In today's LLM serving, a single system handles requests with different demands. We built a multi-tier-SLO LLM serving system that treats Tensor Parallelism as a runtime knob instead of a fixed setting. Result: 5.3x better SLO-compliant goodput than SoTA.
🔥CAD: Efficient Long-context Language Model Training by Core Attention Disaggregation
Repo: https://t.co/QdNk8iXy6c
Blog: https://t.co/O5xRrl22UJ
Training a long-context LLM model can suffer from severe workload imbalance caused by core-attention - the softmax(QK^T)V part.
Core-attention disaggregation (CAD) fundamentally eliminates workload imbalance by disaggregating core-attention from the rest of the model.
🔥 New Blog: “Disaggregated Inference: 18 Months Later”
18 months in LLM inference feels like a new Moore’s Law cycle – but this time not just 2x per year:
💸 Serving cost ↓10–100x
🚀 Throughput ↑10x
⚡ Latency ↓5x
A big reason? Disaggregated Inference.
From DistServe, our early research system on prefill-decode disaggregation, to today’s production frameworks, disaggregation has become the backbone of modern LLM serving.
So what is disaggregated inference?
Why does the LLM inference community love it?
And how far have we come?
As the inventors of this technique, we take a look back – 18 months later - at how the idea reshaped the landscape and what comes next.
🔗 Read the full story: https://t.co/Kh7e6xq0Gx
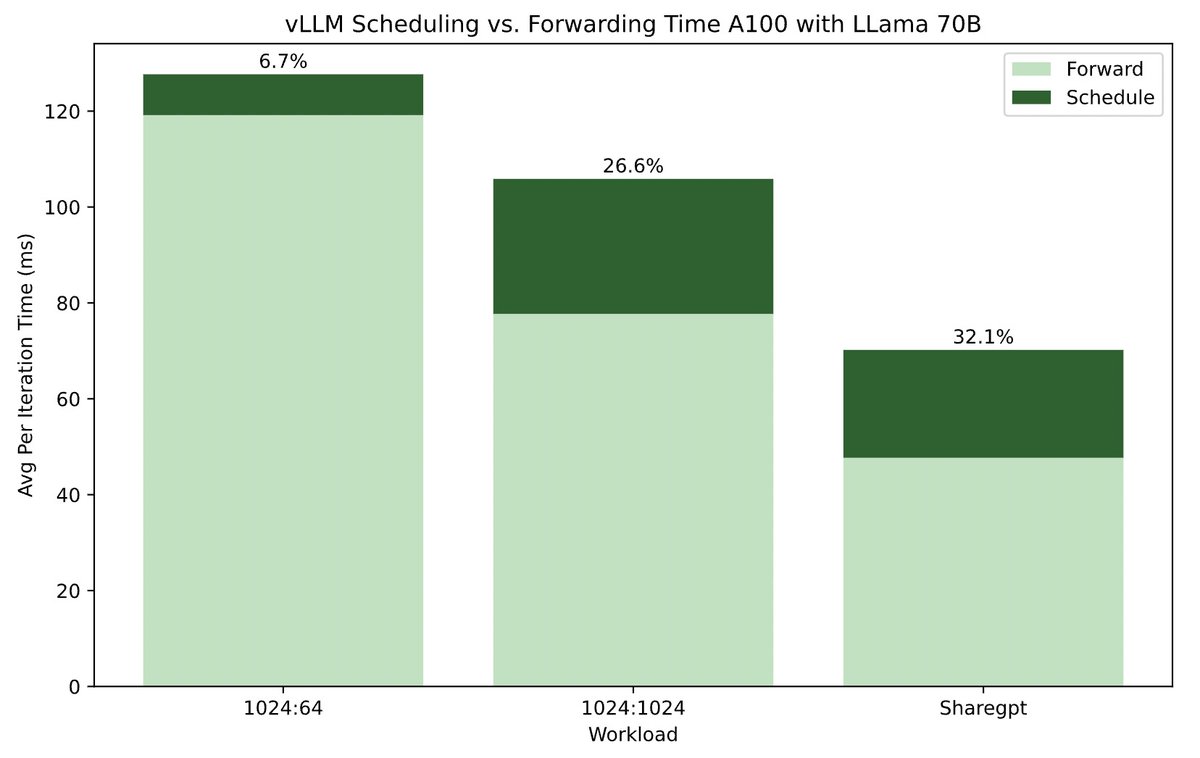
WukLab's new study reveals CPU scheduling overhead can dominate LLM inference time—up to 50% in systems like vLLM! Scheduling overhead can no longer be ignored as model forwarding speeds increase and more scheduling tasks get added.#LLM#vLLM#SGLang
Read https://t.co/6gVkdTZWkz
Today, LLMs are constantly being augmented with tools, agents, models, RAG, etc. We built InferCept [ICML'24], the first serving framework designed for augmented LLMs. InferCept sustains a 1.6x-2x higher serving load than SOTA LLM serving systems. #AugLLM
https://t.co/KvkRWAS7Z8
LLM prompts are getting longer and increasingly shared with agents, tools, documents, etc. We introduce Preble, the first distributed LLM serving system targeting long and shared prompts. Preble reduces latency by 1.5-14.5x over SOTA serving systems. #LLM
https://t.co/CNn3qIH7ui