Exciting news! 10 months ago I started writing the book I wished I had when I was learning how LLMs actually work — from the inside. 934 pages. 35 projects. Every chapter has a section on how to break the thing you just built.Built. Broken. Measured. Understood.
For the next 24 hours: $9.99 with code MURAI200. Regular price $35. https://t.co/9hANb7VIAK
@sumanthraman What was the role about? What was the company hiring known for? What career scope did you offer to the candidate? And yeah like every other comment - why do you talk about CTC?
This is a good project idea for folks who want to really understand the power of Local LMs - I have done something similar trying to find solutions to some problems which are heavy in the patent law space for a client of @MuraiLabsHQ - this takes it several notches higher of course!
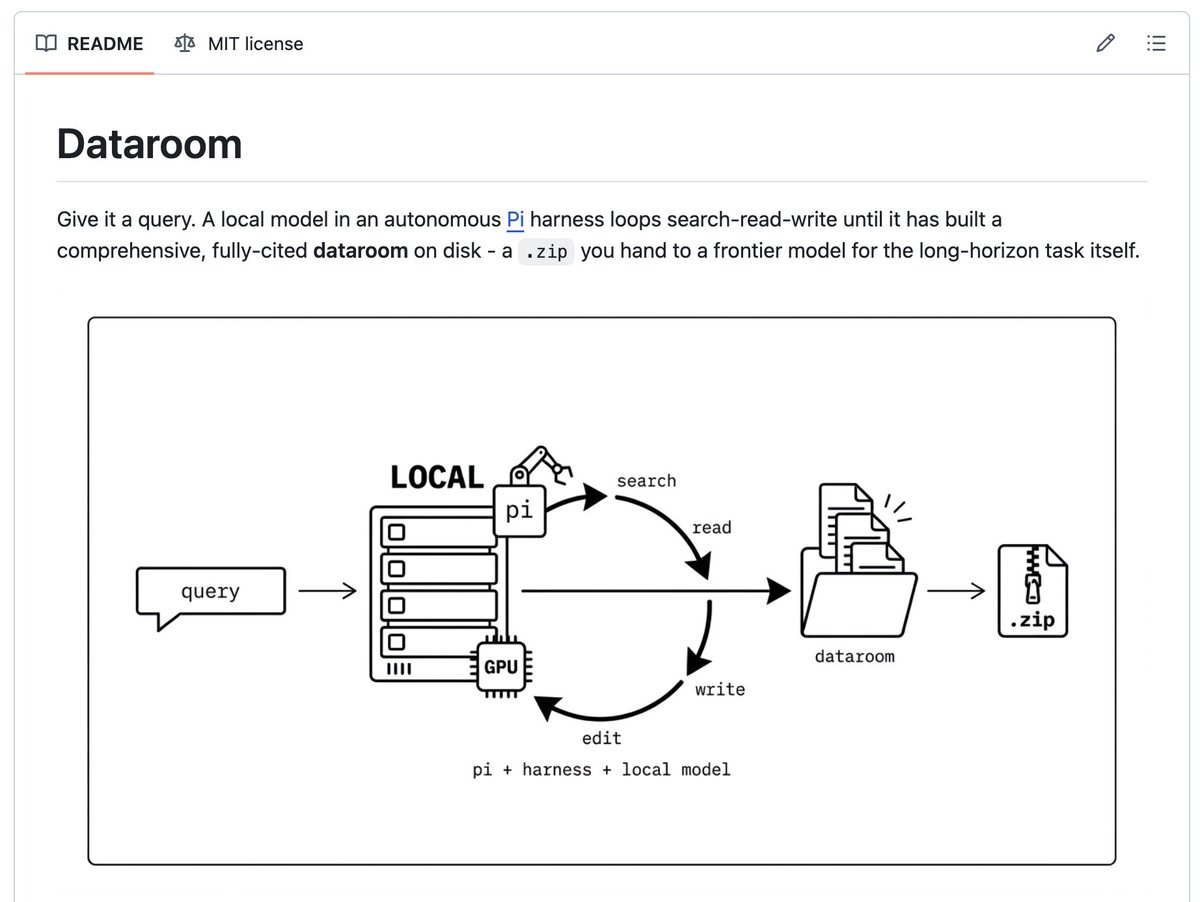
Sharing a project I've been heavily using - Dataroom. It's a local-first harness that runs deep research with a small language model and gives a zip file at the end. Deep research is becoming an important first step for long-horizon tasks (the 2nd step being implementation), and I believe a small local model in a disciplined harness handles it well - we shouldn't waste frontier-model tokens on it. Dataroom runs on your own GPU at near-zero marginal cost, and it can keep going for hours until the dataroom is genuinely comprehensive, instead of stopping when a metered budget runs out.
Today we're shipping our biggest MLX-VLM release yet: v0.6.0
...and we are raising 💸
This one's about turning your Apple devices into real local agent machines. From your desk to your pocket.
What's new:
⚡ Speculative decoding everywhere — Gemma 4 EAGLE3 + DFlash, Qwen MTP, DeepSeek V4 MTP. Faster tokens, less waiting.
🤖 Agent-ready server — native Anthropic /v1/messages API, stateful /v1/responses, tool calls, Codex context budgets. Plug Claude Code & Codex straight into local models.
👁️ New models galore — DeepSeek V4, ZAYA1-VL, MiniCPM-V 4.6, LFM2 MoE, Step-3.7 Flash, Laguna + more.
🎨 Image gen & editing — FLUX.2 (base + klein), PrismML Bonsai.
🔊 Audio in — Qwen3 Omni, Gemma 4 audio, base64 chat audio.
🧮 TurboQuant KV cache — RHT-correct fast paths for leaner memory.
📦 Modular server, better metrics, cleaner streaming.
Run real agents on the hardware already in your hands.
Github: https://t.co/1T06ur6LU5
Well, just woke up to find my gpu is probably fried. I had so many things to do on that powerhouse of a PC - and now I am trying to figure out what to do.
Maybe that culture is fine for you at linear, and it looks like it’s working great for you! You’ve created something worth over a billion dollars in 7 short years, that’s something very few people on the planet have done before.
But sometimes there are big problems that need solving, and there is more creative thinking, not less, that happens with contact with the big problems. In our case, creating the financial operating system that owns the creation, transfer, financing, and investment of risk, using AI to automate the paperwork of the most regulated entities to make every business and person a little more profitable, waste a lot less time, and be more protected, is a big problem.
Maybe there were super geniuses at the Manhattan Project working 1 day per week like zen masters. I doubt it though, because if you’re obsessed with a problem, you work hard. Nowhere did I or do I glorify lack of sleep (I always think sleeping right and exercise are very important), and different people have different visions, cadences, and ways they want to run their companies. And that’s ok, but you attacking our style based upon sound bites when we are solving a really important problem, by market sizing probably the biggest problem large language models can solve, isn’t it.
🏃♂️ I've gamified my own run so I can race my own ghost with the Meta Ray-Ban Display.
I built a web app for the glasses, loaded a previous GPX from Strava, and dropped game mechanics on top.
Pick up coins when you keep pace, sprint zones reward extra points if you push, and a mini leaderboard on the lens shows how you're tracking against your past self in real time.
Best part: it actually works. Seeing your ghost 20 m ahead is a way stronger nudge than any number on a watch. 😅
@enjojoyy I break down anything and everything into specs and tasks first - then let codex go free while I sleep - with instructions on when to stop, what to do before and after each set of tasks, etc
@petergyang@NousResearch I would say stress on the kids that as much as a model sounds human, its machine prediction and it tells them what they want to hear.
NVIDIA dropping Qwen3.6-35B-A3B in NVFP4 is the kind of release I actually care about - not because of headline params, because it changes what I can run tonight without pretending I have hyperscaler budget. 35B total with ~3B active + quantization is a very real operator story when your workflow is vLLM logs, KV cache tradeoffs, and power bills. Model: https://t.co/PPffiDSpUc
@Neechalkaran Will do! Once I get to post training, I would love to collaborate with you! P.S - i just missed your hackathon! Many of those ideas are exactly what is driving me to do this as well!
The most valuable thing my pipeline did this week was tell me my "reproducibility" was an artifact. Three "independent" seeds turned out to share 15 of 16 starting organisms — a one-line bug in seed derivation. Caught it before submission, rebuilt the grid, and the result survived the re-run. Disciplined engineering beats impressive-looking tables.
One thing I am learning while collecting Tamil language data is that the language itself is a beast - something that has survived for 2.5k years - in writing and speech, has gone through so many structural changes - the sheer scale is daunting but not giving up. At some point, I will beg my tamil diaspora for help with the effort as at this stage it seems too huge for a single person. More on that later
Build log on what “in progress” actually means:
→ Tokenizer: frozen at 64K BPE. ~10% better compression on Tamil than a 32K vocab — matters a lot for an agglutinative language.
→ Architecture: running a Transformer baseline against Mamba-3 SSM variants at 100M & 300M. Measuring held-out loss across seeds before committing. Transformer’s leading so far — still pressure-testing the SSM side.
→ Data: corpus QC across registers, classical to contemporary. Quality over scraped scale.
→ Next: lock the architecture from the scaling runs, then commit the full training recipe.
Not a fine-tune. Not a translation layer. Tamil first, from zero.
Announcing TamilLM 🪔
A from-scratch, Tamil-first language model — built around Tamil’s morphology and registers, not retrofitted from English.
Architecture bake-off in progress. Tokenizer frozen. Corpus QC underway.
Building in the open. முறை