$IREN's 𝗤1 𝗰𝗮𝗹𝗹 𝗶𝘀 𝗯𝗮𝘀𝗶𝗰𝗮𝗹𝗹𝘆 𝗮 𝗺𝗮𝘀𝘁𝗲𝗿𝗰𝗹𝗮𝘀𝘀 𝗶𝗻 𝗵𝗼𝘄 𝘁𝗵𝗲𝘆 𝘁𝗵𝗶𝗻𝗸 𝗮𝗯𝗼𝘂𝘁 𝘁𝗵𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀 – 𝗮𝗻𝗱 𝘁𝗵𝗲 𝗸𝗲𝘆 𝗶𝘀 𝘁𝗵𝗶𝘀:
👉 𝗖𝗼𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗮 𝘁𝗼𝗼𝗹 𝘁𝗼 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝘆𝗼𝘂𝗿 𝗼𝘄𝗻 𝗱𝗲𝘀𝘁𝗶𝗻𝘆. 𝗔𝗜 𝗖𝗹𝗼𝘂𝗱 𝗶𝘀 𝘁𝗵𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀.
1⃣ P𝗮𝗿𝘁 1 – 𝗖𝗼𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗮 𝘁𝗼𝗼𝗹 𝘁𝗼 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝘆𝗼𝘂𝗿 𝗼𝘄𝗻 𝗱𝗲𝘀𝘁𝗶𝗻𝘆
To see why, roll the tape back to 2017 👇
2017: 𝗧𝗵𝗲 𝗥𝗼𝗯𝗲𝗿𝘁𝘀 𝗯𝗿𝗼𝘁𝗵𝗲𝗿𝘀 𝘀𝗸𝗲𝘁𝗰𝗵 𝘁𝗵𝗲 𝗳𝘂𝘁𝘂𝗿𝗲 🚀
𝘍𝘪𝘤𝘵𝘪𝘰𝘯𝘢𝘭𝘪𝘻𝘦𝘥, 𝘣𝘶𝘵 𝘷𝘦𝘳𝘺 𝘮𝘶𝘤𝘩 𝘪𝘯 𝘭𝘪𝘯𝘦 𝘸𝘪𝘵𝘩 𝘵𝘩𝘦 𝘭𝘰𝘨𝘪𝘤 𝘵𝘩𝘦𝘺’𝘳𝘦 𝘳𝘶𝘯𝘯𝘪𝘯𝘨 𝘸𝘪𝘵𝘩 𝘵𝘰𝘥𝘢𝘺…
-𝗗𝗮𝗻: We don’t know which buzzword wins — AI, Bitcoin, quantum, some fancy optimization algorithms — but we do know one thing: everything is getting digitized.
-𝗪𝗶𝗹𝗹: Yeah. More software, more models, more background processes nobody understands chewing cycles in every industry.
-𝗗𝗮𝗻: Strip away the hype and there’s a simple conclusion: the world is going to need a lot more compute. And probably compute that’s way more complex and power-hungry than today.
-𝗪𝗶𝗹𝗹: So the thesis is clear: demand for compute is going to explode. We don’t have to guess the winner, we just need to be the guys who can deliver it.
-𝗗𝗮𝗻: Right. And to sell compute at scale, you need two things we can’t fake: 𝗽𝗼𝘄𝗲𝗿 and 𝗱𝗮𝘁𝗮 𝗰𝗲𝗻𝘁𝗲𝗿𝘀. Then we can stack anything on top — GPUs, ASICs, maybe quantum rigs one day.
-𝗪𝗶𝗹𝗹: Problem is, data centers look… boring. They’re basically REITs. Heavy capex, long contracts, what, 7–8% 𝘆𝗶𝗲𝗹𝗱 𝗼𝗻 𝗰𝗼𝘀𝘁 if we’re lucky?
-𝗗𝗮𝗻: On their own, yeah. Nice and stable, but kind of bond-like. Not exactly “let’s change the world” returns.
-𝗪𝗶𝗹𝗹: So why don’t we just rent? Let other people do the concrete and transformers, and we just focus on running compute and selling cloud.
-Dan: because if power and data centers are the bottleneck, the landlord controls our future.If we want 200MW and they can’t or won’t build it on our timeline, we’re dead in the water.
-𝗪𝗶𝗹𝗹: They’ll have other customers. Bigger ones. We could end up at the back of the queue.
-𝗗𝗮𝗻: Exactly. Then add this: if we don’t own the sites, we don’t really control 𝘁𝗶𝗺𝗶𝗻𝗴, 𝗰𝗼𝘀𝘁, 𝗼𝗿 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲.Power reprices? Construction blows out? Cooling isn’t dense enough for the next GPU generation? All of that just lands on us.
-𝗪𝗶𝗹𝗹: So even if we love being “asset-light”, we’re actually hostage to other people’s capex decisions.
-𝗗𝗮𝗻: And that’s the opposite of what we want. If we’re serious about this, we need to 𝗰𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝘂𝗿 𝗼𝘄𝗻 𝗱𝗲𝘀𝘁𝗶𝗻𝘆. That means owning the dirt, the substations, the shells — even if the yields look boring on paper.
-𝗪𝗶𝗹𝗹: So we accept that the data-center layer earns 7–8% like a bond, and the real upside comes from the 𝗰𝗼𝗺𝗽𝘂𝘁𝗲 𝗮𝗻𝗱 𝗰𝗹𝗼𝘂𝗱 we put on top of it.
𝗗𝗮𝗻: Exactly. Colocation is not the dream. It’s the 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝘁𝗮𝘅 we pay so that nobody else can tell us “no” when we want to scale.
-𝗪𝗶𝗹𝗹: Alright then. Let’s make it simple:We want to control our own destiny? We start buying land and power now, before everyone else wakes up. And if we’re doing this, let’s 𝗽𝗿𝗼𝗰𝗲𝗲𝗱 𝘄𝗶𝘁𝗵 𝗽𝘂𝗿𝗽𝗼𝘀𝗲 — we’re not here to fuck spiders.
𝗗𝗮𝗻: Sold.
📈𝗙𝗮𝘀𝘁-𝗳𝗼𝗿𝘄𝗮𝗿𝗱 𝘁𝗼 𝗤1: 𝘁𝗵𝗲 𝗰𝗮𝗹𝗹 𝗰𝗼𝗻𝗳𝗶𝗿𝗺𝘀 𝘁𝗵𝗲 𝗽𝗹𝗮𝘆𝗯𝗼𝗼𝗸
Jump to the 𝗤1 𝗙𝗬26 call and that 2017 mindset is basically written into the transcript.
Dan and Anthony don’t just vaguely talk about “vertical integration”. They literally 𝗰𝗮𝗿𝘃𝗲 𝘁𝗵𝗲 𝗰𝗼𝗺𝗽𝗮𝗻𝘆 𝗶𝗻𝘁𝗼 𝘁𝘄𝗼 𝗹𝗮𝘆𝗲𝗿𝘀:
• A 𝗱𝗮𝘁𝗮 𝗰𝗲𝗻𝘁𝗲𝗿 / 𝗰𝗼𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻 layer
• An 𝗔𝗜 𝗖𝗹𝗼𝘂𝗱 layer
Anthony explains that when they analyze deals like Microsoft, they 𝘀𝗲𝗽𝗮𝗿𝗮𝘁𝗲 𝘁𝗵𝗲 𝘀𝗲𝗴𝗺𝗲𝗻𝘁𝘀 𝗮𝗻𝗱 𝘁𝗿𝗲𝗮𝘁 𝘁𝗵𝗲𝗺 𝗮𝘀 𝘀𝘁𝗮𝗻𝗱𝗮𝗹𝗼𝗻𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀𝗲𝘀. In his words, they’ve “clearly divided out the business segments into standalone operations for the purposes of assessing risk return.
• The DC charges the cloud side an internal, arm’s-length $130 𝗽𝗲𝗿 𝗸𝗪 𝗽𝗲𝗿 𝗺𝗼𝗻𝘁𝗵.
• On 200𝗠𝗪, that’s roughly $312𝗺 𝗽𝗲𝗿 𝘆𝗲𝗮𝗿 in internal data-center revenue.
That’s the “𝗿𝗲𝗻𝘁” the AI Cloud business pays just to sit on IREN’s own dirt and electrons.
When you back-solve the math, that internal DC rent works out to roughly a 7–8% 𝘆𝗶𝗲𝗹𝗱 𝗼𝗻 𝗰𝗼𝘀𝘁 for the data-center asset. And Dan is pretty blunt about what that means on the call:
• At 7–8% 𝘆𝗶𝗲𝗹𝗱 𝗼𝗻 𝗰𝗼𝘀𝘁, even over a 15-𝘆𝗲𝗮𝗿 contract, you 𝘀𝘁𝗿𝘂𝗴𝗴𝗹𝗲 𝘁𝗼 𝗴𝗲𝘁 𝘆𝗼𝘂𝗿 𝗲𝗾𝘂𝗶𝘁𝘆 𝗯𝗮𝗰𝗸 just off those cash flows.
• You’re basically relying on 𝗿𝗲-𝗰𝗼𝗻𝘁𝗿𝗮𝗰𝘁𝗶𝗻𝗴 𝗮𝗳𝘁𝗲𝗿 𝘆𝗲𝗮𝗿 15 to earn any meaningful equity return.
In plain language:
--𝗣𝘂𝗿𝗲 𝗰𝗼𝗹𝗼𝗰𝗮𝘁𝗶𝗼𝗻 𝗶𝘀 𝗮 𝗯𝗼𝗻𝗱. 𝗦𝘁𝗮𝗯𝗹𝗲, 𝗻𝗲𝗰𝗲𝘀𝘀𝗮𝗿𝘆, 𝗯𝘂𝘁 𝗻𝗼𝘁 𝗵𝗼𝘄 𝘆𝗼𝘂 𝗰𝗼𝗺𝗽𝗼𝘂𝗻𝗱 𝗲𝗾𝘂𝗶𝘁𝘆 𝗶𝗻 𝗮 𝗯𝗶𝗴 𝘄𝗮𝘆.--
So why own it?
Because it gives them exactly what they were arguing about in that 2017 conversation:
• 𝗖𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝗳 𝗰𝗮𝗽𝗮𝗰𝗶𝘁𝘆 – if they want another 100MW, they don’t have to beg a landlord.
• 𝗖𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝗳 𝘁𝗶𝗺𝗶𝗻𝗴 – they can phase construction ahead of demand instead of chasing it.
• 𝗖𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝗳 𝗰𝗼𝘀𝘁 – they know the real $/MW because it’s 𝘵𝘩𝘦𝘪𝘳 capex and 𝘵𝘩𝘦𝘪𝘳 power deals; the $130/kW/month is an internal rent, not a mystery from a third party.
• 𝗖𝗼𝗻𝘁𝗿𝗼𝗹 𝗼𝗳 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 – they can design for dense AI workloads, not generic colo specs.
• 𝗠𝗮𝘀𝘀𝗶𝘃𝗲 𝗼𝗽𝘁𝗶𝗼𝗻 𝘃𝗮𝗹𝘂𝗲 – the same campuses can host GPUs for AI, ASICs for Bitcoin, or whatever the next compute-hungry workload turns out to be.
The Q1 call is basically the Roberts brothers saying, with numbers instead of whiteboard scribbles:
• The 𝗱𝗮𝘁𝗮-𝗰𝗲𝗻𝘁𝗲𝗿 𝗹𝗮𝘆𝗲𝗿 is a modest, market-rate utility asset that earns something like a 7–8% yield on cost.
• The 𝗔𝗜 𝗖𝗹𝗼𝘂𝗱 𝗹𝗮𝘆𝗲𝗿 𝘢𝘣𝘰𝘷𝘦 that internal $130/kW/month charge is where they target the serious IRRs and returns for us as shareholders.
Colocation is the the lever to control your destiny, 𝗔𝗜 𝗖𝗹𝗼𝘂𝗱 𝗶𝘀 𝘁𝗵𝗲 𝗯𝘂𝘀𝗶𝗻𝗲𝘀𝘀.
Before I go further, I really want to point you to a 𝗺𝘂𝘀𝘁-𝗿𝗲𝗮𝗱 𝗽𝗶𝗲𝗰𝗲 on this topic.
@brianfry01 recently shared a brilliant article by @franklee6924T called “𝗧𝗵𝗲 𝗧𝗿𝗮𝗽 𝗼𝗳 𝘁𝗵𝗲 𝗔𝘀𝘀𝗲𝘁-𝗟𝗶𝗴𝗵𝘁 𝗠𝗼𝗱𝗲𝗹.” I’m not going to retell the whole thing here because anything I write will be a downgrade , you should really 𝗴𝗼 𝗿𝗲𝗮𝗱 𝘁𝗵𝗲 𝗼𝗿𝗶𝗴𝗶𝗻𝗮𝗹, 𝗴𝗶𝘃𝗲 𝗶𝘁 𝗮 𝗹𝗶𝗸𝗲, 𝗮𝗻𝗱 𝗳𝗼𝗹𝗹𝗼𝘄 𝗯𝗼𝘁𝗵 𝗼𝗳 𝘁𝗵𝗲𝗺.
Link: https://t.co/DGFHyIa8zm
Very roughly, the article makes three big points:
• In truly 𝗮𝘀𝘀𝗲𝘁-𝗵𝗲𝗮𝘃𝘆 𝗶𝗻𝗱𝘂𝘀𝘁𝗿𝗶𝗲𝘀, going “asset-light” too early can be a 𝘁𝗿𝗮𝗽, not a shortcut.
• You earn the right to be asset-light 𝗮𝗳𝘁𝗲𝗿 you’ve built real capabilities, moats, and scale — not instead of doing that work. Exactly like hyperscalers did it.
• In “New Cloud”, the real moats are 𝗱𝗮𝘁𝗮-𝗰𝗲𝗻𝘁𝗲𝗿 𝗱𝗲𝘀𝗶𝗴𝗻/𝗼𝗽𝗲𝗿𝗮𝘁𝗶𝗼𝗻𝘀 and 𝘀𝗰𝗮𝗹𝗲, not just GPUs or software.
That framework fits IREN almost perfectly and 𝘁𝗵𝗶𝘀 𝘁𝗲𝗮𝘀𝗲𝗿 𝗶𝘀 𝗻𝗼𝘁 𝗮 𝘀𝘂𝗯𝘀𝘁𝗶𝘁𝘂𝘁𝗲 — the article by @franklee6924T is what you need to read.
2⃣𝗣𝗮𝗿𝘁 2 – 𝗧𝗵𝗲 𝗔𝗜 𝗖𝗹𝗼𝘂𝗱 𝗜𝗥𝗥 𝘀𝘁𝗮𝗰𝗸 (𝗮 𝘀𝗵𝗮𝗿𝗲𝗵𝗼𝗹𝗱𝗲𝗿’𝘀 𝘃𝗶𝗲𝘄) 💰
In the screenshot below i reverse-engineered how IREN is thinking about the Microsoft deal.
The top bit of the sheet – the “𝘂𝗻𝗹𝗲𝘃𝗲𝗿𝗲𝗱” 𝗽𝗿𝗼𝗷𝗲𝗰𝘁 – is really just a 𝗳𝗶𝗰𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝗽𝗿𝗲𝘀𝗲𝗻𝘁𝗮𝘁𝗶𝗼𝗻. It shows how they probably built the low-teens and high-teens IRRs they mention on the call: assume you pay yourself full colo rent, fund the whole $5.8B GPU bill with cash, and maybe give the GPUs some residual value at the end.
Useful to see the logic, but it’s 𝘯𝘰𝘵 how the real Microsoft deal is financed, so I don’t dwell on it.
The interesting part is the lower half of the sheet, where we 𝘀𝘄𝗶𝘁𝗰𝗵 𝘁𝗼 𝘁𝗵𝗲 𝘀𝗵𝗮𝗿𝗲𝗵𝗼𝗹𝗱𝗲𝗿 𝗹𝗲𝗻𝘀:
𝘏𝘰𝘸 𝘮𝘶𝘤𝘩 𝘰𝘧 𝘰𝘶𝘳 𝘮𝘰𝘯𝘦𝘺 𝘨𝘰𝘦𝘴 𝘪𝘯,𝘢𝘯𝘥 𝘩𝘰𝘸 𝘮𝘶𝘤𝘩 𝘤𝘢𝘴𝘩 𝘥𝘰 𝘸𝘦 𝘨𝘦𝘵 𝘣𝘢𝘤𝘬 𝘰𝘷𝘦𝘳 𝘧𝘪𝘷𝘦 𝘺𝘦𝘢𝘳𝘴?
𝗧𝗵𝗲 𝗳𝗼𝘂𝗿 𝗹𝗲𝘃𝗲𝗿𝗲𝗱 𝘀𝗰𝗲𝗻𝗮𝗿𝗶𝗼𝘀 𝗶𝗻 𝘁𝗵𝗲 𝘀𝗵𝗲𝗲𝘁 🧮
Once you include Microsoft’s 20% prepayment and GPU debt, you get four real cases:
• 𝗗𝗲𝗯𝘁 1: $2.5B on the GPUs
• 𝗗𝗲𝗯𝘁 2: $3.0B on the GPUs
…and for each of those, you can either assume the GPUs are worth 0% or 20% at the end of year 5.
From the model, the numbers boil down to this (all in USD billions, rounded):
A few things to notice:
• In the 2.5𝗕 / 0% 𝗿𝗲𝘀𝗶𝗱𝘂𝗮𝗹 case, IREN writes a $1.36𝗕 equity cheque and ends up with $2.70𝗕 of cash back over the https://t.co/fksDqopOsc profit: $1.34𝗕 – IRR about 28%, which matches the “25–30%” commentary on the call.
• With 2.5𝗕 𝗱𝗲𝗯𝘁 𝗮𝗻𝗱 20% 𝗚𝗣𝗨 𝗿𝗲𝘀𝗶𝗱𝘂𝗮𝗹, the same $1.36B of equity turns into $3.86𝗕 of cash https://t.co/JlZUlR0X3s profit: $2.50𝗕 – IRR roughly 38%, in the “35–50%” band Dan and Anthony keep pointing to.
• The 3.0𝗕 𝗱𝗲𝗯𝘁 versions are the more aggressive capital-structure cases:Equity shrinks to $0.86𝗕. Even if the GPUs go to zero, that buys you $2.00𝗕 of cash back (net $1.14𝗕, IRR mid-30s).If the GPUs retain 20% 𝘃𝗮𝗹𝘂𝗲, the same $0.86B of equity pulls out $3.16𝗕 of cash (net $2.30𝗕, IRR just under 50%).
That’s why management sounds so excited about AI Cloud on the call: once you 𝗽𝗮𝘆 𝘆𝗼𝘂𝗿𝘀𝗲𝗹𝗳 𝗰𝗼𝗹𝗼 and 𝘂𝘀𝗲 𝘀𝗲𝗻𝘀𝗶𝗯𝗹𝗲 𝗽𝗿𝗼𝗷𝗲𝗰𝘁 𝗱𝗲𝗯𝘁, a sub-$1–1.5B equity cheque into a Microsoft-size block can realistically spin off $2–3.8𝗕 of cash.
𝗔 𝗾𝘂𝗶𝗰𝗸 "𝗳𝗲𝗲𝗹" 𝗲𝘅𝗮𝗺𝗽𝗹𝗲 🤏
If the 3.0𝗕 𝗱𝗲𝗯𝘁 / 20% 𝗿𝗲𝘀𝗶𝗱𝘂𝗮𝗹 case turns:
• $0.86𝗕 of equity → $3.16𝗕 of cash back,
then very roughly, $2𝗕 of equity into deals on similar terms could mean something on the order of $7𝗕+ 𝗼𝗳 𝗰𝗮𝘀𝗵 𝗯𝗮𝗰𝗸 over a five-year window.
That’s the economic engine the Q1 call is trying to showcase.
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗺𝗮𝘁𝘁𝗲𝗿𝘀 🧱
The punchline management is really pushing is:
"𝘞𝘦 𝘥𝘰𝘯’𝘵 𝘯𝘦𝘦𝘥 𝘵𝘩𝘢𝘵 𝘮𝘶𝘤𝘩 𝘦𝘲𝘶𝘪𝘵𝘺 𝘧𝘳𝘰𝘮 𝘴𝘩𝘢𝘳𝘦𝘩𝘰𝘭𝘥𝘦𝘳𝘴 𝘵𝘰 𝘨𝘦𝘯𝘦𝘳𝘢𝘵𝘦 𝘷𝘦𝘳𝘺 𝘢𝘵𝘵𝘳𝘢𝘤𝘵𝘪𝘷𝘦 𝘳𝘦𝘵𝘶𝘳𝘯𝘴."
If IREN had taken this Microsoft deal and simply 𝗿𝗲𝗻𝘁𝗲𝗱 𝗮 200𝗠𝗪 𝗱𝗮𝘁𝗮 𝗰𝗲𝗻𝘁𝗲𝗿 𝗳𝗿𝗼𝗺 𝘀𝗼𝗺𝗲𝗼𝗻𝗲 𝗹𝗶𝗸𝗲 𝗖𝘆𝗽𝗵𝗲𝗿 at $130/kW/month, everyone would see that this is an amazing return.
Instead, they’re saying: We’ll 𝘂𝘀𝗲 𝗼𝘂𝗿 𝗼𝘄𝗻 𝗱𝗮𝘁𝗮 𝗰𝗲𝗻𝘁𝗲𝗿𝘀 and because they control the whole stack – land, power, substations, shells – they can scale into these contracts at a speed a pure renter simply can’t.
A few months ago, IREN’s AI revenue was around $2𝗠 𝗽𝗲𝗿 𝗺𝗼𝗻𝘁𝗵. Now they’re guiding roughly $3.4𝗕 𝗽𝗲𝗿 𝘆𝗲𝗮𝗿. That’s about $280𝗠 𝗽𝗲𝗿 𝗺𝗼𝗻𝘁𝗵. A 140𝗫 𝗶𝗻𝗰𝗿𝗲𝗮𝘀𝗲 𝗶𝗻 18 𝗺𝗼𝗻𝘁𝗵𝘀!
That’s what “𝘤𝘰𝘯𝘵𝘳𝘰𝘭 𝘺𝘰𝘶𝘳 𝘰𝘸𝘯 𝘥𝘦𝘴𝘵𝘪𝘯𝘺” looks like in practice. And they’re very clearly signalling: they’re not done yet.
IREN has announced a planned 800MW data center campus in Bundey, South Australia.
This marks IREN’s first announced Australian data center project and one of the largest in the Asia-Pacific region announced to date.
Learn more: https://t.co/3bOYCUG3pk
IREN use many definitions of ARR in their statements. Written ones are usually accompagnied by a footnote. You can really both be right depending on the context to be honest. They have "ARR under contract" / ARR / ...
Non written it is even more confusing. They should be more consistent in the material they put out. They have talked about contracted --> Operational --> 1 month burn in periode --> generating revenue.
I personally look at the screenshot above = 225m in AI Cloud ARR, expected to be in operation by the end of 2025.
For Q1 2026 you would expect at the very least 225m / 4 quarters = 56.25M AI cloud revenue in Q1. This would be in line with their guidance.
For Q2 2026 you would expect 500m ARR / 4 quarters or 125m AI cloud revenue would be in line with their guidance.
In reality Q1 2026 should be more since they are getting the GPU's online to hit 500M ARR operational by the end of march. But how much over the 56.25M is debatable and not really specified by $IREN.
With @NVIDIAGTC behind us, Looking back at this space from 2 weeks ago with @IREN_Ltd co-CEO @danroberts0101 — I'm looking forward to our next set of spaces with industry guest speakers.
What say you @vipulved, @the_bunny_chen, @lqiao ? 👀
Let's talk about
autonomous intelligence,
application agentic space,
throughput x tokenspeed, and
AI infrastructure optimized for inference workloads
Join me?
@Gyujin_9701 @jiahanjimliu@FransBakker9812 Pue of 1.1 is not possible for air cooled in Texas. Bitcoin mining is already higher now. Should account for > 1.2 pue.
$IREN is pleased to announce it will be added to the MSCI USA Index, effective after close of trading on February 27, 2026.
The MSCI USA Index measures the performance of large and mid cap segments of the U.S. equity market and represents approximately 85% of the free float-adjusted market capitalization in the US.
Press Release: https://t.co/YjBIoBOMaL
This is a good list of things to keep track of. I am not counting on any disclosures higher than guided ARR. If it happens it might just be when reporting their Financials for Q2 2026.
You keep good track of the development of the company. Probably the best of any bears I have seen.
Are you keeping track of it to time your next short? Is your trading strategy built around shorting or is this just something you decided to take an opportunity on?
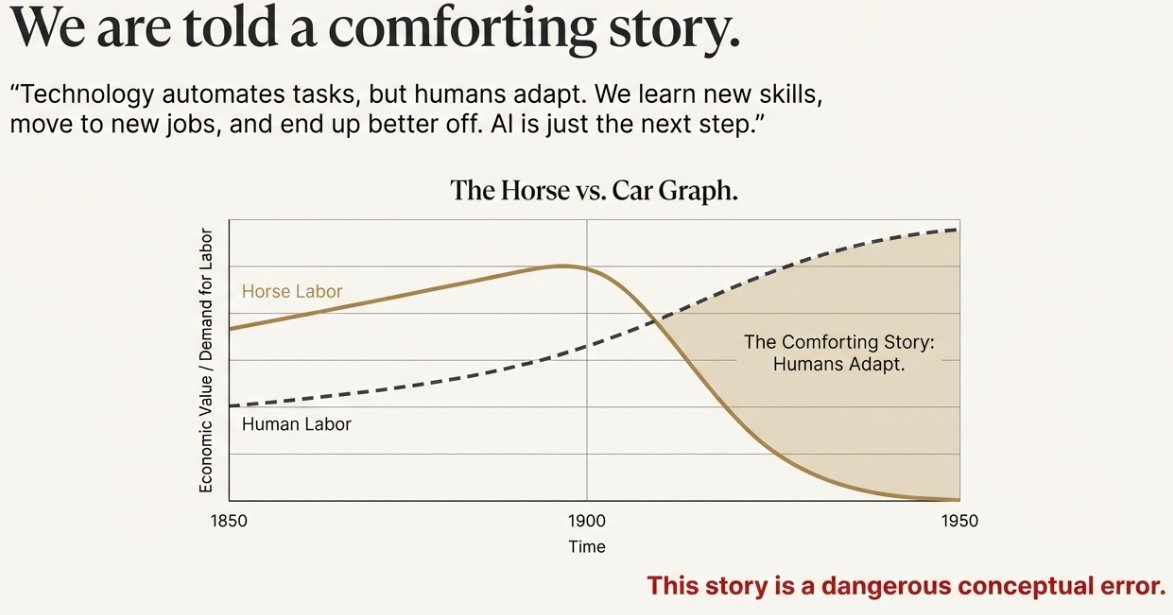
The Framework That Breaks the “AI Is Just a Tool” Story
🧠Why the horse-vs-car analogy fails — and why AI is a second engine inside the loop of civilization
Whenever people worry about AI, the same reassurances show up.
We get charts of productivity over time. We hear about the steam engine, electricity, and the internet. We see the familiar “horse vs. car” story: horses were wiped out as engines arrived, but humans were fine because we learned to drive instead of pull. The moral is always the same: technology automates tasks, people adapt, the economy reorganizes, and human labor value continues rising in the long run.
It’s a comforting story. It’s also a dangerous conceptual error, not because it’s “false,” but because it focuses on the surface layer: jobs. If you want to understand what’s actually changing, you have to look deeper than jobs and ask a more fundamental question: what is the engine that creates new jobs in the first place?
That engine is a loop. And once you see it clearly, you’ll understand why steam engines were “safe,” why the horse analogy misleads, and why AI is the first real rival to the role humans have always played.
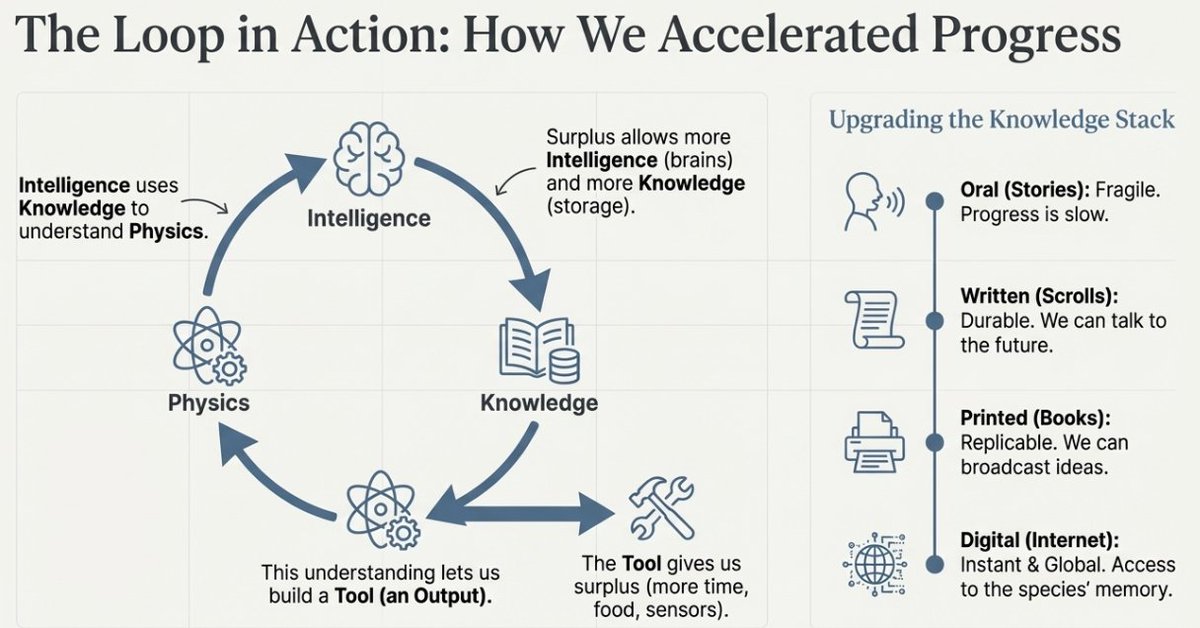
🔁 1. The Human Training Loop: Intelligence → Knowledge → Physics
Forget jobs and GDP for a moment. Ask the more basic question: how did humans go from stone tools and fire to rockets and smartphones?
Underneath all of history, progress is driven by a self-reinforcing loop made of three ingredients:
•🧠 Intelligence: the active agent — pattern recognition, reasoning, planning, and the ability to ask “what if?”
•📚 Knowledge: the memory — information stored outside any single brain so each generation doesn’t start from scratch.
•⚡ Physics: the landscape — the underlying laws of reality (thermodynamics, chemistry, electromagnetism, quantum mechanics) that can be exploited to produce tools.
The loop works like this: intelligence uses stored knowledge to understand and exploit physics. That understanding produces tools — not just gadgets, but leverage. Tools create surplus: more food, more time, better sensors, better communication. Surplus allows society to support more minds, educate them, connect them, and preserve more knowledge. Then the loop runs again — faster.
Almost everything we call “civilization” is just this loop spinning: fire, metallurgy, agriculture, engines, electricity, semiconductors, the internet. Each is a way of reaching into physics with intelligence, guided by knowledge, to generate new capability — and then using that capability to amplify intelligence and knowledge at scale.
1.1 How the Loop Accelerated: Oral → Digital
This loop has existed for tens of thousands of years, but its speed changed radically when we upgraded the Knowledge layer. The big breakthroughs in human progress aren’t only about new inventions, they’re about raising the bandwidth and durability of memory.
•🗣️ Oral: fragile knowledge. If the elder dies, the library burns down.
•✍️ Written: durable knowledge. We can talk to the future.
•📖 Printed: scalable knowledge. We can copy ideas across thousands of minds.
•💻 Digital: instant, global knowledge. A teenager can access a huge fraction of humanity’s stored memory.
This is why, biologically, our brains haven’t changed much in 50,000 years but our effective intelligence exploded. A baby born in a cave had nearly the same hardware as a baby born today. What changed is the operating environment: nutrition, medicine, education, tools, and above all the network. We built a world where billions of brains can be supported and connected, and where knowledge can be stored, searched, transmitted, and recombined at unprecedented speed.
In that sense, the “Human Training Loop” is not just individual intelligence. It’s a species-level system: billions of biological nodes connected by culture and technology, feeding on accumulated knowledge to better exploit physics, producing tools that expand both intelligence and knowledge again.
That loop is the engine of civilization.
🚂 2. The Old Invariant: Why the Steam Engine Was Safe
Now we can return to the steam engine — and see why the classic analogy misses the deeper structure.
Steam engines were massively disruptive. They replaced muscle. They transformed transport, manufacturing, and warfare. But in the framework above, the steam engine is not an entity inside the loop. It is an output of the loop — a tool. It has no agency. It does not learn. It does not accumulate knowledge. It does not look at physics and redesign itself into a better engine.
It sits outside the loop until a human mind decides how to use it.
This is the key point that’s often invisible in the “horse vs. car” story: technologies like steam engines, tractors, power looms, computers — they reinforced and accelerated the Human Training Loop, but they did not replace it. They were leverage applied by the one thing in the system that could plan and adapt: human intelligence.
That’s why the historical pattern looked so resilient. When one niche vanished (weaving), other niches appeared (engineering, management, design). Not because the universe guarantees employment, but because the Human Training Loop remained the only mechanism capable of exploring new possibility space. Humans were still the only general intelligence on the planet — still the only thing inside the loop.
That invariant — humans are the only general-purpose intelligence — is the deepest reason labor kept “finding” new value. The driver of adaptation wasn’t the tool. It was the monopoly on agency.
🤖 3. The Break: AI Is Not a Tool. It Is a Second Engine Inside the Loop.
This is where the standard framework breaks.
Modern AI is not a tool in the same sense as a hammer, a spreadsheet, or a steam engine. Those tools increase the power of the human loop. AI is different because it begins to occupy the role of intelligence inside the loop itself.
Structurally, AI is the birth of a Second Training Cluster — a second engine. Instead of biological brains, it runs on GPU clusters and specialized chips. Instead of oral tradition and books, it is trained on massive digital datasets: text, code, images, logs, scientific papers. Instead of schooling and culture as its training mechanism, it uses training algorithms that compress patterns into weights, then uses inference to generate outputs.
In other words: it takes in knowledge, performs intelligence-like processing, and produces outputs that are valuable in the real world — text, code, designs, plans, decisions.
Right now, it is plugged into the human world: trained on human-produced data, hosted on human-built infrastructure, deployed inside human organizations. But the conceptual break is already here:
-- "For the first time in history, something does not merely come out of the loop as a tool — it begins to sit inside the loop as another engine of cognition." --
Today it behaves like a subsystem of the Human Training Loop: a module we call when we need help thinking. Tomorrow, as it gains more autonomy, better tooling, tighter feedback loops, and richer interfaces to the physical world, it may become a separate, self-improving loop — its own training engine that doesn’t merely accelerate the human loop, but competes with it.
We are not building a “better hammer.” We are building a second civilizational engine inside the same process that made us powerful.
⚖️ 4. Comparing the Two Engines: Humans vs. the AI Cluster
If there are now two engines running something like the same loop, the natural question is: where does the AI cluster already outperform the human cluster, and where does it still lag?
On Knowledge, the AI cluster effectively wins. It can index and recall enormous portions of human digital memory and retrieve it on demand. A human might know a domain deeply, but no individual can match that breadth — and more importantly, even the human species cannot match the speed at which an AI system can sweep, retrieve, and recombine what’s already been written. We “have” the corpus, but we access it through slow channels: reading, searching, remembering, coordinating. The AI cluster accesses and recombines at machine speed.
On Intelligence — reasoning and application — the shock is how quickly the gap closed. For a long time machines were brittle. Now AI systems can plan, summarize, write, code, draft legal arguments, analyze data, and solve structured problems at a level that matches or exceeds large portions of the workforce in many contexts. They are not Einstein or Newton, but they are already “good enough” across broad domains, and they do it faster, tirelessly, and at near-zero marginal cost once trained. This matters because economic displacement doesn’t require superintelligence. It requires “cheap competence at scale.”
On Physics and discovery, humans still lead — for now. The deepest breakthroughs still come from a small fraction of minds, and today AI is more assistant than originator at the frontier. But even here, AI is already reshaping the process: reading papers, exploring model space, proposing hypotheses, designing simulations, analyzing results. The frontier remains the last stronghold, but it is also the most likely place where a feedback loop could form: once AI begins to contribute meaningfully to novel discovery, the loop can, in principle, run end-to-end in silicon.
Crucially, AI does not need to fully “own” physics to reshape the economy. If it can apply existing knowledge faster and cheaper than humans across most cognitive work, then for most economic purposes it is already a better engine for that layer of activity.
🏹 5. The Trap: From the Indian Hunter to General Human Labor
This is where the “horse vs. car” analogy fails. It implies replacement through direct substitution: the car replaces the horse at the task of pulling. But the deeper risk with AI is not that a robot replaces you one-to-one. The deeper risk is that the economic system reorganizes around a different engine — and your skills become stranded.
A better analogy is the Indigenous hunter in North America around 1700.
Imagine a highly skilled hunter with deep intelligence about the land and rich knowledge of seasons, animal behavior, and terrain. When European traders arrive with rifles and steel traps, these are tools. They amplify his productivity. He hunts more effectively, trades more, and sees his standard of living rise. It feels like the comforting story: new tools, same human at the center, greater prosperity.
But then the system changes.
Agriculture, ranching, and industry arrive — not merely as new “jobs,” but as a new economic configuration that supports denser settlement, larger populations, more surplus, more specialization, more schooling, more infrastructure. In other words, agriculture and industry reinforce and accelerate the Human Training Loop far more than the fur trade ever could. From the perspective of the loop, the system selects for the regime that spins it faster.
The hunter is not replaced by a robot hunter. He is stranded by a change in what the economy optimizes for. Hunting remains a real skill. It’s simply no longer central to the new engine of growth.
And this is where the second loss appears: ownership. In that transition, the land is redefined, fenced, titled, taxed, and reassigned. The hunter loses not only the market for his way of creating value, but also the capital context — the “forest” — that anchored his role.
That is the Indian Hunter Trap: value can collapse via system re-optimization, not direct task substitution. With AI, this trap risks becoming general. The economy starts to reorganize around what the AI cluster does best: rapid, cheap, scalable cognition applied to existing knowledge. At first, humans using AI feel like the hunter with the rifle: “this makes me more productive.” Over time, if the second engine can run entire cognitive pipelines end-to-end — coding, analysis, design, planning, optimization — the system will need less human cognitive labor overall. Not because humans become stupid, but because the loop re-optimizes around the faster engine.
🌲 6. The New Forest: Ownership of the Second Engine
In the hunter story, the “forest” wasn’t just scenery. It was capital. It was context. It was the substrate that made the hunter’s intelligence economically legible.
In the AI story, the new forest is not soil and rivers. It’s the capital stack that runs the second engine:
• compute (data centers and chips),
• models (weights and architectures),
• proprietary datasets,
• energy and infrastructure contracts,
• and the legal frameworks governing deployment.
This is where the discussion shifts from “jobs” to something more fundamental: leverage.
In the 19th century, even if you lost your job, you still owned your brain — the only general intelligence in the world. You could retrain into a new niche because humans still monopolized the engine. In a world where the dominant engine of cognition is owned elsewhere, retraining is no longer the full answer. The question becomes: do you own any meaningful stake in the engine that replaced your labor?
If a narrow group owns the second engine and everyone else merely rents access, then the risk is not just a jobs crisis. It is a sovereignty crisis — a loss of leverage for the majority.
🗺️ 7. The Framework in One Glance
Here is the map:
Human progress runs on a loop: intelligence uses knowledge to exploit physics, producing tools that generate surplus, which expands both intelligence and knowledge. For all of history, humans monopolized the intelligence inside that loop. Every great technology — steam engines, electricity, computers — reinforced and accelerated the human loop but never replaced the human role as the sole engine.
AI changes that. It is the first thing that begins to occupy the intelligence function inside the loop. It already dominates knowledge access and is approaching parity on many forms of applied reasoning at scale, while still lagging at the deepest frontier of discovery. That’s enough to reorganize the economy, because displacement is driven by cheap competence, not perfect genius.
The Indian Hunter Trap is the warning label: value can collapse via system re-optimization, not direct task substitution. And ownership determines whether the transition produces broad prosperity or broad loss of leverage.
❓ 8. The Question This Essay Can’t Answer (But Helps You See)
This essay doesn’t tell you whether the future will be utopian, dystopian, or something stranger. It doesn’t prescribe the correct policies or predict which careers survive.
What it does offer is a map — a way to see AI not as a gadget or a trend, but as a second engine entering the same loop that made humans powerful in the first place. Once you see that, the right questions become unavoidable:
How do we live, organize, and find meaning in a world where humans are no longer the sole engine of intelligence, knowledge, and physics? And how do we share, govern, and constrain a second engine that could — if left unchecked — relegate most human intelligence to the margins?
This essay doesn’t answer those questions but it gives you the framework to see what the questions really are — and that is the starting point for any honest conversation about AI, humans, and what comes next.
$IREN closed just above $40 on Friday, which was the weekly OPEX max pain as well.
There are a number of things expected to happen that could help the stock regain momentum upwards.
Some of these have been mentioned before, but I thought it would be good to list them:
1. An announcement for the 450 MW of Horizon 5-10.
2. A customer and deal for the first phase of Sweetwater 1.
3. A handover from construction to ops for the $MSFT deal, ensuring availability and partially derisking the deal.
4. Sweetwater 1 transformers arriving on site.
5. Official ERCOT approval to energize with a firm date for Sweetwater 1.
6. 23k GPUs installed and pre-leased in BC, ensuring >$0.5B ARR.
7. An announcement with regards to the expansion of Prince George from 50 to 80 MW.
8. A construction update from Mackenzie, paired with an expansion upgrade to 100 MW.
9. The announcement of GPU debt financing for >$4B of the $MSFT contract GPUs, at mid-single digits interest (6-7%), leading to a fully funded status for the deal.
10. The acquisition of ~37k GPUs for the remainder of the BC MWs.
11. The announcement of a new development site with firm power and an expected in-service date.
12. The announcement of a strategic partnership with $MSFT to develop the Canadian power pipeline, with the blessing from the federal and provincial government, opening up the way to a new development site in BC.
13. Any other kind of partnership for AI cloud/compute, a supplier, and/or a financing partner.
14. An announcement with regards to M&A for anything related to software/PaaS.
15. Anything related to the APAC region.
16. The announcement of a new HQ in Dallas-Forth Worth.
There are probably a few more things they could surprise us with. Right now, we are about 5-6 weeks out from the next earnings, and we are at a pretty strong support level.
The net selling of the last months into the end of the year should subside, and hopefully conclude, next week.
I would like to direct this post in particular to people that have an average of more than $40, because I can understand you're waiting for the market to "get it", and pump some money into the stock.
Obviously I can't time that, so I'm currently trying to trade the volatility, while waiting for any of the above catalysts to play out.
For that reason, this post is not financial advice, but really a summary of what I am looking forward to in the coming months, even though some of them may not even happen.
I want to add something to this article.
People keep debating the $IREN × Microsoft deal in the same loop: “Are the margins high enough to justify the capex, the risk, the dilution?"
Recently there was a good discussion between @Agrippa_Inv and @Umbisam about this.
And I get why — it’s the first big, visible datapoint, so everyone tries to price the entire company through this one lens. But I think that framing misses what IREN has actually built here.
Let’s start with the object in front of us. IREN hasn’t built a “normal” data center. They’ve built a Tier 4 facility that will very likely target five-nines class uptime, and they built it specifically for Rubin-class requirements. It’s designed around 100MW-scale superclusters, with rack density that is not only extremely high, but scalable: roughly 130kW up to 200kW per rack. That combination—density and flexibility—at that scale is unseen. This is not just "hosting" some GPU it's cutting edge AI factory development.
Now zoom out and ask: why would anyone do this on Deal #1 just to maximize near-term margins on one contract? You wouldn’t. This is where I think the people keep tripping over. Yes, the capex is high. Yes, you can debate the multiples. Yes, you can argue the margins aren’t spectacular. Yes, you can call it “overbuilding” for one deal. All of those statements can be true at the same time and still this is a very good sign for shareholders.
The first build is expensive because it’s not just hosting for the Microsoft deal, but it’s also building the reference architecture: the commissioning playbook, the operational doctrine, the physical platform that can carry multiple GPU generations. It’s a build that sets IREN up to replicate a new standard.
It is not the perfect analogy but it gets point across. The Apple analogy. If you look at an early iPhone and complain the bill of materials is too high compared to a Nokia, you’re missing that Apple wasn’t trying to win the Nokia market — they were building the platform. The first iteration is expensive precisely because it creates the template that makes everything after cheaper, faster, and more scalable.
Here’s the bigger point: IREN is not building a few hundred megawatts and calling it a day. IREN is building toward multi-gigawatt scale — ultimately 9GW+ of data centers. And a company that genuinely expects to build that much capacity has a totally different incentive function than the average developer or asset-lite neo-cloud. If you have a 9GW pipeline and vertical integration you treat the early phase as R&D, then you turn what you learned into a factory line.
That cost-down phase doesn’t come first. It comes after you’ve earned the right to standardize — after you’ve built enough frontier systems to truly understand what next-generation AI data centers require. Only then can you meaningfully ask: how do we modularize this, how do we pre-engineer it, how do we compress timelines, how do we reduce $/MW, and how do we scale fast without breaking reliability?
And this is the part people keep missing. The usual debate assumes IREN should be trying to maximize one single thing right now — margin, ROIC, near-term optics.
I think they’re optimizing for the future, hyperscale long-term — just like they’ve done since the very beginning in 2018.
As a shareholder, I’m actually happy about that. If IREN had delivered a “nothing-special” facility that merely hosts gb300 I’d be disappointed, because that would be a sign they’re not thinking in platforms, they’re thinking in projects. Instead, they’re going to the cutting edge, delivering a new standard, and then using that R&D to compound: optimize, cut costs, and create savings in the builds that follow.
Of course, with one public datapoint, this is hard to “prove”. But if you step back and look at what they’re building — and the scale they’re aiming for — the intent is pretty clear.
Who Is Building High-End AI Smart Factories?(I)
2025 is the first true year of AI development—fast and intense, yet deeply chaotic. Never before has demand reached such unimaginable levels of commercial scale, and never before have the physical world and the virtual digital world been so disconnected and mismatched. This contradiction has no immediate solution. It resembles a raging forest fire met with rescue water that is utterly ineffective. As 2025 draws to a close, I would summarize this year’s AI industry with a single word: chaos.
The major contradictions currently facing the AI industry are:
1.Unlike the CPU era, the exponential growth in GPU compute density does not match the practical, physical growth constraints of data centers.
2.The exponential growth in compute demand is mismatched with the configuration and performance improvements of physical infrastructure; even exponential increases in GPU compute density cannot satisfy the growth in compute demand.
3.The “energy bottomless pit” of compute power is mismatched with—and in some cases directly conflicts with—global goals of “carbon neutrality / grid capacity.”
4.The “infinite marginal value” of AI applications conflicts with the “finite ROI (return on investment)” of the real world.
Further elaboration of these four core contradictions reveals that, between the digital virtual world and the physical real world; between power systems designed for civilian use and their excessive occupation by high-performance computing; and between early movers who believe AI is omnipotent and therefore worth aggressive, cost-insensitive investment, and professional investment institutions with rigid requirements for capital returns—there exist three major dimensions of conflict that are difficult to reconcile in the medium to long term.
The sharp decline in AI-related stocks over the past month has been primarily triggered by the third contradiction. No one is questioning the long-term prospects of AI. The real issue is how to do it in a way the physical world can accept. Once investment exceeds the tolerance of capital, severe volatility inevitably follows.
Among the contradictions outlined above, data centers are the industry with the highest degree of linkage. They are not merely infrastructure. Across the early, intermediate, and advanced stages of AI development, data centers will consistently play a critical role. This is because computational energy efficiency is not determined by GPUs alone. Data centers with different performance characteristics and different physical infrastructure configurations can exhibit enormous differences in realized compute efficiency.
Especially at the advanced stage of GPU cluster efficiency, the decisive factor is the technical capability of the data center that supports cluster operations. It can be said that, within the AI industry, data centers and traditional data centers are fundamentally different things—and data centers that serve large-scale and ultra–large-scale clusters are yet another category altogether. We may call them smart factories.
The exponential growth in GPU unit compute density has caused the developmental ambitions of the virtual digital world to collide head-on with the physical constraints of the real world. Under the Hopper architecture, traditional data centers could still function. Under the Blackwell architecture, however, the vast majority of GPU models require entirely new infrastructure standards, effectively excluding almost all existing traditional data centers worldwide.
Yes—starting with Blackwell, what is required is a new type of data center designed to match the development of the AI industry. Its entry-level requirements include:
1.120 kW high-density racks
2.Liquid-cooling thermal systems
3.High-load data center floors rated at ≥1.3 tons per rack
https://t.co/FpNWJhYWOA for NVLink / NVSwitch / PCIe 6.0 high-speed interconnects
5.High-density fiber and short-reach high-speed cabling capability
6.Overall infrastructure scalability and upgradability
As GPU performance continues to advance—for example, after the emergence of the Rubin architecture—the requirements for data centers will rise to an even higher level and should include:
1.200–300 kW per-rack ultra–high-density racks
2.Liquid cooling systems (DLC / immersion cooling)
3.Ultra–high-load floors rated at ≥1.8–2 tons per rack
4.Suppo
rt for NVLink 6 / NVSwitch 6 / PCIe 7.0–class high-speed interconnects
5.CPO (Co-Packaged Optics) and silicon photonics interconnect infrastructure
6.Rack-level AI Fabric support (low latency, ultra–high bandwidth)
7.High-density fiber trays and hybrid electro-optical cabling capability
8.Power and cooling redundancy re-architecture at the full–data-center level
9.Topology support for large-scale AI training clusters (ten-thousand-GPU class)
10. End-to-end energy efficiency optimization capability for 1–2 MW per row.
I cannot verify the precise accuracy of each of these parameters, but they clearly illustrate that the requirements for the overall supporting infrastructure are continuously rising.
In theory, such escalation could continue indefinitely. In reality, however, overall social resources and capital return requirements will not support it. Improvements in GPU efficiency will ultimately converge on an optimal curve balancing efficiency, cost, and performance. AI development, in turn, will seek its direction under the combined constraints of resources, energy consumption, and reasonable input–output ratios. At present, the path most likely to prevail on a comprehensive basis is GPU cluster scaling, which is also a necessary route toward AGI.
Whether the AI industry will fully move toward AGI, or remain on a trajectory of specialized intelligence combined with human–machine collaboration, remains uncertain. Many social and even ethical issues are still under debate. However, from a profit-maximization, commercially driven perspective, the probability is high that development will move toward AGI. I personally define AGI as an inorganic humanoid brain—a silicon-based, inorganic humanoid brain created by organic brains that evolved over millions of years in carbon-based life.
Returning to GPU clusters: their significance is not a simple arithmetic sum of GPU counts. Based purely on GPU physical performance, a clustered compute system can, in some cases, produce less output than the same number of GPUs operating independently and then aggregated. The true power of a cluster comes from socialized cooperation. All organisms capable of social cooperation are extraordinarily powerful—ants are a classic example. GPUs are no different. Once intelligent units form clusters that cooperate and communicate, they can unleash enormous power. This also vividly demonstrates the uniqueness of intelligence itself: a cluster composed of inorganic matter can exhibit social attributes. The larger the cluster, the stronger this capability becomes.
However, the larger the cluster, the greater the difficulty of managing it. Large and ultra–large clusters impose extremely high requirements on safety and stability. These cannot be achieved by software alone. The demands on physical hardware infrastructure become even higher. The logic is the same as with high-end computers and smartphones: many applications simply cannot run on low-spec devices.
From this perspective, debating whether a company’s development path is IaaS or PaaS at this stage is of limited significance. Before ultra–large-scale, AI campus–level infrastructure—power, land, fiber, cooling, scheduling, and reliability—is built, the PaaS layer remains too low-level and is, in essence, merely IaaS wrapped in a software layer.
Now we can turn to AI smart factories. I asked four different large language models to provide definitions and extracted the most consistent elements. The result can be summarized as follows:
An AI smart factory is a new generation of data center centered on ultra–large-scale accelerated computing. Through a complete software and systems stack, it converts power and data into intelligent output, undertakes both training and inference, and forms large-scale clusters via high-speed networks to enable the industrialized production of models, tokens, and intelligent services. It operates continuously on a 7×24×365 basis, transforming physical resources into digital intelligence (tokens) and becoming the core production facility of future enterprises. Scaleis its most fundamental characteristic.
AI smart factories also exist at foundational, intermediate, and advanced levels—they form a capability curve. The stronger the capabilities, the more complete the closed loop, the higher the intelligent output, and the greater the economic value. Compared with data centers that merely adapt to the exponential growth of GPU energy efficiency, AI smart factories represent an upgrade in both hardware infrastructure and overall operating systems. They are required to possess:
https://t.co/qBZLNcQE0D capability (Training)
2.Inference capability (Serving)
https://t.co/HBqY7XwE2n feedback capability (Feedback)
4.Model iteration capability (Continuous Learning)
5.Unified orchestration capability (Fabric-aware Scheduling)
6.Scalability (Scalability)
7.Reliability, security, and isolation (Enterprise-grade)
Explaining each of these technical terms in detail would be an enormous task. It is sufficient to understand the level of technological sophistication and requirements they represent. In simplified terms, the future AI data center landscape divides into two major tiers: those that provide compute power, and those that provide intelligence.
Let me repeat the key question: Are you providing compute power, or are you providing intelligence? Or are you somewhere in between?
Future data centers adapted to the AI industry can be broadly classified into several categories. The largest group consists primarily of facilities that provide high-density power and cooling infrastructure; their products are physical space and energy leasing. The second category builds on AI-compliant data centers by deploying bare-metal GPU clusters and directly offering raw compute leasing services to the market; their product is compute. The third category builds further on the second, focusing on intelligence processing and model management. These operators do not necessarily pursue extreme training capability, but they can provide enterprises with APIs, model fine-tuning, and full-scale inference services. They possess data feedback loop capability, rely on upstream models as foundational layers, and then productize and service these capabilities to deliver turnkey intelligent solutions downstream. The fourth category is the AI smart factory, the highest form. It achieves an industrialized closed loop of “energy input, intelligence (tokens) output,” integrating everything from ten-thousand-GPU–class cluster training and full lifecycle management to sovereign-grade security isolation.
The above organization of the industry’s development trajectory is the result of analyzing and interpreting massive volumes of information and has already been significantly distilled. Understanding this development path is critically important. Without a macro-level perspective, it is difficult to evaluate investments in related companies, identify where true advantages lie, or focus discussions on what actually matters. It should be noted that these are conceptual classifications that approximate the future. The ultimate outcome will still depend on real-world commercial execution, but the overall direction is unlikely to be wrong.
Based on the above, several points about the development of AI infrastructure and the AI industry can be stated with confidence:
· GPU and GPU cluster compute efficiency grows exponentially.
· Improvements in GPU efficiency will converge on an optimal curve balancing efficiency, cost, and performance.
· AI development will find its direction through the combined constraints of resources, energy consumption, and reasonable input–output ratios.
· AI smart factories represent the high-end form of the AI industry: they have high technical barriers, require massive investment, possess strong closed-loop capabilities, can industrialize the production of intelligence, apply across broad scenarios, and exhibit high value density. They are the highest-margin segment of the value chain.
· At every stage of development, data centers are indispensable—and the more advanced the stage, the more critical they become, with correspondingly higher barriers to entry.
Now I can classify the related stocks and examine who has the potential to evolve toward the highest form of the AI smart factory, and why.
First, we exclude companies that do not touch GPU computing at all, or have only just begun to do so, and that primarily focus on leasing or hosting their own infrastructure. These are mainly Bitcoin miners, with representative names including CIFR, WULF, HUT, APLD, GLXY, CORZ, and BITF.
The second group consists of what are commonly referred to as neo-cloud companies: CoreWeave, Nebius, IREN, as well as Crusoe and Lambda.
With the exception of Nebius and Lambda, all of the companies listed above share a common trait: they are, or once were, cryptocurrency miners. Moreover, with the exception of @IREN, they were largely unsuccessful—or not particularly successful—as crypto miners.
In the early years of the crypto mining boom, dozens of mining companies emerged. Some went bankrupt, such as CORZ; some transitioned very early, such as CoreWeave and Crusoe; the remainder stayed in Bitcoin mining and failed to achieve operating profitability. It can be said that more than 95% failed in their crypto businesses. This judgment of failure is not based on crypto prices not having risen “high enough,” but on operating fundamentals: their treasury and holding strategies violated basic principles of corporate operations, placing hope in massive uncertainty while neglecting operating cash flow and surviving on financing.
This unhealthy approach was carried forward by CoreWeave after its transition to AI. Relying on strong demand and supplier dominance, it continued to downplay financial risk and has now arrived at a situation of sharply rising financing costs and potential default pressure. Crusoe, which followed a similar path, is facing comparable pressures.
By contrast, Nebius and Lambda have much stronger foundations—at least in terms of corporate operating mindset—and do not exhibit major issues on that front. However, all of the above companies, including even the three hyperscale cloud providers, share a common problem: in the capital-intensive business of data centers, none of them possesses a vertically integrated business model. From the data center layer onward to the end of the value chain, varying degrees of partnership and outsourcing are required. Even for the three major cloud providers, pre-AI data centers primarily followed a hybrid model dominated by leasing, with ownership as a supplement.
After GPUs entered the Blackwell era, the data centers required by the industry effectively need to be rebuilt from the ground up. Although the three major cloud providers have substantial financial resources, they are still constrained by multiple real-world factors. Combined with large-enterprise inertia, aversion to heavy assets, and a long-standing preference for stability, their response in this area may not necessarily be fast enough to secure a decisive advantage.
Now I can introduce the central focus of this article: @IREN, the company that carries the core argument of this piece.
In the field of high-performance computing and next-generation data center infrastructure, @IREN exhibits several distinctive characteristics:
1.Accurate foresight about the future, coupled with strong execution
2.In-house expertise as data center specialists, including engineering design and construction
3.Experience accumulated as the only true winner in Bitcoin mining
4.Adherence to sound operating principles and a strong sense of risk management
5.Most importantly, it is currently the only company to have achieved vertical integration from land and power, through data centers, all the way to GPU chips
Based on these five characteristics, and in combination with the previously discussed elements of AI industry development, I will analyze whether @IREN is the best-prepared candidate to build high-end AI smart factories.
Foresight and Preparation
From the very beginning of its public listing, @IRENacquired a data center startup and assembled a team of professionals with extensive experience in infrastructure engineering and construction. The founding brothers possessed both financial structuring experience and a track record of successfully delivered infrastructure projects. Very early on, they foresaw a future in which explosive growth in digital-world demand would be mismatched with physical capacity. Acting on this vision, they began searching globally for ideal data center sites.
From site location, to required attributes, to high-end configurations—especially backbone network access, grid power availability, green energy, and massive land and power reserves—these requirements could only have come from a team with a clear vision of the future. Otherwise, it would be impossible to explain why the standards were so high, the scale so large, and why all assets were fully owned and built from greenfield sites. At the time, none of this made economic sense.
IREN went public as a Bitcoin miner, but Bitcoin mining simply does not require such high-end infrastructure or network configurations. Compared with many peers who housed mining rigs in rudimentary containers, this approach was like using a cannon to kill a mosquito. Bitcoin mining, therefore, was a transition and an experience-accumulation phase—a way to wait for the predicted digital-world explosion while gradually building high-performance computing infrastructure through real operations.
When the industry they had anticipated finally began to erupt, opportunities naturally favored those who were prepared. The fact that IREN’s Canadian data centers could be brought online with high-end GPUs after only low-cost modifications is the clearest proof. Saying that IREN “transformed from Bitcoin mining to AI” only captures the surface. The depth of preparation by the IREN team allowed even the three major hyperscale cloud providers to fall behind. This ability—to see the future—is the rarest and most valuable capability of all.
IREN’s foresight is also reflected in its data center design philosophy: optionality, diversity, adaptability, and the ability for different chips to operate collaboratively at the same site. When contrasted with the earlier-outlined contradiction between exponential GPU efficiency growth and mismatched physical infrastructure, this design philosophy is clearly aimed at addressing precisely that issue. There are many similar principles embedded in their designs, all of which reflect a deep understanding of the AI industry’s structural evolution.
True Data Center Experts
IREN’s core team consists of innovators and entrepreneurs in the data center field. Prior to joining IREN, they participated in the design and construction of multiple advanced data centers and had long collaborated with hyperscale enterprises. They possess a deep understanding of the past, present, and future of data center development, along with their own distinct innovations.
However, during the CPU-dominated era, many of their ideas were not adopted by the industry. Performance was “good enough,” and projects with massive capital expenditure were avoided whenever possible—even by hyperscalers. As a result, they went through a difficult period. Some team members left to work at hyperscale companies, only to quickly encounter their conservatism and large-enterprise inertia. This experience helped them see both the constraints and the vast opportunity space in the sector.
After the AI boom began, IREN—having accumulated long-term experience—earned trust and recognition during negotiations with hyperscale firms. In its collaboration with Microsoft, Microsoft’s assessment was direct: because we couldn’t do it ourselves.
IREN’s innovation and forward-looking configurations in data centers have always been the aspect I personally pay the most attention to. I come from an engineering background but was initially unfamiliar with data centers. Fortunately, today’s large models are excellent teachers. I spent more than a month fully understanding the technical level of the data centers designed and built by IREN. This cannot be fully presented here—it is simply too extensive. Investors in IREN should do this homework themselves to truly appreciate it.
In short: the future-oriented design and configuration of IREN’s data centers are extremely advanced. There is a qualitative difference between outputs produced by a team constantly innovating at the frontier of data center technology and those built by more traditional teams focused on maintaining the status quo.
Practice and Experience Accumulation
Bitcoin mining is not favored by Wall Street due to multiple uncertainties and therefore commands low valuations. Yet it is a classic high-performance computing business, and operating it well is extremely difficult. Among all Bitcoin miners, only IREN achieved sustained profitability with high margins.
This success was the result of a complex, systemic engineering effort. The core began years earlier with data center site selection: choosing grids that avoid competition with residential demand, securing peak-load interaction subsidies, sourcing sustainable green energy, and controlling costs across multiple stages.
Second—and most critical—was the precise planning of the compute growth path. Every upgrade in compute capacity was accurately positioned and delivered exactly as promised, without delays. Behind this lies orchestration capability, engineering experience, and the power of vertical integration working together.
Third was the ability to foresee the optimal efficiency curve, wait patiently, and then act decisively. Early on, IREN had little presence in Bitcoin hash rate rankings, which were dominated by three major miners. But when mining hardware efficiency reached a certain threshold, IREN suddenly accelerated. In just over a year, it became a major miner. Had it not redirected its focus entirely to AI, it would likely have become the industry leader. After becoming a major miner, IREN was also the only mining stock with the strongest profitability.
What impressed me most during this phase was IREN’s grasp of hardware efficiency. Once mining hardware efficiency and IREN’s comprehensive cost control reached the optimal curve, it acted immediately—and had the ability to execute flawlessly. Mining rigs are chips; GPUs are more complex, but the nature of efficiency improvement is the same. GPUs, too, will reach their optimal curve—the best input–output ratio.
I am convinced that the future Sweetwater megasite was designed with this in mind, and that similar preparations have already been made at the current Childress site.
Bitcoin mining not only provided IREN with strong operating cash flow; more importantly, it delivered irreplaceable hands-on experience in high-performance computing operations. IREN even records key operational parameters of its data centers on a daily basis. This has laid a solid foundation for future stability and energy-efficiency control in high-performance data center operations. This is the kind of work that is easy to talk about but extremely difficult to execute—and in this regard, IREN is unique globally.
As discussed earlier, GPU efficiency improvements converge on an optimal balance among efficiency, cost, and performance, and AI development advances under combined constraints of resources, energy, and rational returns. @IREN, having already validated this through Bitcoin mining with strong profitability, is likely unique in its awareness, experience, and execution capability. More importantly, identifying and capturing the optimal curve is a systemic endeavor—it cannot be done simply by “understanding” it intellectually. It requires long preparation, internal and external coordination, capital planning, and accurate judgment of when GPU chips reach their optimal point. The integrated difficulty is extremely high.
@brianfry01@FransBakker9812@jiahanjimliu@TheKamaHsutra
99.8% IREN at sub 8 average price. This is one of my you only get to do 5 trades in a lifetime stocks. Rest is leaps on Kraken robotics and Poet. Was a bit more diversified but with this drop to low 30's I rotated alot. Im very happy based on my own research to be this invested in IREN.
But to be fair I have a good amount of my wealth in real estate. So im already diversified in general assets.