📣📣 Preprint alert 📣📣
« A Lower Bound and a Near-Optimal Algorithm for Bilevel Empirical Risk Minimization »
w. @tomamoral, @vaiter & @PierreAblin
https://t.co/OFbY8JQo6e
1/3
"It's easier to tune the LR for method A than for B."
We tried to formalize this for model-based stochastic optimization methods.
We find a key quantity, called stability index, that describes how stable a (weakly) convex bound is as a function of LR.
📚https://t.co/JIrG0gXqXL
What do JEPA-style self-distillation dynamics actually learn — and why do they sometimes avoid collapse?
In our new work with @BasileTerv987 and Jean Ponce, we tackle this question.
What surprised us: These dynamics provably recover representations with nonlinear-CCA structure.
Our work "Busemann Functions in the Wasserstein Space" was accepted at #AISTATS2026
This is a joint work with Elsa Cazelles, Lucas Drumetz and @nicolas_courty.
I will be presenting it tomorrow at the poster 96, see you there!
Link: https://t.co/PYz53som3g
Nesterov dropped a new paper last week on what functions can be optimized with gradient descent.
The idea is simple: we know GD can optimize both nonsmooth (bounded grads) and smooth (Lipschitz grads) functions, but smooth+nonsmooth satisfies neither property, so what can we do?
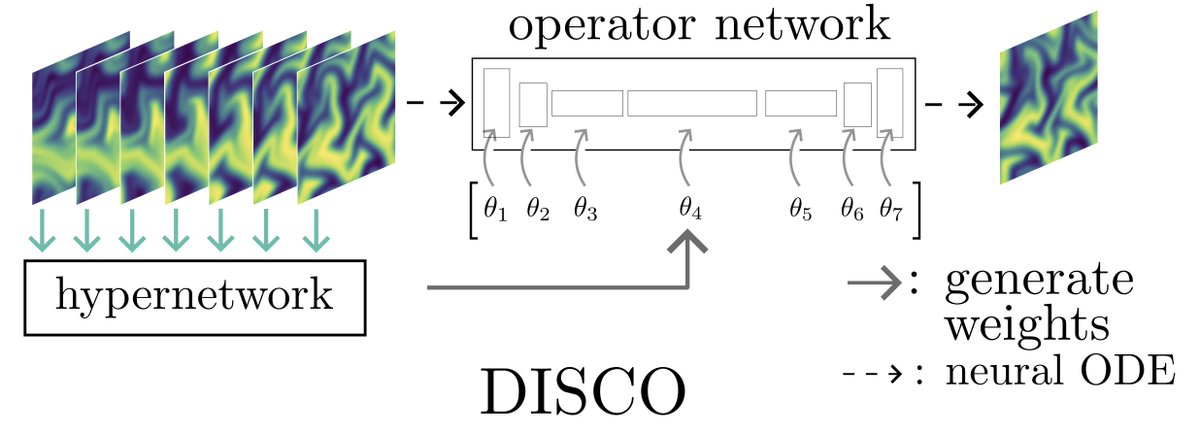
For evolving unknown PDEs, ML models are trained on next-state prediction. But do they actually learn the time dynamics: the "physics"?
Check out our poster (W-107) at #ICML2025 this Wed, Jul 16. Our "DISCO" model learns the physics while staying SOTA on next states prediction!
Back from MLSS Senegal 🇸🇳, where I had the honor of giving lectures on differentiable programming. Really grateful for all the amazing people I got to meet 🙏 My slides are here https://t.co/fWH9FJ7ELm
❓ How long does SGD take to reach the global minimum on non-convex functions?
With @FranckIutzeler, J. Malick, P. Mertikopoulos, we tackle this fundamental question in our new ICML 2025 paper: "The Global Convergence Time of Stochastic Gradient Descent in Non-Convex Landscapes"
I want to address one very common misconception about optimization. I often hear that (approximately) preconditioning with the Hessian diagonal is always a good thing. It's not. In fact, finding a good preconditioner is an open problem, which I think deserves more attention.
1/4
🧵 I'll be at CVPR next week presenting our FiRe work 🔥
TL;DR: We go beyond denoising models in PnP with more general restoration (e.g. deblurring) models!
A starting point observation is that images are not fixed-points of restoration models:
📣 New preprint 📣
**Differentiable Generalized Sliced Wasserstein Plans**
w/
L. Chapel
@rtavenar
We propose a Generalized Sliced Wasserstein method that provides an approximated transport plan and which admits a differentiable approximation.
https://t.co/81C9BGRtko 1/5
It was received quite enthusiastically here so time to share it again!!!
Our #ICLR2025 blog post on Flow M atching was published yesterday : https://t.co/2V5BLl6T2p
My PhD student Anne Gagneux will present it tomorrow in ICLR, 👉poster session 4, 3 pm, #549 in Hall 3/2B 👈
Optimization algorithms come with many flavors depending on the structure of the problem. Smooth vs non-smooth, convex vs non-convex, stochastic vs deterministic, etc. https://t.co/k1KOSFfSUJ
A really fun project to work on. Looking at these plots side-by-side still amazes me! How well can **convex optimization theory** match actual LLM runs?
My favorite points of our paper on the agreement for LR schedules in theory and practice: 1/n
Learning rate schedules seem mysterious?
Turns out that their behaviour can be described with a bound from *convex, nonsmooth* optimization.
Short thread on our latest paper 🚇
https://t.co/DGHoG1FS3f
Learning rate schedulers used to be a big mistery. Now you can just take a guarantee for *convex non-smooth* problems (from https://t.co/2RggKkvmxO), and they give you *precisely* what you see in training large models.
See this empirical study:
https://t.co/kXOOeygaal
1/3
Our work on geometric disentangled representation learning has been accepted to ICLR 2025! 🎊See you in Singapore if you want to understand this gif better :)
The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. https://t.co/FdxBkdLYrw