I recently spoke about Deep Regression, a topic which excites me since it also powers uncertainty estimation and variational inference.
Slides: https://t.co/9QQSZUYtMr
This talks about our recent works in ICML 2024, ICLR 2025, and a preprint.
@AlexAlahi@Amerile_
Bro I'm so sick of pretending this isn't weird.
The internet spent 20 years creating tutorials, open-source projects, blog posts & answers for free.
AI companies turned all of it into products worth billions.
And now the same people who created that knowledge are being told they're replaceable.
We built the library.
Someone else started charging admission.
If your LLM feels more robotic with each new release, it is.
Training AI on AI-generated data is tempting, but it can make AI dumber in some ways.
The training data -- the internet -- is no longer human generated diversity & originality. It is poisoned with AI-generated slop.
Personal update: I’ve decided to leave OpenAI. Not that I ever worked there. But it just looks like everyone else is doing it, so I thought I'd hop on the bandwagon.
In other news, I've decided to join @AnthropicAI to work on AGI for the benefit of Claude. I don't think they realize that I've decided to join, and to be honest, I don't think my decision carries much weight with them, since I wasn't offered a job there.
But the decision stands.
Excited to share that I’ll join @NUSComputing as an Assistant Professor in 2027
🏛️ I’ll build LEMA Lab: https://t.co/qzKA7dpA00, study the principles of embodied intelligence, & empower every lab member to thrive
📢 Recruiting 3-6 PhD students in the next application cycles
Most research time isn’t spent thinking of ideas.
It’s spent checking prior work, testing hypotheses, debugging silent bugs, organizing results, making slides.
The parts where weeks of work silently disappear.
I tried encoding some of that experience as “Agent Skills”.
Coding is only a small fraction of what a CS PhD student actually does; perhaps 10–30% of their time. The real goal of a PhD, and of being a professor, is not to outsource research work but to educate and train the next generation of scientists: people who deeply understand their field, can think critically about it, and ultimately become experts capable of pushing the frontier of knowledge forward.
Coding is probably one of the least interesting part of being a CS PhD. We need human experts even more than before at the age of AI.
"If I believe everything I see on X, robotics is being solved every week" @JitendraMalikCV's joke in his CMU talk hits hard⚠️
With so many new papers on robot memory, how far have we really come?
Check out https://t.co/sPsqFqF2Xs benchmark & join the upcoming challenge @CVPR🏆
I’m really afraid that the world is converging on a single way to express and write… Content on social media follow the same pattern as LLM writing, to the point that if the rhythm in the sentence sounds familiar, I skip the post, only to find more like those in my feed!
researchers at Max Planck analyzed 280,000 transcripts of academic talks and presentations from YouTube
they found that humans are increasingly using ChatGPT's favorite words in their spoken language. not in writing. in speech.
"delve" usage up 48%. "adept" up 51%. and 58% of these usages showed no signs of reading from a script.
we talk about model collapse when AI trains on AI output. this is model collapse, except the model is us.
🚀New preprint: DAVE — Distribution-aware Attribution via ViT Gradient DEcomposition.
1/11 🔍 What’s new:
We fix a persistent issue in ViT explainability: unstable, artifact-heavy pixel attributions. DAVE yields fine-grained pixel-level maps without patch-grid saliency.
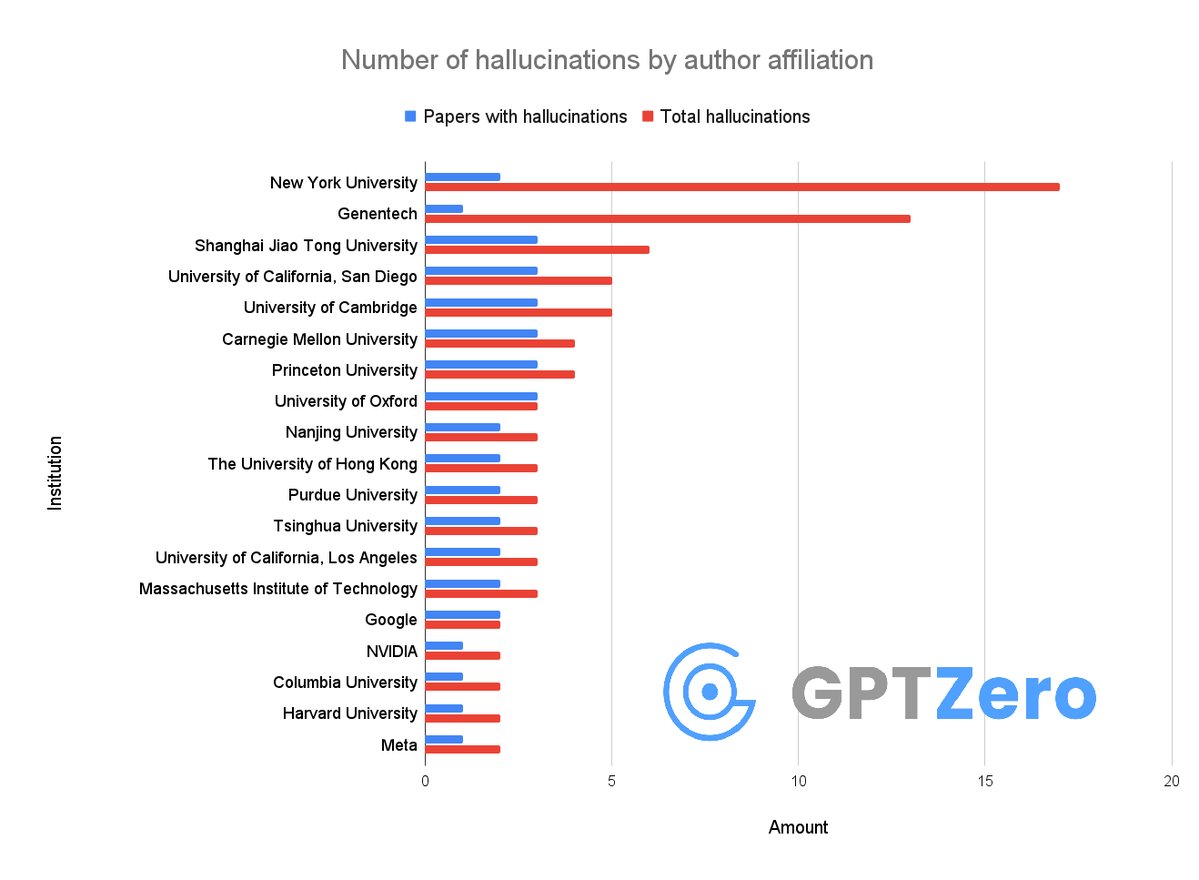
Okay so, we just found that over 50 papers published at @Neurips 2025 have AI hallucinations
I don't think people realize how bad the slop is right now
It's not just that researchers from @GoogleDeepMind, @Meta, @MIT, @Cambridge_Uni are using AI - they allowed LLMs to generate hallucinations in their papers and didn't notice at all.
It's insane that these made it through peer review👇
We are hiring Members of Technical Staff (Research Engineers)!
Current LLM agents lack reliability, creating a gap between demos and production. We solve this by automating the complex workflow of debugging, evaluation, and iteration required to make agents robust. 👇
I'm just a chess enthusiast, but I always enjoyed Daniel Naroditsky's rich commentary. There was something very soothing in his voice too. Please do watch Sagar Shah's tribute to this amazing, amazing person. Mental & physical health >>> everything else
https://t.co/6A9IodAq2U