David AI has raised a $50M Series B from Meritech and NVIDIA to establish the data layer for audio AI.
Audio is the front-end interface for real-world AI. At David AI, we’re creating the data that powers the models bringing these use cases to life.
https://t.co/mbRg1YwGng
We are releasing MMS Zero-shot: a model to transcribe the speech of almost any language using only a small amount of unlabeled text in the new language.
Paper: https://t.co/aRoLtZSkpP
Demo: https://t.co/tFwhwTZpWO
Code/model: https://t.co/IxC8b7A9Ah
@JeffDean for the Gemini FLEURS results, why didn't you compare to MMS, the SOTA on FLEURS. What are the 62 languages you are evaluating on? Not disclosing them prevents others from comparing to Gemini. Also, the reference for Multilingual Librispeech should be Pratap et al.
Our founding team is covering many AI fields from vision, with Patrick Pérez and Hervé Jégou (@hjegou) to LLMs with Edouard Grave (@EXGRV), audio with Neil Zeghidour (@neilzegh) and Alexandre Défossez (@honualx) and infra with Laurent Mazaré (@lmazare).
We are publicly releasing all data and code, and are hosting a machine learning competition! Can you do better than us at translating neural activity into text? 2/3 https://t.co/aKrvvtVRv1
🤗 Transformers just got 1100+ new TTS checkpoints 🚀
You can now run any of @MetaAI's MMS TTS checkpoints using the Transformers library in 3 lines of code⚡️
MMS is a the largest democratizer of TTS globally to date 🌎
Try it in your language now: https://t.co/JcrylGZrKm
Excited to be at ICML 2023 where we will present our work on data2vec 2.0 on Wednesday (talk) and Thursday (poster): https://t.co/N0n2zDKLN7
@alexei_baevski@arunbabu1234@mhnt1580
Meta AI's recently released "Massively Multilingual Speech" (MMS) model is a huge step forward towards democratizing
Speech to every corner of the globe. In addition, it might also play a significant role in preserving global linguistic diversity.
https://t.co/5lQZn2nLq6
👇
@bnjmn_marie Whisper results in Table 5 are for completeness and we made it clear that the results are not comparable. But even if somebody ignores this: why would anyone think what you claim in the made up quote below from your blog post? The Whisper error is lower than MMS' in our table.
@bnjmn_marie For the MLS benchmark, the MMS paper makes no claims about MMS compared to Whisper.
Since Whisper introduced this normalization, we have a separate comparison just for this in Table 3. There we apply the same normalization and make claims about performance differences.
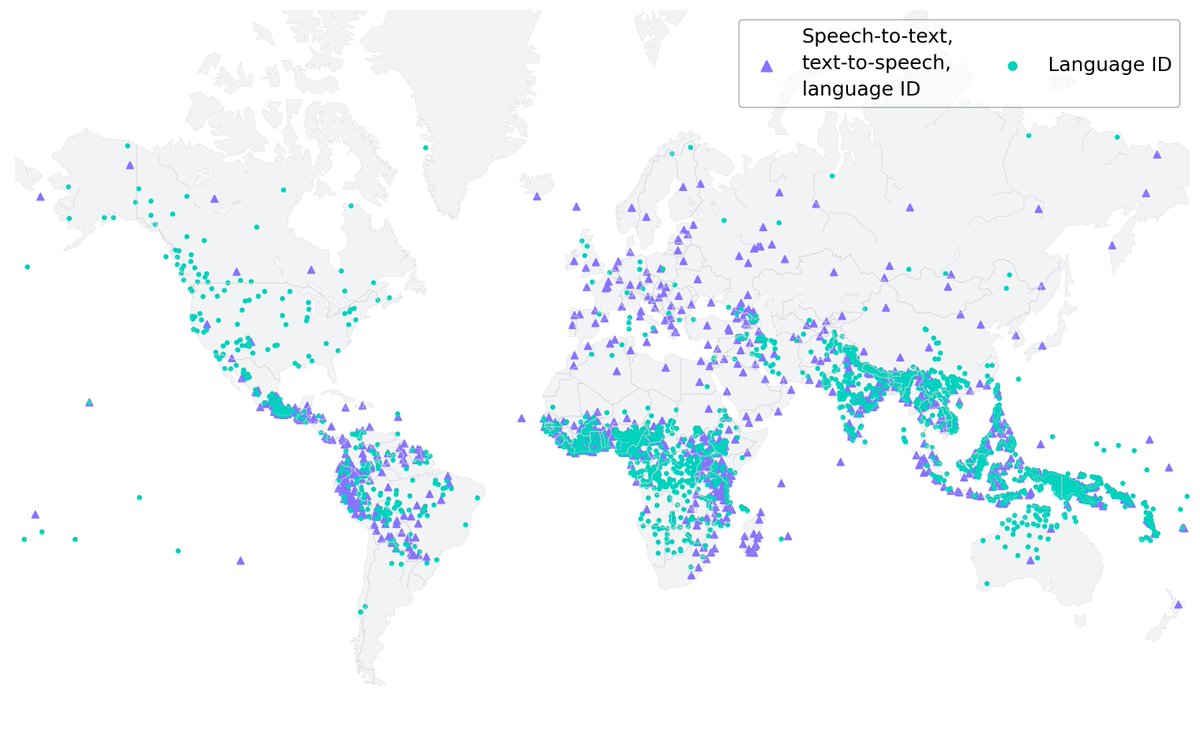
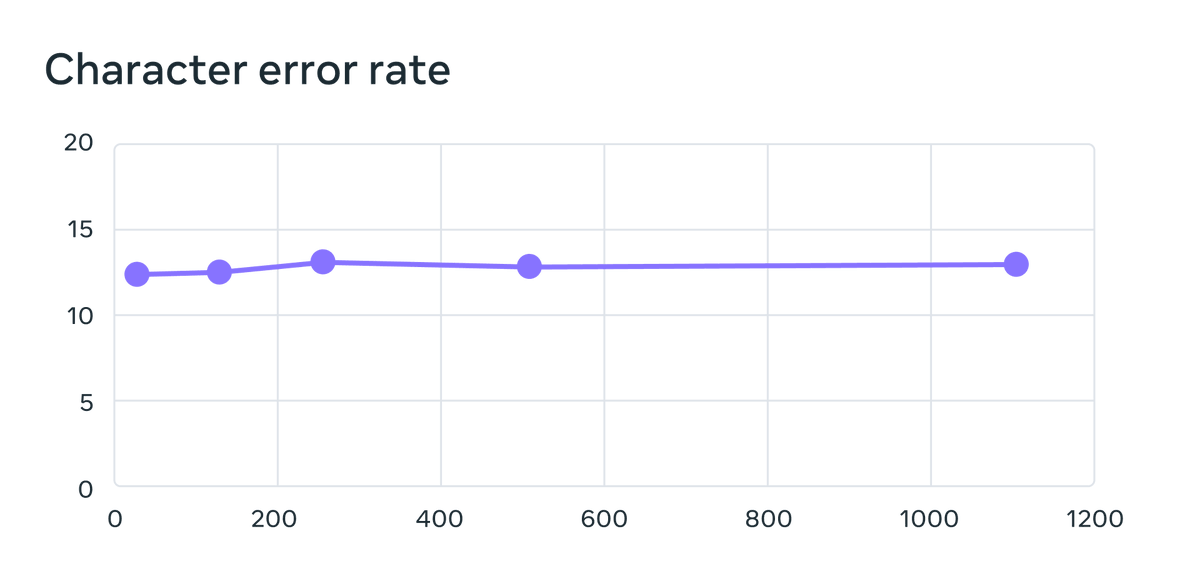
We also find that scaling multilingual ASR to this many languages only results in a very small performance degradation of 0.4 character error rate while increasing the number of supported languages by 18x (61 -> 1,107)
New work! The Massively Multilingual Speech (MMS) project scales speech technology to 1,100-4,000 languages using self-supervised learning with wav2vec 2.0.
Paper: https://t.co/C4Uhk4Q4m5
Blog: https://t.co/XXBQFcj086
Code/models: https://t.co/6mOhKPXy1X
Compared to OpenAI Whisper, the multilingual ASR model supports 11x more languages but has less than half the average error rate on 54 languages of FLEURS. The model is also trained on a fraction of the labeled data (45K vs. 680K hours).