We’re looking forward to presenting UPLiFT at #CVPR2026! Efficiently extract pixel-dense features from pretrained backbones like DINOv3.
We’ll be at the final poster session on Sunday (6/7) from 3:30-5:30pm at Poster 474, so please come by!
Website: https://t.co/Wng5ZfzjGA
Diffusion models be like:
“this image is 97% noise… better process all 256×256 pixels anyway”
If very noisy diffusion states contain no more useful information than a tiny downsampled image,
Then why run expensive full-res computation on them?
🧵
Excited to announce that UPLiFT has been accepted to #CVPR2026!
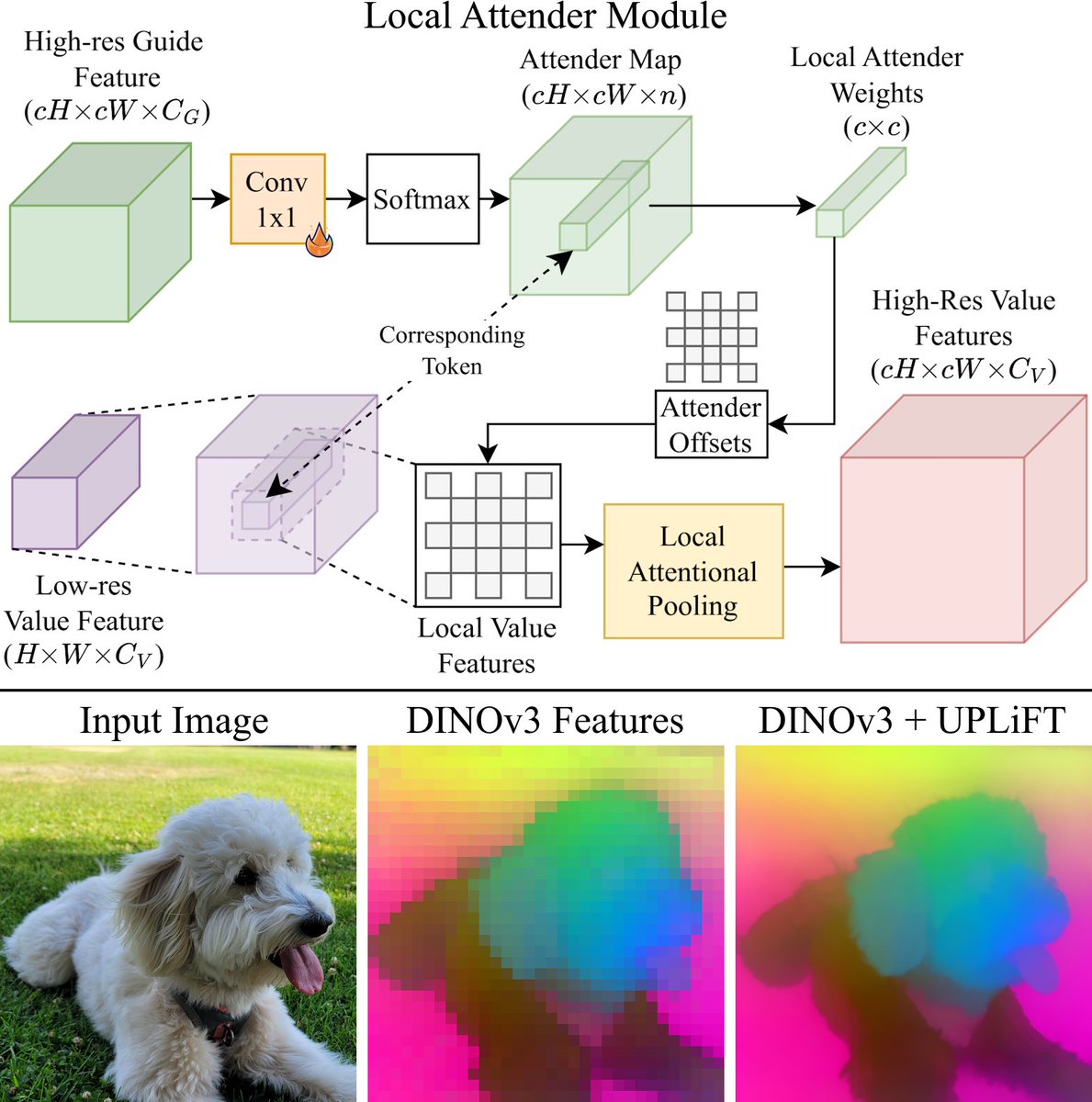
You can also try out UPLiFT right now to extract pixel-dense DINOv3 features with our pretrained models linked below!
Code: https://t.co/slgetOBNPO
Paper: https://t.co/9IqMewyZeG
Website: https://t.co/MJ78gJpXAJ
@Minseok96_kr@_sakshams_@AnirudAgg@abhi2610 Hi Minseok, UPLiFT operates on the VAE's latent features similarly to the DINO features. We do sample the features first, essentially using the features as they would be fed to the VAE decoder later.
We’re excited to announce UPLiFT, our lightweight, pixel-dense feature upsampler. UPLiFT boosts feature density, preserves semantics, and has better efficiency scaling than recent SOTA methods. See all links in the thread below.
Coauthors: @_sakshams_@AnirudAgg@abhi2610
🧵[1/6]
@_sakshams_@AnirudAgg@abhi2610 In addition, UPLiFT + SD1.5 VAE achieves comparable visual quality to the state-of-the-art method FM-Boost (CFM), while using less training data, few parameters, and fewer inference-time iterations.
🧵[6/6]
@_sakshams_@AnirudAgg@abhi2610 We demonstrate the versatility and effectiveness of UPLiFT for both predictive and generative tasks, including semantic segmentation, depth estimation, image super-resolution, and efficient T2I generation.
🧵[5/6]
@_sakshams_@AnirudAgg@abhi2610 Through this approach, our method maintains linear-time-scaling with respect to the number of visual tokens. Meanwhile, cross-attention-based upsamplers have quadratic scaling. This allows UPLiFT to scale and make denser features for larger images.
🧵[4/6]
@_sakshams_@AnirudAgg@abhi2610 UPLiFT uses iterative feature growing, which avoids the high computational costs of recent cross-attention-based methods. We also present a new Local Attender feature-pooling module, which reformulates local attention using operations based on relative directional offsets
🧵[3/6]
Today we are also releasing our UPLiFT code and 3 pretrained models for DINOv2-S/14, DINOv3-S+/16, and SD1.5 VAE. We also include torch hub support and training code.
Paper: https://t.co/9IqMewyZeG
Code: https://t.co/aAqKP7LKCM
Website: https://t.co/MJ78gJpXAJ
🧵[2/6]
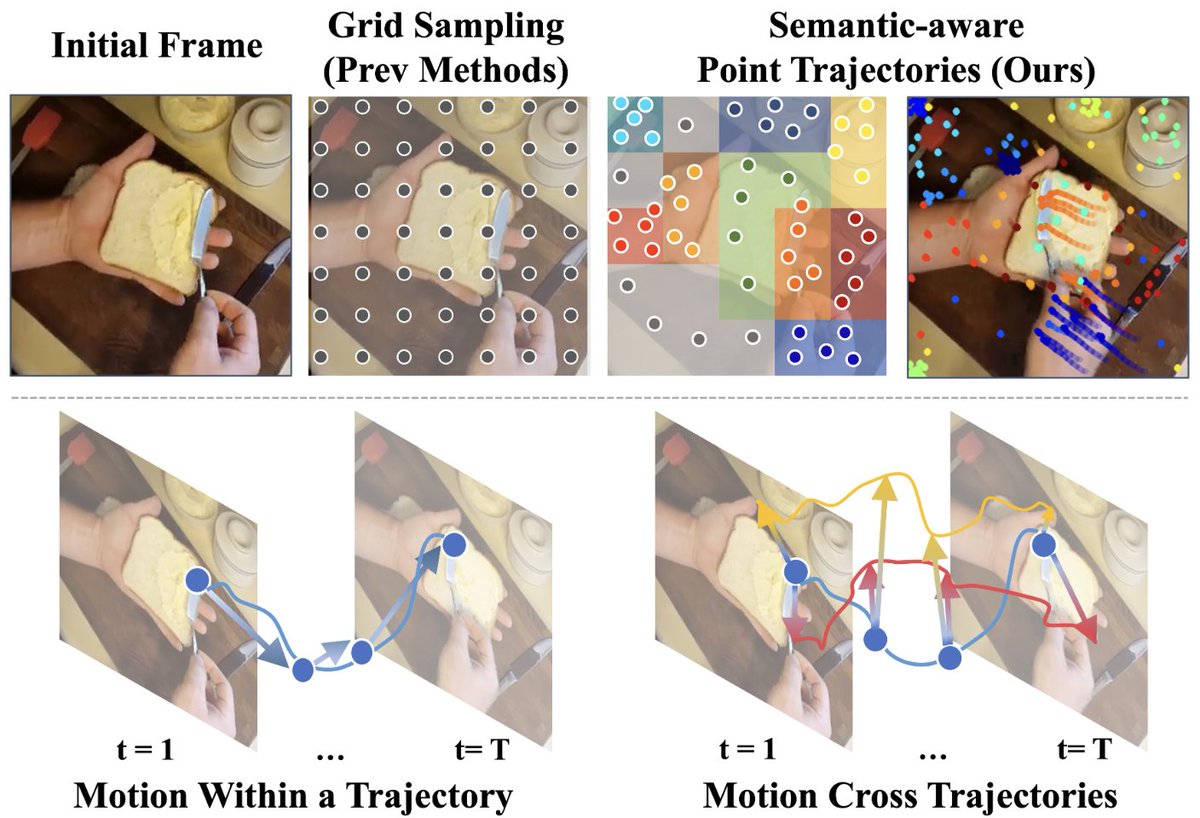
🎉 Excited to share our paper "Trokens: Semantic-Aware Relational Trajectory Tokens for Few-Shot Action Recognition" has been accepted to #ICCV2025!
Equally co-led with @ShuaiyiH — we advance few-shot action recognition via smart point tracking.
🔗 https://t.co/449JI1WiL4
🧵👇
We are happy to release our LiFT code and pretrained models! 📢
Code: https://t.co/vtZSkw1SNs
Project Page: https://t.co/dk21eeDHpi
Here are some super spooky super resolved feature visualizations to make the season scarier 🎃
Coauthors: @MatthewWalmer@kamalgupta09@abhi2610
We introduce LiFT, an easy to train, lightweight, and efficient feature upsampler to get dense ViT features without the need to retrain the ViT.
Visit our poster @eccvconf#eccv2024 in Milan on Oct 1st (Tuesday), 16:30 (local), Poster: 79. Project Page: https://t.co/dk21eeEfeQ
We’re looking forward to presenting our work “Teaching Matters: Investigating the Role of Supervision in Vision Transformers” next week at #CVPR2023! We’ll be in the Tues-PM poster session at board 321.
Links and some key results below.
@_sakshams_@kamalgupta09@abhi2610
[1/5]
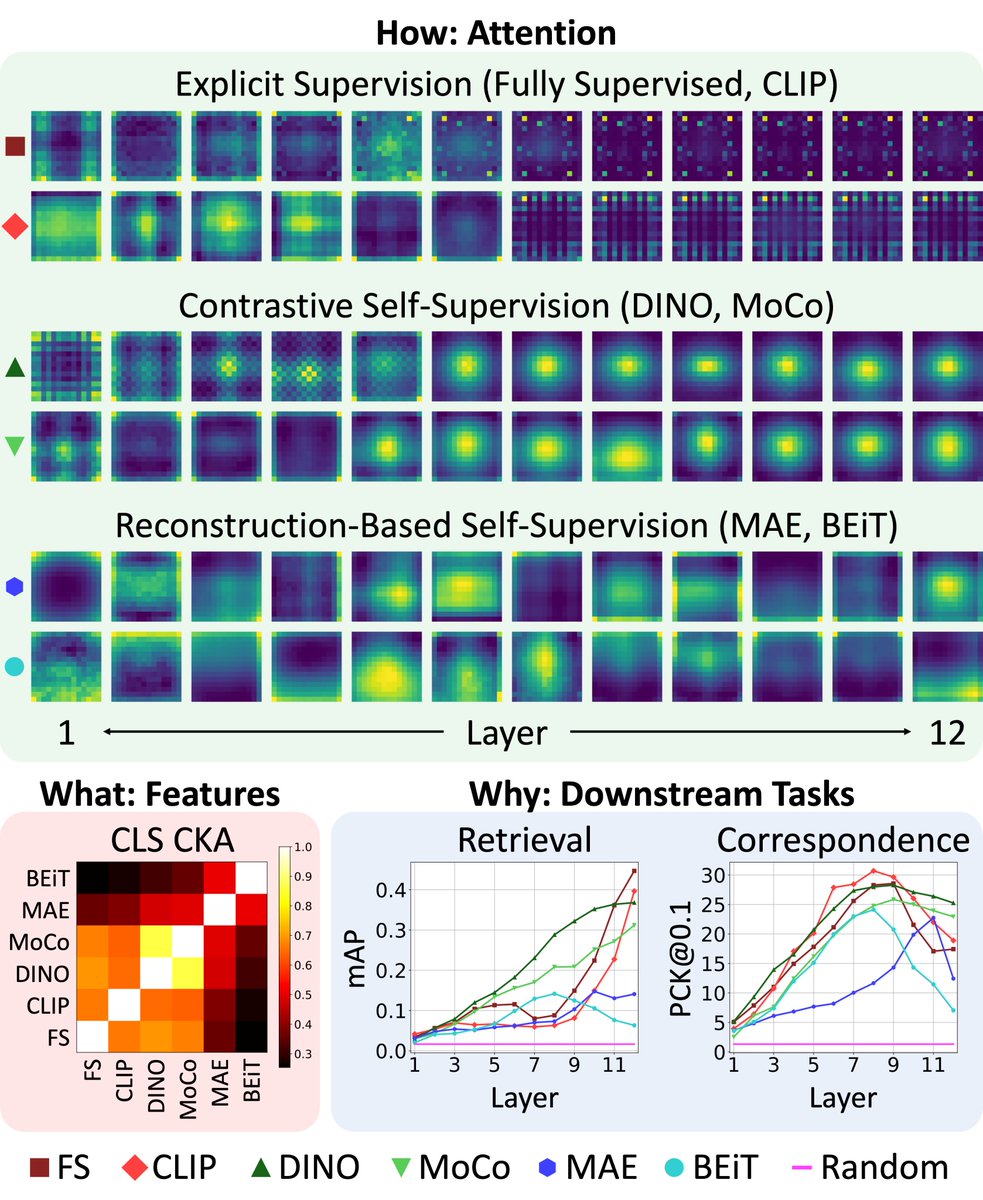
@_sakshams_@kamalgupta09@abhi2610 The best layer for a downstream task varies depending on both the task and the pretraining. For example, on keypoint correspondence, most of the ViTs have their best performance with layers 7 or 8 (of 12). We present comparisons for both locally and globally focused tasks.
[5/5]
We’re looking forward to presenting our work “Teaching Matters: Investigating the Role of Supervision in Vision Transformers” next week at #CVPR2023! We’ll be in the Tues-PM poster session at board 321.
Links and some key results below.
@_sakshams_@kamalgupta09@abhi2610
[1/5]
@_sakshams_@kamalgupta09@abhi2610 Even though MAE has no CLS objective, we find evidence that it learns to embed semantic information in the CLS token even before fine-tuning. Through CKA analysis, we find some similarity between MAE, DINO, and MoCo CLS token representations.
[4/5]
@_sakshams_@kamalgupta09@abhi2610 Did you know that ViTs learn to use offset local attention heads? These heads attend locally, but to a position that is one off in one direction. The existence of these heads may actually demonstrate a strength of CNNs over ViTs.
[3/5]
@_sakshams_@kamalgupta09@abhi2610 We compared ViTs from 6 different supervision methods and identified key similarities and differences between them. We examine: attention, features, and downstream performance.
Paper: https://t.co/M9ju6fquDy
Website: https://t.co/NrlUcuP3tR
Code: https://t.co/TJ756gnP95
[2/5]
Excited to share our work "Teaching Matters: Investigating the Role of Supervision in Vision Transformers" which has been accepted to #CVPR2023!
Work done with: @MatthewWalmer, @kamalgupta09 and @abhi2610
Website: https://t.co/EXdRiIxig6
Code: https://t.co/tptWMo8BFN












![MatthewWalmer's tweet photo. We’re excited to announce UPLiFT, our lightweight, pixel-dense feature upsampler. UPLiFT boosts feature density, preserves semantics, and has better efficiency scaling than recent SOTA methods. See all links in the thread below.
Coauthors: @_sakshams_ @AnirudAgg @abhi2610
🧵[1/6] https://t.co/kjwnKzaGkt](https://pbs.twimg.com/media/G_r4xoMXMAA7CVf.jpg)
![MatthewWalmer's tweet photo. @_sakshams_ @AnirudAgg @abhi2610 In addition, UPLiFT + SD1.5 VAE achieves comparable visual quality to the state-of-the-art method FM-Boost (CFM), while using less training data, few parameters, and fewer inference-time iterations.
🧵[6/6] https://t.co/6rXgTrPIf9](https://pbs.twimg.com/media/G_r6KSgXEAAhsCC.jpg)
![MatthewWalmer's tweet photo. @_sakshams_ @AnirudAgg @abhi2610 We demonstrate the versatility and effectiveness of UPLiFT for both predictive and generative tasks, including semantic segmentation, depth estimation, image super-resolution, and efficient T2I generation.
🧵[5/6] https://t.co/ZfESw4cjhN](https://pbs.twimg.com/media/G_r6CDqXwAA0LON.jpg)
![MatthewWalmer's tweet photo. @_sakshams_ @AnirudAgg @abhi2610 Through this approach, our method maintains linear-time-scaling with respect to the number of visual tokens. Meanwhile, cross-attention-based upsamplers have quadratic scaling. This allows UPLiFT to scale and make denser features for larger images.
🧵[4/6] https://t.co/riEGEpoV1m](https://pbs.twimg.com/media/G_r52iqXcAEO1C9.jpg)
![MatthewWalmer's tweet photo. @_sakshams_ @AnirudAgg @abhi2610 UPLiFT uses iterative feature growing, which avoids the high computational costs of recent cross-attention-based methods. We also present a new Local Attender feature-pooling module, which reformulates local attention using operations based on relative directional offsets
🧵[3/6] https://t.co/Cg1MIFPibP](https://pbs.twimg.com/media/G_r5m1AWQAEa7AJ.jpg)
![MatthewWalmer's tweet photo. Today we are also releasing our UPLiFT code and 3 pretrained models for DINOv2-S/14, DINOv3-S+/16, and SD1.5 VAE. We also include torch hub support and training code.
Paper: https://t.co/9IqMewyZeG
Code: https://t.co/aAqKP7LKCM
Website: https://t.co/MJ78gJpXAJ
🧵[2/6] https://t.co/6ZsRDt8MKt](https://pbs.twimg.com/media/G_r5L_PXUAEz4QI.jpg)

![MatthewWalmer's tweet photo. @_sakshams_ @kamalgupta09 @abhi2610 The best layer for a downstream task varies depending on both the task and the pretraining. For example, on keypoint correspondence, most of the ViTs have their best performance with layers 7 or 8 (of 12). We present comparisons for both locally and globally focused tasks.
[5/5] https://t.co/EOqckU1DOy](https://pbs.twimg.com/media/FygnTfvaEAMWmtf.png)
![MatthewWalmer's tweet photo. @_sakshams_ @kamalgupta09 @abhi2610 Even though MAE has no CLS objective, we find evidence that it learns to embed semantic information in the CLS token even before fine-tuning. Through CKA analysis, we find some similarity between MAE, DINO, and MoCo CLS token representations.
[4/5] https://t.co/mLdDut5vhT](https://pbs.twimg.com/media/FygnFlfaQAAHUj0.jpg)
![MatthewWalmer's tweet photo. @_sakshams_ @kamalgupta09 @abhi2610 Did you know that ViTs learn to use offset local attention heads? These heads attend locally, but to a position that is one off in one direction. The existence of these heads may actually demonstrate a strength of CNNs over ViTs.
[3/5] https://t.co/sms8Jxycvg](https://pbs.twimg.com/media/Fygm-UXagAM8ml-.png)
![MatthewWalmer's tweet photo. @_sakshams_ @kamalgupta09 @abhi2610 We compared ViTs from 6 different supervision methods and identified key similarities and differences between them. We examine: attention, features, and downstream performance.
Paper: https://t.co/M9ju6fquDy
Website: https://t.co/NrlUcuP3tR
Code: https://t.co/TJ756gnP95
[2/5] https://t.co/DbnNvg80kd](https://pbs.twimg.com/media/Fygmx1paIAcLV_Y.jpg)