The Amazon DSP gained more share in Q1 2026 than any other enterprise DSP, and continues to be the catalyst for @AmazonAds growth.
I had the pleasure of sharing why they've been so successful on the @MobileDevMemo podcast with @eric_seufert this week.
Give it a listen here 👇👇
https://t.co/JOOiBjtrUQ
Your phone isn’t secretly listening to you for ad targeting, part 2
Last month, the FTC fined Cox Media Group (CMG) and two other companies to settle allegations that the firms deceived customers about the utility of a marketing service sold by CMG, which claimed it could target ads based on conversations recorded by the microphones on consumers’ phones.
The FTC’s complaint is unequivocal: CMG’s claims about the efficacy of its Active Listening product were utterly fabricated.
https://t.co/IOLtb1pov9
Meta’s subscriptions and the advertising narrative blind spot
Public market investors understand subscription economics intuitively. They may be less fluent in AI-enabled advertising economics, which are harder to model, especially across the three axes I highlight in the Prosperous Society series. A recommendation-system improvement that lifts advertiser ROAS or user time spent by 3%, expands advertiser participation, and compounds into future auction density is much harder to conceptualize than a recurring monthly stream of consumer subscription revenue, despite potentially being worth orders of magnitude more.
Meta already has what other chatbot operators don’t: a high-performance advertising platform. Adopting subscriptions feels like a clumsy attempt to adapt to investor expectations rather than reshape them.
$META $SNAP
https://t.co/PKorqsXysC
Must listen interview for anyone thinking about consumer AI & Ads, and of course the upside for democratizing access to AI.
Lots of nuggets in there by @eric_seufert and @benthompson, great articulation of the principles and the direction.
As always, it was fantastic to join Ben Thompson on the @stratechery podcast. We discussed the generative revolution in digital advertising, Meta’s communications challenges, the evolution of Google Search, Apple, AppLovin, and the components of a Prosperous Society.
The generative RecSys revolution
The legacy two-stage approach to RecSys comprises retrieval and ranking, and is largely implemented by scaled platforms in two mechanisms: the “two towers” framework, proposed by Google in 2016, and the Deep Learning Ranking Model (DLRM), proposed by Meta in 2019.
But the modern generative retrieval framework reframes RecSys as a generation task rather than a scoring task: instead of retrieving and scoring a massive volume of potential candidate items for the best fit, the mechanism generates the next item’s semantic ID with a model. This concept might be instigating a fundamentally new paradigm in the RecSys and digital advertising ecosystem.
https://t.co/Swa9lJbScI
I'm happy to share some of the research that I've been working on today:
As ad platforms become more opaque and automated end-to-end, advertisers are left with few levers of control over campaign performance. I wanted to interrogate an idea: could advertisers treat "black box" platforms as teacher models and use a behavioral distillation process, focusing on multimodal creative and ad context, to predict ROAS performance for ad instances? And if so, what kind of model could best express the interactions between those features?
Most machine learning research focused on digital advertising is published by the largest platforms themselves. I wanted to address this asymmetry and explore what advertisers could build independently to improve performance within this increasingly automated environment.
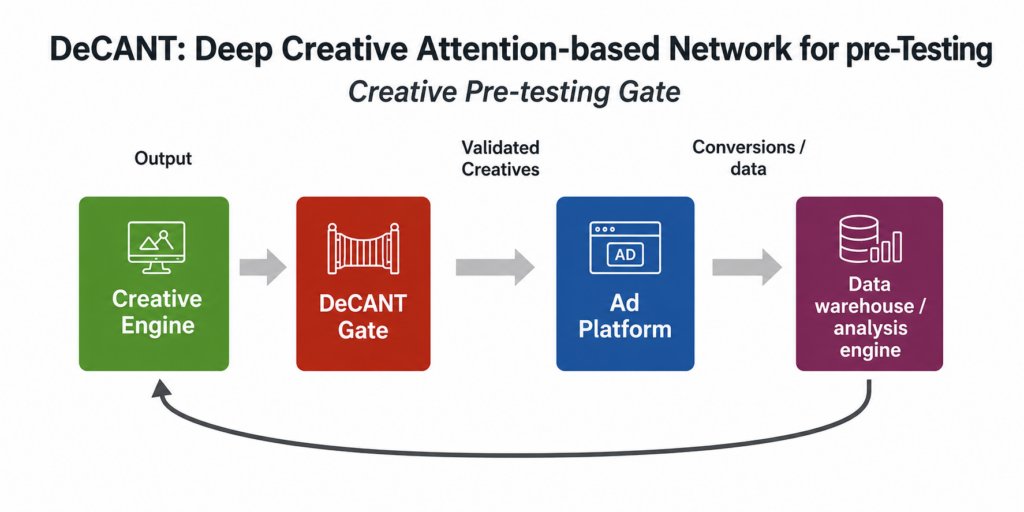
That idea ultimately became DeCANT: a Deep Creative Attention-based Network for pre-Testing. The model architecture uses self- and cross-attention to condition the semantic interpretation of a creative on the environment in which it is deployed. The model architecture supports multimodal ad creative and predicts ROAS on a context-conditioned basis.
Operationally, a model like DeCANT can fit into a pre-testing regime as an automated filter: creatives are produced through a generative pipeline, and the student model that learns the process for the given advertising channel is invoked on the proposed creative and context. The model produces an expected ROAS, which is compared against the advertiser's testing threshold to determine whether the creative is uploaded to the platform.
https://t.co/TgElrkFWwI
I wrote about this agency’s inflated claims, and why they allowed the misperception to persist that phones passively listen to conversations for the purposes of ad targeting, in September 2024, in a piece titled “Your phone isn’t secretly listening to you for ad targeting.”
Now the company has been fined by the FTC for misrepresenting its capabilities.
https://t.co/ReGedGd9v6
Google’s Gambit, Part 4: The end of Static Search
The commercial opportunity as Search converges to a hybrid chatbot interface is fairly obvious: more queries (demonstrable, from Google’s disclosure), more ad exposures per Search session (given the conversational nature of chatbot engagement), and more direct integrations into checkout.
And when the discovery and transaction interfaces converge into a single point of contact, retailers must not only compete for exposure but should, in theory, be willing to pay more for it, because the funnel compresses and the distance between discovery and the transaction shrinks.
https://t.co/9MxUQT7xOt
The Prosperous Society, Part 4: Per commercium virtus
In Episode 4, the conclusion to the series, I outline the AI-enabled flywheel to the Prosperous Society and make the case that it results in a more differentiated, more personalized, and economically expansive new digital economy:
AI increases productive possibility, and
Advertising increases matching precision, and
Matching precision increases specificity, and
Specificity increases expressive individuality, so
Society becomes more differentiated, not less.
But I also consider the existence of an acceptable boundary for this personalization. At what point do siloed, wholly unique digital experiences become corrosive to social cohesion? And how should that boundary inform the investments that are currently being made into AI infrastructure, such that they are put to the best possible use?
https://t.co/8krHVZf486
Amazon’s advertising advantages
To the extent that consumers detect the AI-generated nature of ads — or even care about the provenance of ads in the first place — through genericity or contextual irrelevance, Amazon is certainly well-positioned to mitigate that penalty through deterministic, impression-level personalization to a degree that few other platforms can match.
https://t.co/zHVT9vE8VC
Can causal value be learned jointly with auction mechanics in a first-price RTB setting?
A new paper from researchers at NYU and elsewhere argues that RTB bidding in first price auctions is fundamentally a causal inference problem, not simply an auction optimization problem. This is because advertisers only observe censored outcomes conditional on winning or losing, while the contextual signals used to value an impression are observed by all participants and correlated with market-clearing prices.
The paper is dense and entirely theoretical, but it proposes a novel idea: that in a first-price setting, advertisers can implement an online learning framework that jointly learns not just the incremental value of winning the impression but also the context-dependent (eg., device model, location) competitive dynamics that define the clearing price. This is done under three constraint regimes: no constraints, budget constriants, and ROAS (which they call it RoS) constraints.
The paper acknowledges that bidding policy impacts the data generation process: bidding conservatively vs. aggressively generates a vastly different distribution of observed data, resulting in endogeneity issues. As a result, exploration, pricing, pacing, and causal estimation combine into a joint optimization problem. This is exacerbated in a first-price setting because the clearing price is a noisy signal of competitor valuations and because a firm's own bid model is dictated by its historical dataset, which, circularly, is determined by its bid model.
To correct for this endogeneity, the authors model both impression value and competing bids as functions of the same contextual variables, then use inverse propensity weighting to debias outcome observations that are only revealed conditional on auction participation. The framework combines contextual bid-distribution estimation, weighted least squares, and primal-dual optimization to jointly learn causal value and bidding strategy under pacing and ROAS constraints.
Paper linked below.
AI-generated ads perform roughly as well as human-created ads, unless consumers suspect they were generated by AI.
Researchers from the Technical University of Munich, Columbia Business School, Harvard Business School, and elsewhere analyzed more than 16 billion ad impressions and 116 million clicks from Tabola. In a novel quasi-experiment, they compared the performance of AI-generated and human-generated "sibling ads": ads from the same campaigns, for the same products, and with the same launch dates.
They find that CTR performance for AI-generated ads is statistically "indistinguishable" from human-created ads when controlling for campaign-level factors. But they also reached an equally important conclusion: ads that look AI-generated perform worse.
The researchers identified a set of visual traits that consumers identify as "AI-like," and found that perceived artificiality reduced click-through rates even when the ads were not explicitly flagged as AI-generated. Ironically, the authors find that a not-insignificant number of human-generated ads were perceived as AI-generated for possessing those visual traits.
This is an important result. The cost of creative production through generative AI is decreasing rapidly, especially for static images. But not all AI-generated creative performs equivalently. Teams need to consider an optimization for their AI-enabled workflow beyond mere volume, which is the perceived visual fidelity and provenance of the ads being generated.
Link to paper below. Thanks to @garjoh_canuck for flagging this for me.
This podcast is the single most important meta advertising lesson I ever learnt.
I’ve found myself refer back to it dozens of times over the last year and have hounded colleagues to listen to it over and over again.
Components of AI-enabled advertising
From my perspective, AI-enabled advertising pertains to the AI-enriched mechanisms used to generate advertising creative and to serve it to users: in other words, how ads are created, how ad campaigns are managed and optimized, how ads are selected for a given user, and how conversions are optimized and measured.
They are sufficiently disparate in complexity and impact that it’s worth disentangling them for the sake of specificity.
https://t.co/nIKvvhGaiQ
Spotify, Roblox, and the conditions for a walled garden
Spotify revealed a noteworthy data point on its Q1 2026 earnings call two weeks ago: the company’s advertising platform, which contributed 8.5% of total revenue in Q1, now sees one-third of its advertising revenue generated from “biddable” media.
Spotify is a scaled platform with logged-in user state; why explicitly expand the amount of inventory sold programmatically rather than invest in platform-efficiency tools and data-aggregation technologies that unlock the value of a walled garden regime?
https://t.co/x5anodbmvb
Fantastic new (from April) paper from Kuaishou on GR4AD (Generative Recommendation for ADvertising). Kuaishou has made several important recent contributions to generative recommendation systems, particularly with its OneRec architecture. But GR4AD advances a more radical proposition: that the modern advertising stack should be rebuilt, end-to-end, around generative retrieval rather than simply retrofitting LLM-powered components into legacy DLRM systems.
GR4AD introduces both advertising-native semantic IDs (UA-SID) and advertising-native learning objectives in training and fine-tuning. The authors make the case that standard semantic IDs aren't fit for purpose in ad ranking, which requires information about business objectives like bid types, pacing, account information, etc. The authors fine-tune Qwen3-VL-7B to produce "Unified Advertisement Embeddings" which are then quantized into semantic IDs. This allows the idiosyncratic data that exists for ads to be better expressed than through the normal quantization process used in eg., TIGER for standard pieces of objective-invariant content.
As with other applications of generative RecSys, the UA-SIDs are inserted into the tokenizer, and a larger model is trained on user behavioral data to predict the ad t+1 that a user is likely to interact with. The benefit here is that ad selection is re-envisioned as an end-to-end generative, token-ahead prediction task versus a pairwise (user, ad) scoring task at the ranking stage as in traditional DLRM. GR4AD also introduces a ranking-aware RL scheme, Ranking-Guided Softmax Preference Optimization (RSPO), which optimizes list-level ranking objectives with NDCG-like weighting.
Generative retrieval is an exciting area of frontier research in RecSys. GR4AD is a production-scale, recommendation-native redesign of the entire ad retrieval/training/serving loop; it enables the representational capabilities of multimodal LLMs to be applied to ad ranking while also accommodating the peculiarities of ads that differentiate them from other types of content.
Paper linked in comments.