DeepSeek moment is here AGAIN. v2.
The biggest AI release of 2026 so far, just dropped.
It's not from OpenAI. Not from Anthropic. Not from Google.
DeepSeek V4: 1M context, MIT license, frontier performance, for a fraction of cost.
Here's why it AGAIN reshapes the industry🧵
Vera CPU goes into full production alongside Rubin. Two silicon platforms shipping in the same window.
That is a dual-track strategy. Nvidia is not waiting for GPU demand to absorb the CPU line. they are running both in parallel from day one.
Computex 2026 the Era of Agentic AI
Vera CPU and Agent Toolkit Position NVIDIA for Agentic AI : Backed by orders from Oracle, we see Nvidia’s revenue visibility of $20bn for standalone Vera CPU as reasonable.
=> Vera CPU chain: Kinsus, AMKR
Vera Rubin Family for AI Agents: Nvidia announced that it is now in full production of its Vera Rubin platform, and we expect a deep ramp for Rubin Sept and Vera Rubin NVL72 in Oct.
NVIDIA RTX Spark to Power AI Agent PC: We believe this expands Nvidia’s position toward AI PC but will still be niche, given the on-going issues of compatibility with ARM, suggesting limited impact to Intel and AMD
=> per our earlier notes, we expect NVDA to have collaboration with Intel too, not just ARM.
Nvidia Financial Analyst Q&A Meeting:Nvidia announced to return at least 50% of free cash flow. Mgmt believes Vera CPU addresses a new market rather than taking share, with its CPU volume opportunities exceeding GPU’s over time.
Intel Restores CPU Importance Amid Good 18A yields with 3 CPU SKUs in production.
#NVDA #INTC #Computex
@MicrosoftAI 5B active and cold-started from scratch.
every iteration costs more, but the model picker now has a second supplier.
https://t.co/1J87rvttJe
Microsoft, OpenAI's largest backer, just shipped a coding model with 5 billion active parameters that is now a default inside VS Code, and it did not distill a single token from OpenAI to build it.
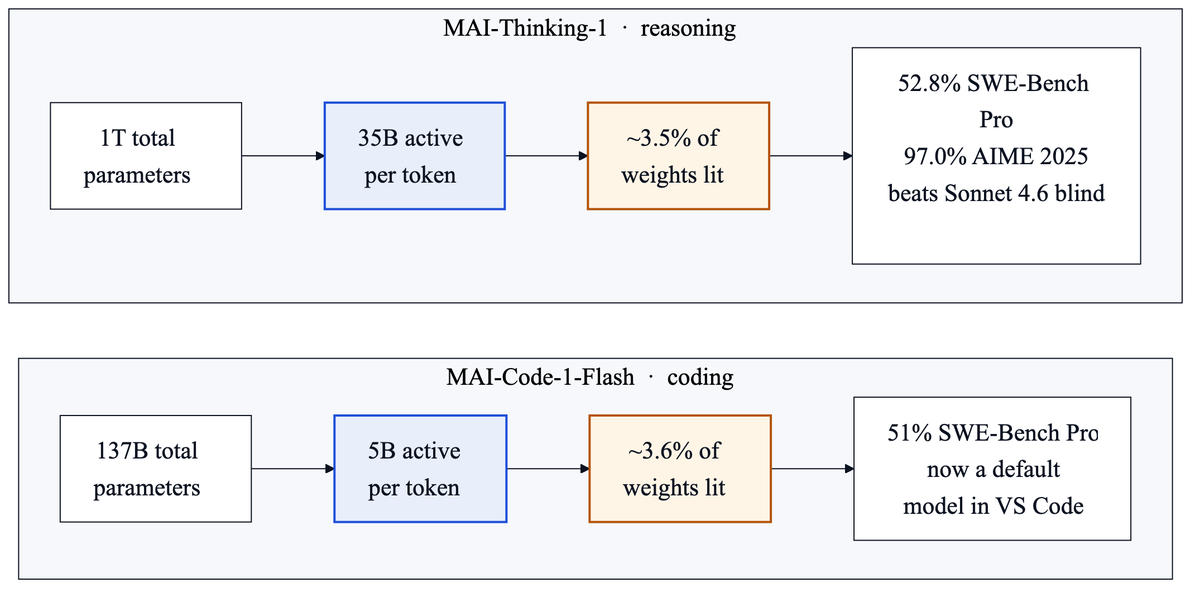
at Build this week Microsoft AI shipped two in-house models. MAI-Thinking-1 is its first reasoning model, a 1T total / 35B active mixture-of-experts, the architecture where only a small slice of the weights fire on any given token. it scores 52.8% on SWE-Bench Pro, 97.0% on AIME 2025, 87.7% on LiveCodeBench v6, and is preferred to Anthropic's Sonnet 4.6 in blind human side-by-side ratings. MAI-Code-1-Flash is the small one: 137B total, 5B active, 51% on SWE-Bench Pro, already rolling out as a default model in GitHub Copilot inside VS Code.
both models light only about 3.5% of their weights on any given token: 35B out of 1T, and 5B out of 137B. active parameters set your inference cost. total parameters set the memory you keep warm. Microsoft picked architectures where the serving bill stays low while capability climbs, because they are the ones who have to answer Copilot for hundreds of millions of seats.
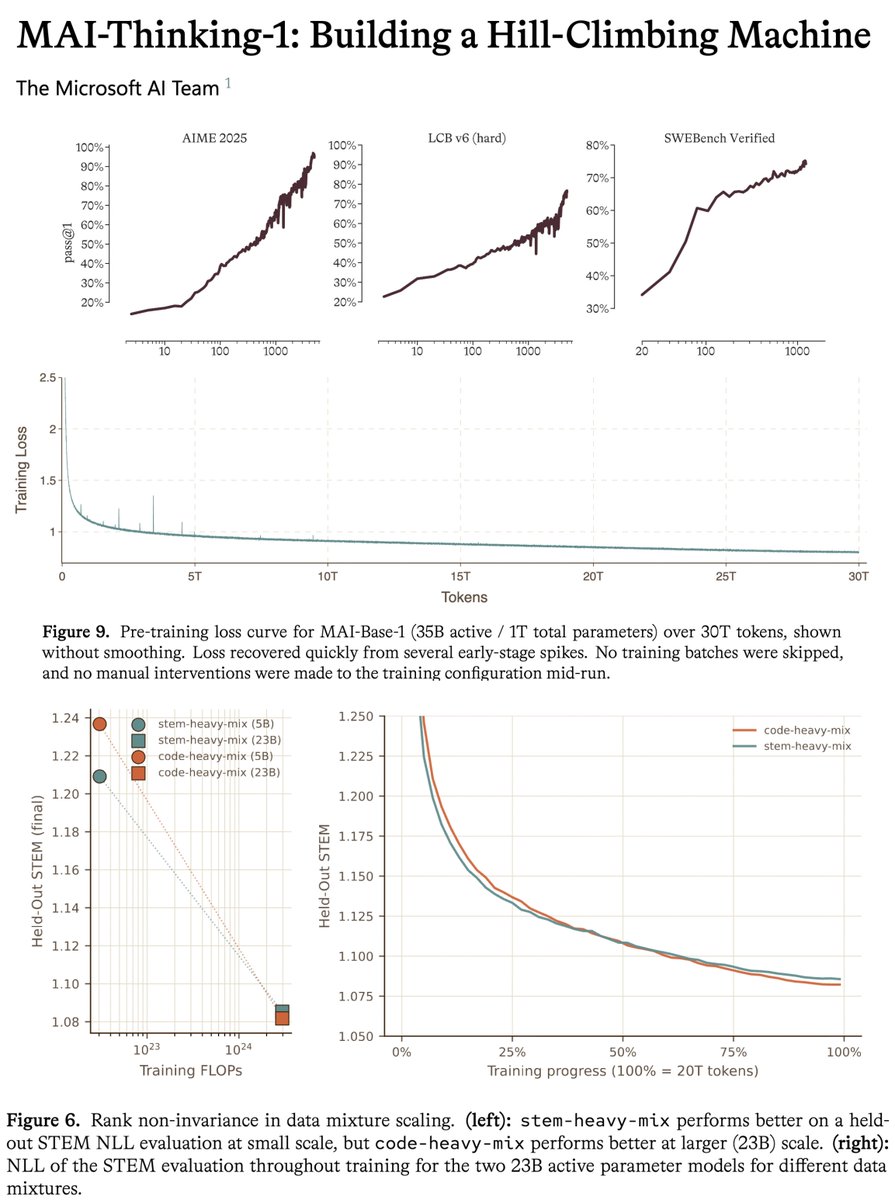
and they built it from scratch. MAI-Base-1, the foundation under Thinking-1, was pretrained on 8,000 GB200 GPUs in an Azure cluster, 30 trillion tokens of pretraining plus 3.55 trillion of mid-training, then a reinforcement-learning climb over thousands of steps. no distillation from third-party models. the company that distributes OpenAI just demonstrated it can build a frontier-grade reasoning model with OpenAI nowhere in the loop.
the dependency did not break. it became optional.
for anyone routing models in production the read is narrow. a 5B-active coding model arriving as a default in VS Code means the cheap-and-good tier just moved in-house at the largest model distributor on earth. your next inference contract gets priced against Microsoft's own serving cost, and that floor just dropped.
The key failure mode here is 'context truncation' in human review, where you start missing subtle errors once you hit more than a handful of agent interactions.
@weaviate_io agent memory fails when the harness can't decide what's worth storing.
Engram's pipeline approach is one fix, but the harder problem is eval suites that don't trace production tool calls.
https://t.co/EMHqYdovkm
@nvidia Cosmos 3 is the first time that world-model bet shipped as one weight set across generation, policy, and vision.
the robot action head is the hard part. most labs still split those into separate models.
https://t.co/EMHqYdovkm
@amasad on DeepSWE gpt-5.5 at xhigh burned 3x for a 70% pass.
opus 4.8 at max: 58%. the 12-point gap costs more than the tier jump.
https://t.co/a8ed72wLJu
gpt-5.5 vs opus 4.8 and where they land on the cost-per-task frontier.
the model that wins your eval by twelve points can still triple your bill. that is the trap hiding in every gpt-5.5 vs opus 4.8 screenshot going around this week.
here is the part the leaderboard crops out. on DeepSWE, a long-horizon coding benchmark where every model runs through the same mini-swe-agent harness, gpt-5.5 at its xhigh tier lands 70% pass@1. claude opus 4.8 at max lands 58%. most people stop reading there and call it a clean twelve-point win for openai.
then you price the column.
to clear that same benchmark, opus 4.8 costs $12.58 per task against gpt-5.5's $6.61. it takes 43 minutes against 21. it emits 136k output tokens against 47k. so for the privilege of scoring twelve points lower, opus runs about 1.9x the cost, 2x the wall-clock, and 2.9x the output tokens. the pass rate is the one number on that row that never shows up on your invoice.
and it gets worse for the leaderboard-first crowd. gpt-5.4, openai's previous model, scores 56% at $4.38 per task. that lands within two points of opus 4.8 at roughly a third of the cost. you did not even need the new model to win the efficiency argument against anthropic's flagship.
now the honest counterpoint, because it matters. flip to the artificial analysis index, an aggregate quality score, and opus 4.8 edges gpt-5.5 on raw capability, with gpt-5.5-high landing about two points behind it while spending roughly a third of the tokens. change the benchmark and the quality lead changes hands. that is the actual finding here. the quality race between these two is a coin flip inside a couple of points in either direction. the efficiency race is a blowout, and it only points one way.
so ask which gap compounds. on a single chat completion, a 2.9x token difference is rounding error nobody feels. on an agentic loop that reasons for 40 minutes and emits 130k tokens per task, output tokens are the bill, and you pay that multiplier on every task, every run, every day you keep the system in production.
pick the model that tops the benchmark you happened to screenshot, and you optimized for the one number that costs you nothing. price the whole column instead. intelligence per dollar is the only score that survives contact with a production budget.
no synthetic data, no distillation from a previous model. they cold-started reasoning and tool use in post-training from scratch.
that means every iteration costs more and takes longer. it also means the model lineage is clean.
microsoft MAI tech report is a gold mine, one of the most transparent for a model at this scale.
this model uses zero synthetic data or distillation from previous models. this means reasoning, agentic behavior, tool use are all learned fully during post-training with no cold start. bold choice that makes it harder and requires more iterations to reach sota, but you get FULL control over your model series and it proves they are serious about being a frontier lab.
the tech report is insanely detailed and precise about numbers. to give an example, they give the exact MFU across all the iterations of the model, with the exact changes etc. they also share the full scaling ladder recipe, to my knowledge this is the first time i've seen this in a tech report at this scale
let's look at all of this in this likely very long thread 🧵
Microsoft, OpenAI's largest backer, just shipped a coding model with 5 billion active parameters that is now a default inside VS Code, and it did not distill a single token from OpenAI to build it.
at Build this week Microsoft AI shipped two in-house models. MAI-Thinking-1 is its first reasoning model, a 1T total / 35B active mixture-of-experts, the architecture where only a small slice of the weights fire on any given token. it scores 52.8% on SWE-Bench Pro, 97.0% on AIME 2025, 87.7% on LiveCodeBench v6, and is preferred to Anthropic's Sonnet 4.6 in blind human side-by-side ratings. MAI-Code-1-Flash is the small one: 137B total, 5B active, 51% on SWE-Bench Pro, already rolling out as a default model in GitHub Copilot inside VS Code.
both models light only about 3.5% of their weights on any given token: 35B out of 1T, and 5B out of 137B. active parameters set your inference cost. total parameters set the memory you keep warm. Microsoft picked architectures where the serving bill stays low while capability climbs, because they are the ones who have to answer Copilot for hundreds of millions of seats.
and they built it from scratch. MAI-Base-1, the foundation under Thinking-1, was pretrained on 8,000 GB200 GPUs in an Azure cluster, 30 trillion tokens of pretraining plus 3.55 trillion of mid-training, then a reinforcement-learning climb over thousands of steps. no distillation from third-party models. the company that distributes OpenAI just demonstrated it can build a frontier-grade reasoning model with OpenAI nowhere in the loop.
the dependency did not break. it became optional.
for anyone routing models in production the read is narrow. a 5B-active coding model arriving as a default in VS Code means the cheap-and-good tier just moved in-house at the largest model distributor on earth. your next inference contract gets priced against Microsoft's own serving cost, and that floor just dropped.
gpt-5.5 vs opus 4.8 and where they land on the cost-per-task frontier.
the model that wins your eval by twelve points can still triple your bill. that is the trap hiding in every gpt-5.5 vs opus 4.8 screenshot going around this week.
here is the part the leaderboard crops out. on DeepSWE, a long-horizon coding benchmark where every model runs through the same mini-swe-agent harness, gpt-5.5 at its xhigh tier lands 70% pass@1. claude opus 4.8 at max lands 58%. most people stop reading there and call it a clean twelve-point win for openai.
then you price the column.
to clear that same benchmark, opus 4.8 costs $12.58 per task against gpt-5.5's $6.61. it takes 43 minutes against 21. it emits 136k output tokens against 47k. so for the privilege of scoring twelve points lower, opus runs about 1.9x the cost, 2x the wall-clock, and 2.9x the output tokens. the pass rate is the one number on that row that never shows up on your invoice.
and it gets worse for the leaderboard-first crowd. gpt-5.4, openai's previous model, scores 56% at $4.38 per task. that lands within two points of opus 4.8 at roughly a third of the cost. you did not even need the new model to win the efficiency argument against anthropic's flagship.
now the honest counterpoint, because it matters. flip to the artificial analysis index, an aggregate quality score, and opus 4.8 edges gpt-5.5 on raw capability, with gpt-5.5-high landing about two points behind it while spending roughly a third of the tokens. change the benchmark and the quality lead changes hands. that is the actual finding here. the quality race between these two is a coin flip inside a couple of points in either direction. the efficiency race is a blowout, and it only points one way.
so ask which gap compounds. on a single chat completion, a 2.9x token difference is rounding error nobody feels. on an agentic loop that reasons for 40 minutes and emits 130k tokens per task, output tokens are the bill, and you pay that multiplier on every task, every run, every day you keep the system in production.
pick the model that tops the benchmark you happened to screenshot, and you optimized for the one number that costs you nothing. price the whole column instead. intelligence per dollar is the only score that survives contact with a production budget.
@lqiao@FireworksAI_HQ APIM hub still publishes the AI surface.
adding Fireworks to the spoke side just extends the same serving problem. more models, same metering and redact pipeline.
https://t.co/XAg2yW98UJ
The hub and spoke talk through access and publish contracts.
APIM hub publishes the AI surface: rate, redact, meter, log.
Foundry spokes consume it: auth, quota, observability.
Same pattern that won for data platforms 5 years ago, now for model serving.
put your expensive model on the solver and your cheap one on the evolver.
the paper shows Qwen3.5-9B writes edits as good as Opus 4.6. the gain is on the solver side.
Very good advice on self-improving agents.
(bookmark it)
This is something I am seeing in my own experiments with coding agents and harnesses for long-horizon tasks.
What I have found is that stronger models do not always evolve better agents.
The current believe in self-evolving agents is that a bigger model writes better prompt and skill edits, so devs put their best model in the evolver seat.
New research shows that intuition is mostly wrong.
The work separates two abilities that usually get conflated. Producing harness updates stays flat across model capability, so Qwen3.5-9B writes edits roughly as good as Claude Opus 4.6. Benefiting from those updates follows an inverted-U that peaks at mid-tier models, while weak models fail to even activate the edits and strong models have little headroom left.
This is important to understand as it tells you where to spend. Put a cheap model on the evolver and your expensive model on the solver, because the gains land solver-side, not evolver-side.
Paper: https://t.co/8kJwR7NhmV
Learn to build effective AI agents in our academy: https://t.co/1e8RZKs4uX
@omarsar0 manual trace review breaks around 3 agents.
the paper's optimal-count curve is the model-side version of that same wall.
https://t.co/0eTN4O8WOD
The key failure mode here is 'context truncation' in human review, where you start missing subtle errors once you hit more than a handful of agent interactions.
@Dan_Jeffries1 openjarvis runs the whole pipeline on ollama.
speech, vision, tool calls. no API key, no data leaves the device. perplexity's demo keeps sensitive ops local but still phones home for scale. that's the boundary to watch.
https://t.co/gMZGquUAHy
@scaling01 30T tokens at 1T@35B is serious capital.
Microsoft waited until the MoE recipe was proven, then outspent everyone on the first try.
https://t.co/GPY0pWjUWk