#agentic systems have complex workflows, not just a single LLM call.
That’s why we built #Orla.
You define the workflow (e.g., with LangChain) and your providers (e.g. closed models, or your hosted models).
#Orla separates workflow management from prompt and query flows
We have some big news to share today.
Chutes is partnering with a research team from Harvard University to push the boundaries of AI inference efficiency.
The team at Harvard, led by Professor Juncheng Yang @1a1a11a, is developing a new prefix caching algorithm designed to significantly accelerate inference while reducing hardware usage.
if you missed it, we're running a research collab with Harvard right now
you can opt in and get 25% off your inference costs. all you have to do is switch your endpoint:
https://t.co/wGa4hYvmTm → https://t.co/SQZ09aZyR8
same models, same API, nothing else changes. you just pay less.
your data goes to Harvard's team to help build a caching algorithm that'll make inference faster and cheaper across the whole platform once it ships.
just know that your prompts and responses are recorded on this endpoint, so keep anything sensitive on https://t.co/wGa4hYvmTm like normal.
it's live now and already working.
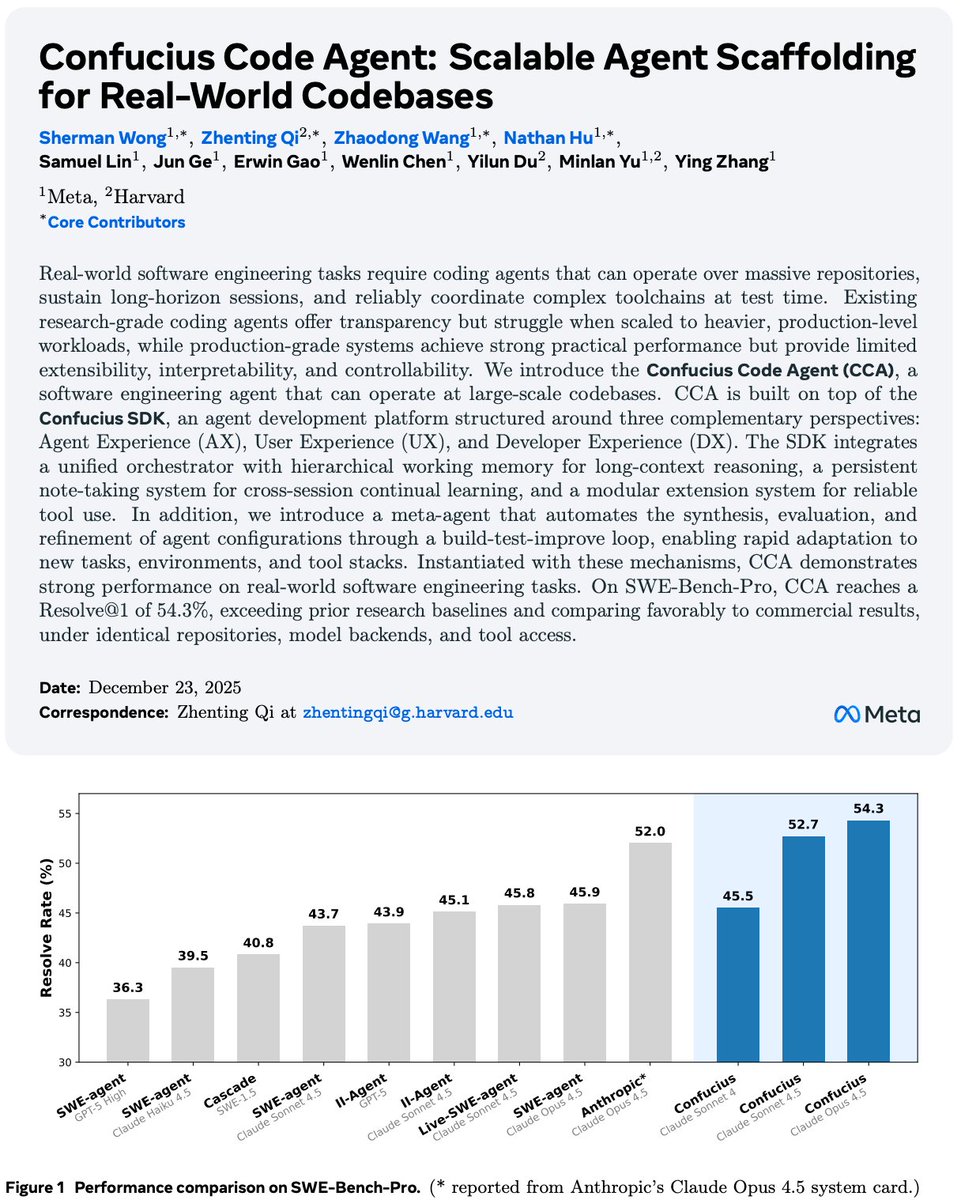
Agent scaffolding matters as much as, or even more than, raw model capability for hard agentic tasks.
In our latest research with @Meta, we show that carefully designed scaffolding achieve 54.3% (Claude Opus) and 52.7% (Claude Sonnet) on SWE-Bench-Pro, compared to a 52.0% Claude Opus' result under a proprietary scaffold @claudeai.
New paper at #Neurips2025
Compound AI systems don’t rely on a single model: they connect LLMs with tools, plugins, and APIs.
But this creates chaos:
- A “short” request can stall forever if the API is slow.
- A “long” request might finish fast if the tool answers instantly.
🚀 [OSDI ’25, Tue 11:10am]
How do you “divide and conquer” large-scale resource allocation problems like GPU cluster scheduling or WAN traffic engineering? Our answer: “decouple and decompose” the underlying optimization using DeDe. (1/3)
Congrats to Kai Li on being named a member of the American Academy of Arts & Sciences! 🎉
Li joined @Princeton in 1986 and has made important contributions to several research areas in computer science.
https://t.co/gYVjWnHX8J
We are presenting “Prefix and output length-aware scheduling for efficient online LLM inference” at the ICLR 2025 (@iclr_conf) Sparsity in LLMs workshop (@sparseLLMs).
🪫 Challenge: LLM inference in data centers benefits from data parallelism. How can we exploit patterns in requests – like shared prefixes and variable decode length – to optimally assign requests to GPU workers?
💡 Idea: both prefix and output length-aware scheduling!
We build on Preble (ICML 2025, @vikranth22446, @yiying__zhang), which was the first distributed LLM serving system to exploit prompt sharing (see https://t.co/BpHl8PbbfQ).
In our proof-of-concept work, we carefully benchmark Preble vs. prefix-unaware schedulers to identify opportunities for performance improvement.
⭐️ By adding output length-aware scheduling to Preble, we reduce latency by 14.31% at 64 RPS and 28.89% at 128 RPS. ⭐️
📖 Full paper here: https://t.co/1iW6hlfK7g
Thank you to co-authors @InakiArango, @YepHuang, @rana_shahout, and @minlanyu at @hseas. Thank you also to the Preble authors for their groundbreaking work!
For data center operators, this course will help explore scheduling strategies that would allow faster integration to the grid, as well as faster construction of data centers.
This course includes two parts: Power systems and AI data center systems. For data center device vendors, this course will help understand and increase the value of their design knobs for data centers in the energy market.
Excited to co-lead with @Le_Xie_Energy a new short course at Harvard @hseas on May 21: Power Systems and AI: An Introduction. We'll explore how AI + systems thinking can drive more sustainable, efficient datacenter and grid operations. Join us in Allston. https://t.co/v2DV6PGhJ6
Excited to co-lead with @Le_Xie_Energy a new short course at Harvard @hseas on May 21: Power Systems and AI: An Introduction. We'll explore how AI + systems thinking can drive more sustainable, efficient datacenter and grid operations. Join us in Allston. https://t.co/v2DV6PGhJ6
📢If your autonomous systems use OctoMap as the 3D mapping, stay tuned for OctoCache that accelerates OctoMap by up to 3.0× w/o GPU. It is developed by my student @Wilhelm_Chen and an awesome team minhao, zishen, yushun, w/@minlanyu, @profvjreddi, and will appear at ASPLOS'25!
New paper at #ICLR2025!
Fast LLM inference = smart scheduling 🕒 but size-based scheduling (prioritizing short requests over long ones) requires knowing request sizes—a challenging task in LLM systems. So, how can we predict request sizes accurately?
🔗https://t.co/VldoHSnozC)
It is graduate application season (and only one week due)! Come join me at UC Davis CS to research ML systems and networked systems, and enjoy the beautiful landscapes around the Davis campus (Lake Tahoe, Napa)! Know more at https://t.co/CaapdoF0lQ! @UCDavisCOE@ucdavis
"F3: Fast and Flexible Network Telemetry with an FPGA coprocessor" got into ACM CoNEXT! We show how an FPGA placed alongside the switching ASIC enables flexible network monitoring through partial reconfiguration! Work with folks at Harvard, Alibaba, UCL, Purdue and Meta.
Grace Liu, @yangzhouy, and I are co-chairing the SIGCOMM 2024 Artifact Evaluation. We are looking for PhD students, postdocs, and early-career researchers to join the committee! Underrepresented groups are strongly encouraged to apply.
- Application deadline: June 12, 2024 (AoE)
- Self-nomination form: https://t.co/dFFLZsj6DL



























![FrancisYan_'s tweet photo. 🚀 [OSDI ’25, Tue 11:10am]
How do you “divide and conquer” large-scale resource allocation problems like GPU cluster scheduling or WAN traffic engineering? Our answer: “decouple and decompose” the underlying optimization using DeDe. (1/3) https://t.co/OxNiWWA6R2](https://pbs.twimg.com/media/GvMfub0XYAASh7E.jpg)






















