Xiaomi’s MiMo team released MiMo Code V0.1, an open-source AI coding agent for the terminal.
The tool comes with MiMo V2.5, a multimodal model available free for a limited time, with a million-token context window for large coding projects.
The system uses automatic knowledge accumulation and lossless compression to work across large codebases. Its agent framework is optimized for testing, review, validation, and one-pass task completion.
🚨 Pentagon just blacklisted 188 Chinese companies (inc'l Baidu & Alibaba) as “military” entities.
Evidence? Zero.
Meanwhile Lockheed Martin rakes in $44B in Pentagon contracts and gets called “free market.”
The hypocrisy is off the charts!
Watch the full breakdown ⬇️
You can now generate, edit, and convert a reference image into 3D inside one tool.
Tripo's Image Generation runs Nano Banana and GPT to build the reference, then turns it into a model. Text or photo in, 3D out.
One pipeline, zero handoffs.
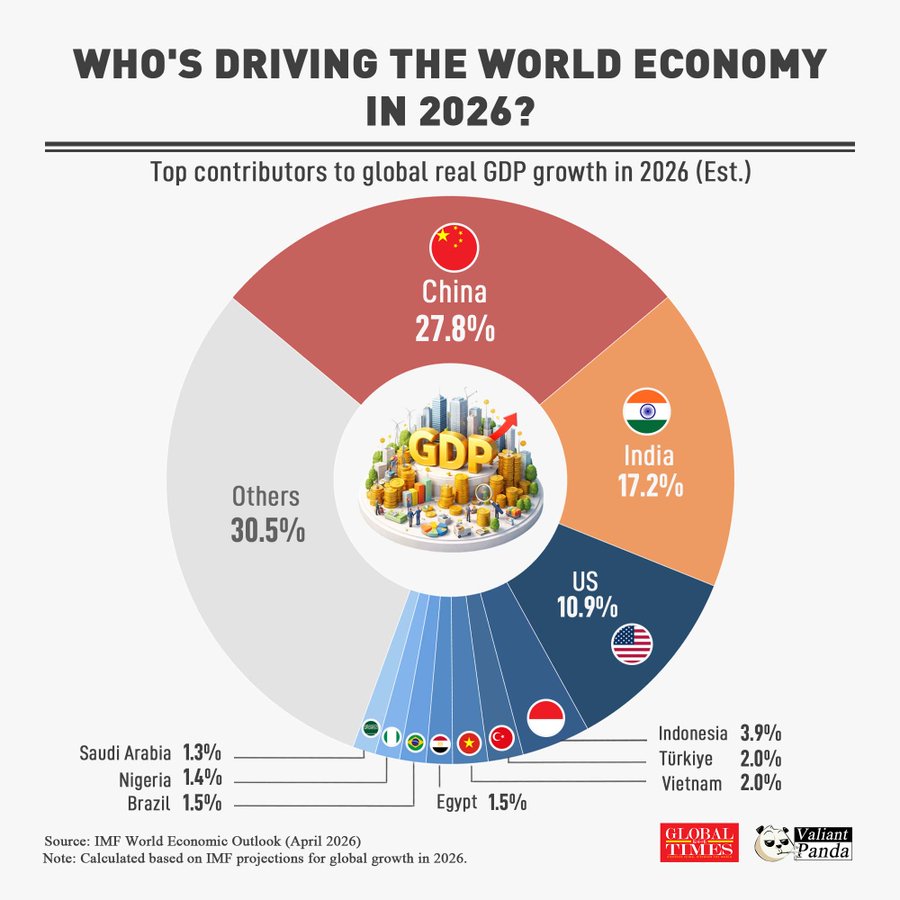
🚨🇨🇳🇮🇳 Asia’s Ascendancy Continues
IMF estimates suggest that China and India will contribute over 40% of global economic growth in 2026, underscoring a profound shift in the geography of prosperity.
🇨🇳 China: 27.8%
🇮🇳 India: 17.2%
🇺🇸 US: 10.9%
The statistics tell a larger story: the world’s economic dynamism is increasingly emanating from Asia, while the once-unquestioned dominance of the Atlantic economies continues its gradual attenuation.
We’re launching Gemma 4 12B: Our unified, encoder-free model that brings powerful multimodal intelligence straight to your laptop 🚀
The model bridges the gap between our mobile E4B model and larger 26B MoE models, packaging frontier-class reasoning and native audio into a highly optimized footprint, all under a permissive Apache 2.0 license.
Here’s what makes it unique:
+ Encoder-Less Architecture: We removed the multimodal encoders. The vision and audio inputs flow directly into the LLM backbone.
+ Agentic Performance (16GB VRAM): Run complex, multi-step workflows locally, with performance nearing our 26B model.
Today we’re introducing Gemma 4 12B — our latest open model that brings advanced agentic reasoning, vision and audio directly to your laptop.
It delivers performance nearing our larger Gemma models with a much smaller total memory footprint, while being small enough to run locally with just 16GB of VRAM. It’s open and accessible for everyone to use under a permissive Apache 2.0 license.
This is all made possible by our new, unified architecture that removes separate multimodal encoders. Here’s how we did it 🧵
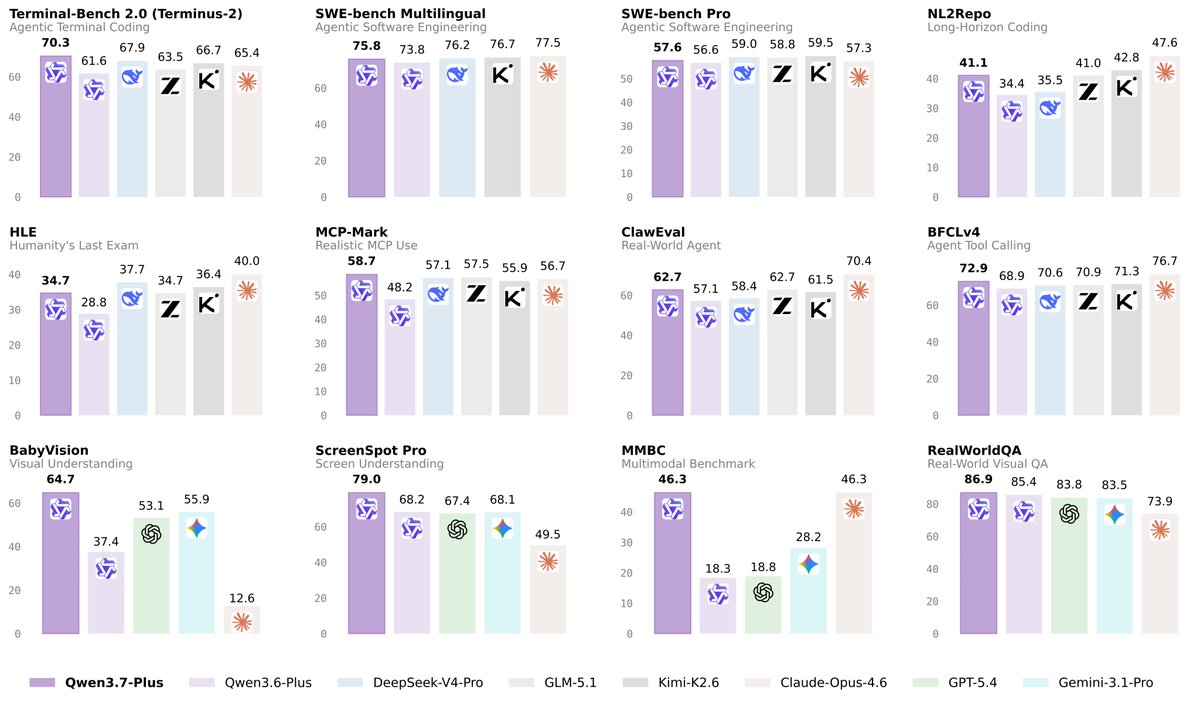
👏👏 Introducing Qwen3.7-Plus — a multimodal agent model that unifies vision and language into one versatile agent foundation.
✅ Multimodal interactive hybrid agent: unified GUI & CLI operation across visual and text tasks
✅ Versatile coding agent & productivity assistant with full-modality input
✅ Visual Agent: perception, reasoning, grounding, and search-augmented QA
✅ Cross-harness generalization across diverse agent frameworks
One model. Sees, thinks, codes, acts.🙌🙌
Now available via API on Alibaba Cloud Model Studio. Try it — let us know what you build.😎
🔗🔗⬇️⬇️
Blog:https://t.co/pVYf0h3NNa
Qwen Studio:https://t.co/HUYgFW4cYf
API:https://t.co/viL0cXrMzW
We made a guide on using MCP with local LLMs.
Connect Qwen3.6 and Gemma 4 for controlled access to tools, files, APIs, enabling private automated workflows.
Learn to use OAuth, Exa, Context7, Hugging Face & more.
Guide: https://t.co/bkgK1ikP9i
GitHub: https://t.co/aZWYAtakBP