, measure how far the predicted final state is from the goal, and backprop through the entire unrolled chain to optimize actions directly. Yet many of the systems that work (Dreamer, TD-MPC2, DINO-WM) abandon this and fall back to sampling-based search instead.
That's why I really like this new paper by @yingwww_, @ylecun, and @mengyer, which gives a clean diagnosis of why, and a principled fix.
The reason everyone abandons gradient descent on actions is that the planning objective is highly non-convex in the learned latent space. So instead most systems use CEM (cross-entropy method) or MPPI (model predictive path integral), both derivative-free.
CEM samples batches of action sequences, evaluates them by rolling out the world model, keeps the top-k, and refits the sampling distribution.
MPPI does something similar but weights trajectories by exponentiated negative cost instead of hard elite selection.
These work when gradients are unreliable but the compute cost is substantial — hundreds of candidate rollouts per planning step vs a single forward-backward pass.
This paper asks what exactly makes the latent planning landscape so hostile to gradients and what you can do about it.
The diagnosis. Their baseline is DINO-WM, a JEPA-style world model with a ViT predictor planning in frozen DINOv2 feature space, minimizing terminal MSE between predicted and goal embeddings. The problem is that DINOv2 latent trajectories are highly curved (when you use MSE as the planning cost you're implicitly assuming euclidean distance approximates geodesic distance along feasible transitions).
For curved trajectories this breaks badly, gradient-based planners get trapped and straight-line distances in embedding space misrepresent actual reachability.
The fix draws from the perceptual straightening hypothesis in neuroscience — the idea that biological visual systems transform complex video into internally straighter representations. So they add a curvature regularizer during world model training.
Given consecutive encoded states
z_t, z_{t+1}, z_{t+2},
define velocity vectors as
v_t = z_{t+1} - z_t
measure curvature as the cosine similarity between consecutive velocities, and minimize
L_curv = 1 - cos(v_t, v_{t+1}).
Total loss is then
L_pred + λ * L_curv
with stop-gradient on the target branch to prevent collapse.
The theory backs this up cleanly — they prove that reducing curvature directly bounds how well-conditioned the planning optimization is — straighter latent trajectories guarantee faster convergence of gradient descent over longer horizons.
Worth noting that even without the curvature loss, training the encoder with a prediction objective alone produces some "implicit straightening" — the JEPA loss naturally favors representations whose temporal evolution is predictable. Explicit regularization simply pushes this much further.
Empirical results across four 2D goal-reaching environments are consistently strong. Open-loop success improves by 20-50%, and the GD with straightening matches or beats CEM at a fraction of the compute.
The most convincing evidence is the distance heatmaps: after straightening, latent Euclidean distance closely matches the shortest distance between states, even though the model was trained only on suboptimal random trajectories.
What I find interesting beyond the specific method is that the planning algorithm didn't change. The dynamics model didn't change. A single regularization term on the embedding geometry turned gradient descent from unreliable to competitive with sampling methods.
The field has largely treated representation learning and planning as separate concerns — learn good features, then figure out how to plan in them.
This paper makes a concrete case that the representation geometry is itself the bottleneck.
This connects to a broader pattern in ML. When optimization fails, the instinct is to fix the optimizer (better search, more samples, adaptive schedules). But often the real lever is the shape of the space you're optimizing in.
Same principle shows up in RL post-training where reward landscape shaping matters as much as the algorithm itself.
Shape the space so simple optimization works, rather than building complex optimization to handle a bad space.
Their paper:
https://t.co/NLPGxqbP2x
OpenFold3-preview (OF3p) is out: a sneak peek of our AF3-based structure prediction model. Our aim for OF3 is full AF3-parity for every modality. We now believe we have a clear path towards this goal and are releasing OF3p to enable building in the OF3 ecosystem. More👇
1/4 LLMs solve research grade math problems but struggle with basic calculations. We bridge this gap by turning them to computers.
We built a computer INSIDE a transformer that can run programs for millions of steps in seconds solving even the hardest Sudokus with 100% accuracy
🚨Transformers don't learn Newton's laws? They learn Kepler's laws!
Like us, transformers don't predict a flying ball via a differential equation, but by fitting a curve.
Moreover, reducing context length steers a transformer from Keplerian to Newtonian. Compression in play.
Generative Modeling via Drifting
New Kaiming He paper! Instead of a "pushforward" behavior carried out iteratively at inference time, e.g., in diffusion/flow-based models, evolve the pushforward distribution during training naturally enabling 1-step inference. SOTA results on ImageNet 256×256, with FID 1.54 in latent space and 1.61 in pixel space
Imagine you could solve an infinite set of transport problems with one Meta Flow Map model that allows you to sample from arbitrary posterior distributions.
Now imagine you can do that to construct a really effective estimator of how to adapt a diffusion to solve an RL problem.
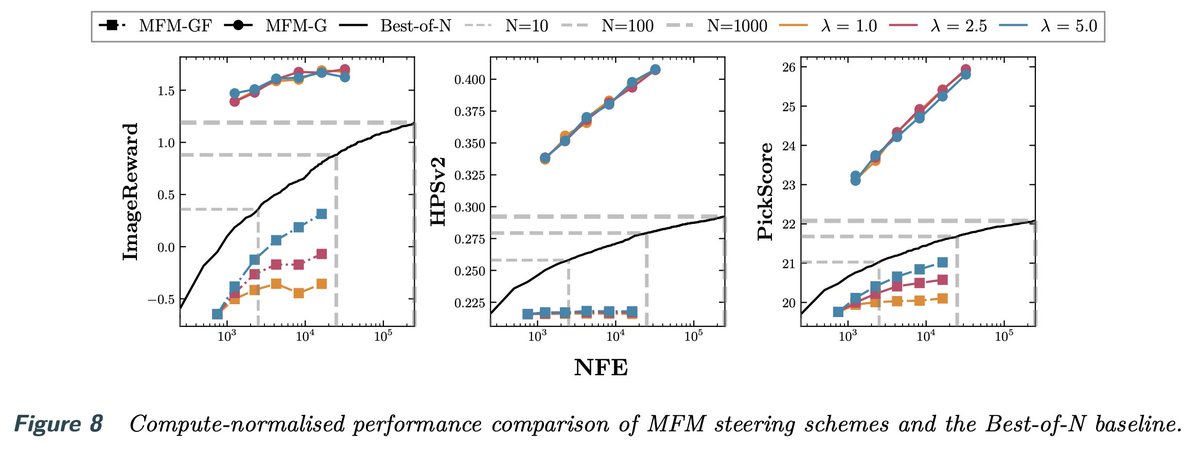
Now imagine that doing so allows you to even outperform Best-of-N=1000 at a fraction of the compute.
Excited to introduce a new paradigm for flow and diffusion models we call Meta Flow Maps, which make this possible 🙂
👾 Learnable with simple modification of existing flow map losses
👾Off-policy fine-tuning algorithm!
👾Extremely effective reward alignment across a variety of rewards for both inference-time steering and learned fine-tuning!
arxiv: https://t.co/lgxLlis24O
project page: https://t.co/hOcxS1h5e6
code: forthcoming
Amazing work by @PPotaptchik and @adhisarav to bring these results to life! Really excited about future directions here! Thanks to @yeewhye@AbbasMammadov11 and Alvaro Prat.
New work on Maximum Likelihood Reinforcement Learning:
https://t.co/Ctxe4NvWp6
This work develops Maximum Likelihood Reinforcement Learning (MaxRL), a family of objectives that smoothly interpolates between REINFORCE and maximum likelihood. Our final algorithm requires only a minimal change, a single line of code (dividing by the mean reward in the advantage computation). Empirically, MaxRL shows substantial gains in sample efficiency with perfect verifiers, Pareto-dominates GRPO on reasoning tasks, and exhibits good scaling with both compute and data.
What makes MaxRL particularly compelling is its distinct learning dynamics. It produces larger gradient norms on harder problems, preserving learning signal where other methods tend to wash it out. As a result, a higher fraction of prompts are successfully solved during training. In data-scarce regimes, MaxRL resists overfitting while converging to stronger final performance.
Paper, code, and demos: https://t.co/nRmhgwXtcm
See also an excellent thread by @FahimTajwar10.
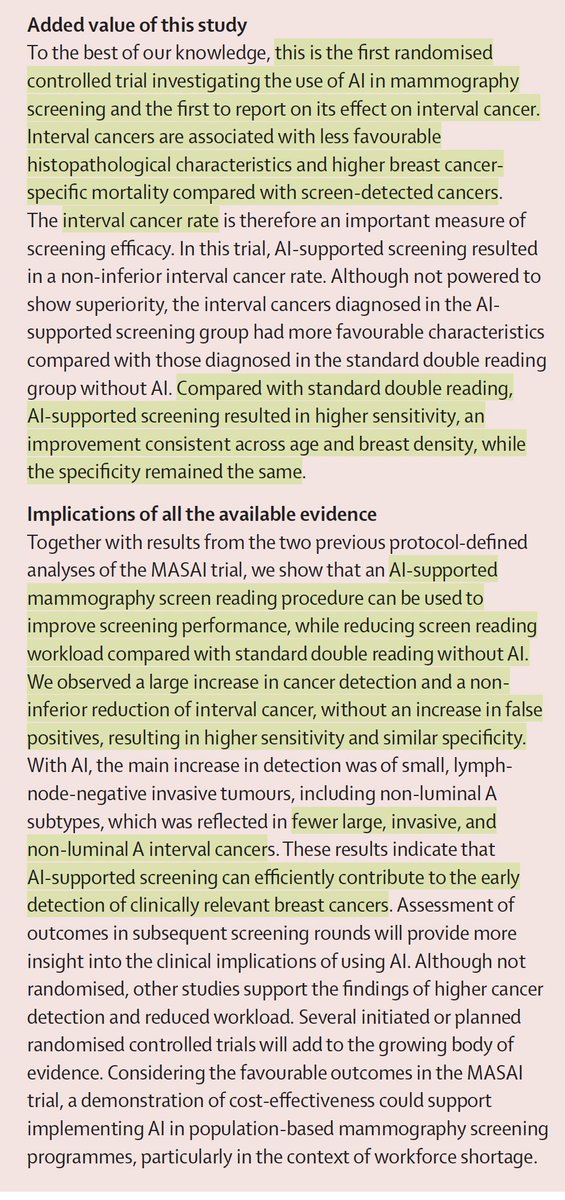
The largest randomized trial of medical A.I.
—Over 100,000 women in Sweden
—radiologist + AI vs 2 radiologists, in follow-up
—AI added led to 29% more cancer detected, 44% reduced workload, and
—Less cancer dx in subsequent 2 years, and, when found, less aggressive
https://t.co/e1hY3F0cGo
Quick read through of Deepseek's new Manifold-Constrained Hyper-Connections paper:
- You want to increase residual size from 1×C to n×C (n streams instead of 1). Earlier residual update: x' = x + layer(x). Make the x be n×C, and use x' = Ax + B layer(Cx) instead. A, B, C are all dependent on x and are small matrices (n×n, n×1, n×1). A seems the most impactful. This is Hyper-Connections (HC).
- HC has the same issue as other residual modification schemes - eventually the product of the learned A matrices (along the identity path) blows up/vanishes.
- To fix this, they project the A matrices onto the Birkhoff polytope (simpler words: transform it, after exp to make elements positive, to a matrix whose row sums and column sums become 1 - called a doubly stochastic matrix). This has nice properties - products of these types of matrices still have row and column sum 1 (due to closure), so things don't explode (spectral bound), and the invariant is that the sum of weights across streams is 1. For n = 1, this becomes the standard residual stream, which is nice. Their transformation method is simple - alternatively divide rows and columns by row and column sums respectively for 20 iterations (converges to our desired matrix as iterations go to infinity). They find 20 is good enough for both forward and backward pass (across 60 layers, maximum backward gain is 1.6 as opposed to 3000 from usual HC, and 1.6 is not very off from 1).
- Composing these matrices (convex hull of all permutation matrices) leads to information mixing as layer index increases, which is a nice piece of intuition and is also shown very clearly in their composite matrix for 60 layers. I believe overall we get a weighted sum of residual paths (thinking of gradients), where logically group-able paths have weights summing to 1. Quite principled approach IMO, also makes gains (forwards and backwards) very stable.
- Interesting thing to note - lot of "pooling"-like mixing in the first half compared to the second half of the layers. Second half of layers treat different channels more precisely/sharply than the first half, quite intuitive.
- They also change parameterization of B and C (sigmoid instead of tanh, to avoid changing signs probably, and a factor of 2 in front of B, I believe to conserve mean residual multiplier, C doesn't need this because input is pre-normed anyway).
- Cool systems optimizations to make this op fast - they do kernel fusion, recomputation in the mHC backward pass, and even modify DualPipe (their pipeline parallelism implementation).
- Only 6.7% overhead in training when n = 4, loss goes down by 0.02 and improvements across benchmarks.
So the challenge is to train good approximations for the ARM suffix partition function (“soft Bellman”). This might give a nice theoretical justification for the recent papers we have seen showing training improvements from predicting future latent states etc
Autoregressive models (ARM) and energy-based models (EBM) are equivalent. But converting ARM into EBM seems similar in difficulty to training an EBM from scratch: partition functions are often hard to calculate.
Our paper "Autoregressive Language Models are Secretly Energy-Based Models: Insights into the Lookahead Capabilities of Next-Token Prediction" is out!
https://t.co/DUTSj4T6X2
A thread summarizing the key take-aways ⬇️